インスタンス セグメンテーション
Computer Vision Toolbox™ のインスタンス セグメンテーション ツールを使用すると、複数のオブジェクトが重なり合っている場合でも、イメージ内の個々のオブジェクトを検出、分類、およびセグメント化できます。イメージ ラベラー アプリとビデオ ラベラー アプリを使用して、ラベル付きのグラウンド トゥルースを作成することから始められます。これらのアプリは、対話形式および AI アシストによる、多角形または矩形の ROI を使用したオブジェクト インスタンスの注釈付けをサポートしています。詳細については、Label Objects Using Polygons for Instance Segmentationを参照してください。
ツールボックスは、SOLOv2 や Mask R-CNN などの事前学習済みインスタンス セグメンテーション ネットワークを提供します。これらのモデルを推論に直接使用することも、転移学習を通じて特定の用途に合わせて調整することもできます。詳細については、Get Started with Instance Segmentation Using Deep LearningとGet Started with SOLOv2 for Instance Segmentationを参照してください。クラスに依存しないインスタンス セグメンテーションのために、ツールボックスは imsegsam 関数と segmentAnythingModel オブジェクトを通じて Segment Anything モデル (SAM) をサポートしています。
学習データの準備のために、ツールボックスには、データ セットの管理と整理、データ拡張、および前処理のためのユーティリティが用意されています。詳細については、Postprocess Exported Labels for Instance Segmentation Trainingを参照してください。
事前学習済みモデルまたはカスタム モデルを使用して予測を生成した後、インスタンス セグメンテーションのパフォーマンスを評価し、セグメンテーション精度、オブジェクトレベルの適合率、およびさまざまなオブジェクト サイズにわたるパフォーマンスについて、詳細な洞察を得ることができます。これらのメトリクスは、マスク予測と境界ボックス位置推定の両方の品質を評価するのに役立ちます。詳細については、evaluateInstanceSegmentation を参照してください。
ツールボックスは、Pose Mask R-CNN フレームワークを介したインスタンス セグメンテーションによる 3 次元オブジェクト姿勢推定もサポートしており、オブジェクトの向きや構造をきめ細かく解析することが可能です。詳細については、深層学習を使用したビン ピッキングの 6-DoF 姿勢推定の実行を参照してください。

関数
トピック
開始
- Get Started with Instance Segmentation Using Deep Learning
Segment objects using an instance segmentation model such as SOLOv2 or Mask R-CNN. - Get Started with SOLOv2 for Instance Segmentation
Perform multiclass instance segmentation using SOLOv2 and deep learning. - インスタンス セグメンテーションの Mask R-CNN 入門
Mask R-CNN と深層学習を使用してマルチクラス インスタンス セグメンテーションを実行する。 - Get Started with Segment Anything Model for Image Segmentation
Perform interactive image segmentation using Segment Anything Model 2 (SAM 2) and deep learning.
インスタンス セグメンテーション用のグラウンド トゥルースの作成
- Label Objects Using Polygons for Instance Segmentation
Label ground truth objects using polygons for instance segmentation. - Postprocess Exported Labels for Instance Segmentation Training
Postprocess exported ground truth labels and create training datastore for training instance segmentation networks such as SOLOv2 or Mask R-CNN.
インスタンス セグメンテーション用の学習データの準備
- Create Instance Segmentation Training Data From Ground Truth
This example shows how to create instance segmentation training data from agroundTruthobject. - 深層学習用イメージ前処理とイメージ拡張の入門
サイズ変更などの確定的演算を使用して深層学習アプリケーション用にデータを前処理する。あるいは、ランダム トリミングなどのランダム演算を使用して学習データを拡張する。 - 深層学習用のデータストア (Deep Learning Toolbox)
深層学習アプリケーションでデータストアを使用する方法を学びます。
注目の例
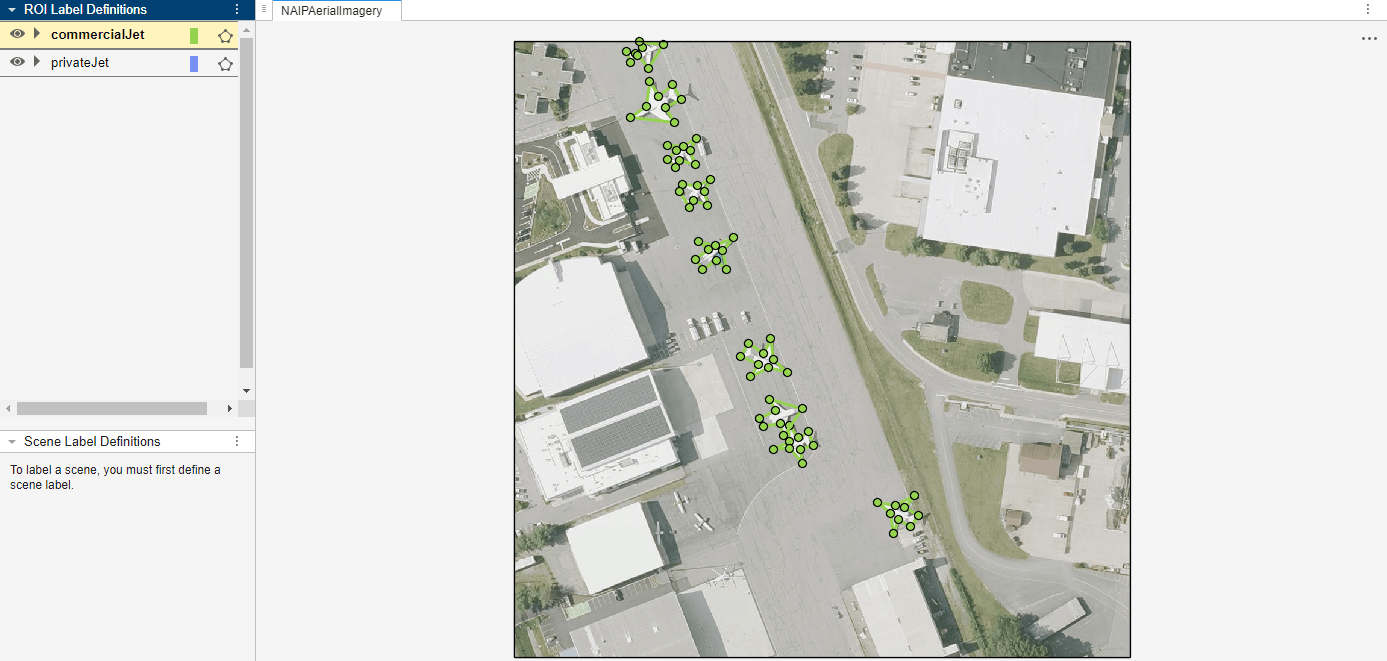
Automate Ground Truth Polygon Labeling Using Grounded SAM Model
Combine Grounding DINO and the Segment Anything Model 2 (SAM 2) to automatically produce polygon labels using the Video Labeler app.

Automate Ground Truth Labeling for Instance Segmentation
Create an automation algorithm to automatically label data for instance segmentation using a pretrained SOLOv2 network in the Video Labeler app.

Automatically Search and Label Video Frames Using VLMs
Automatically search and detect objects based on natural language text queries using vision-language models (VLMs).

SOLOv2 を使用したインスタンス セグメンテーションの実行
この例では、深層学習 SOLOv2 ネットワークを使用して、ビン内のランダムに回転する機械部品のオブジェクト インスタンスをセグメント化する方法を示します。

Mask R-CNN を使用したインスタンス セグメンテーションの実行
この例では、マルチクラスの Mask R-CNN (Region-based Convolutional Neural Network) を使用して、人と自動車の個々のインスタンスをセグメント化する方法を説明します。
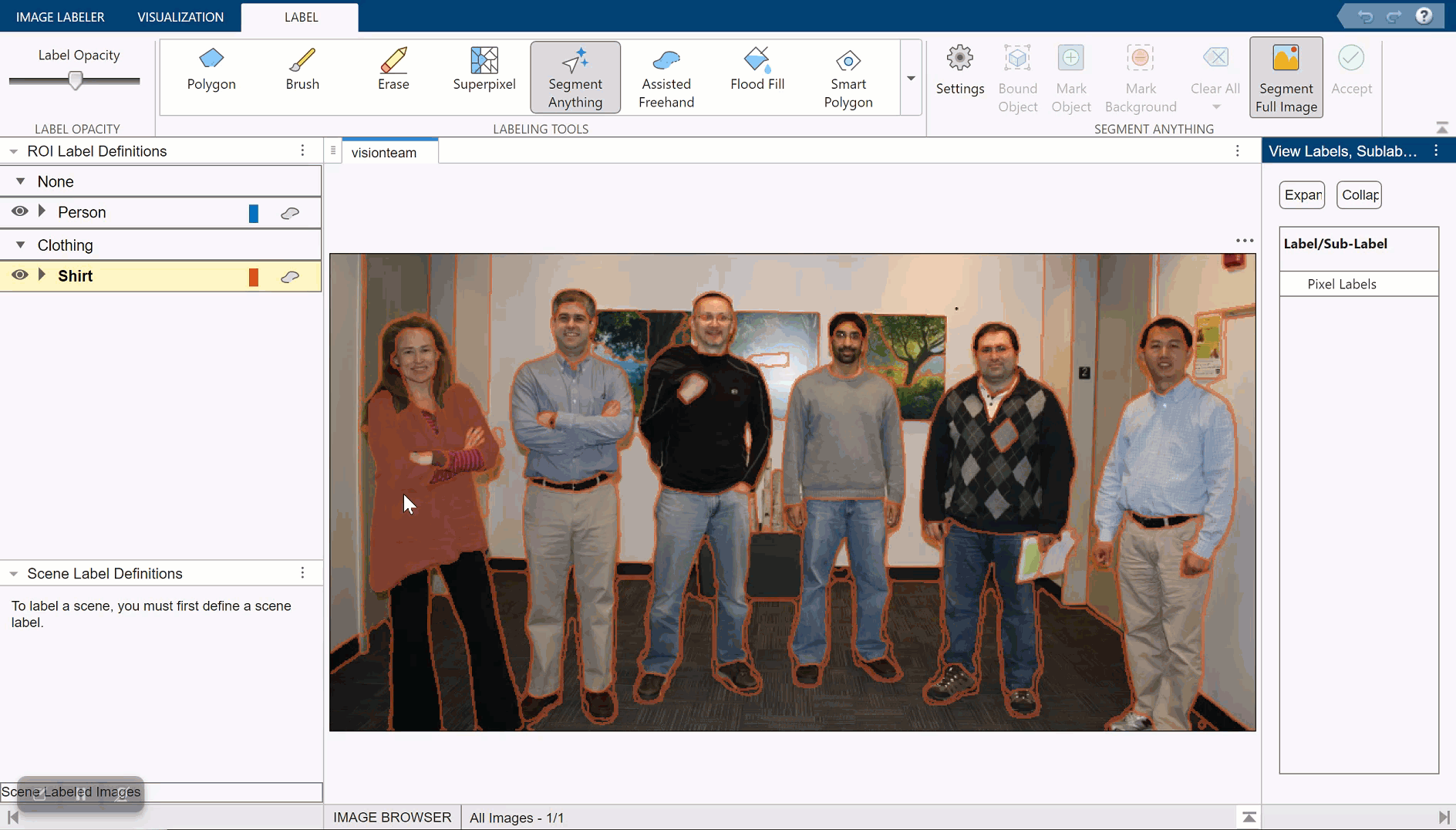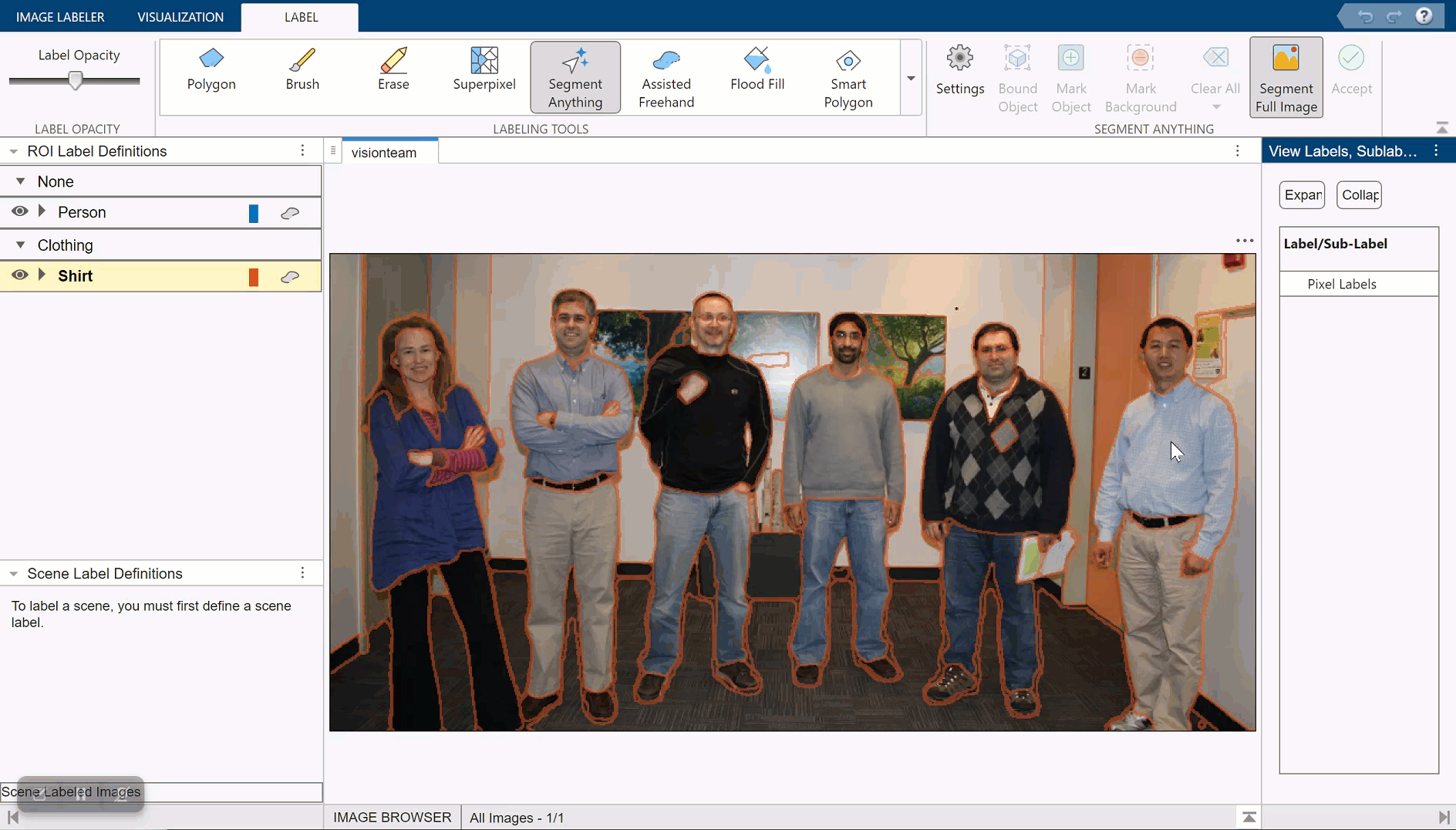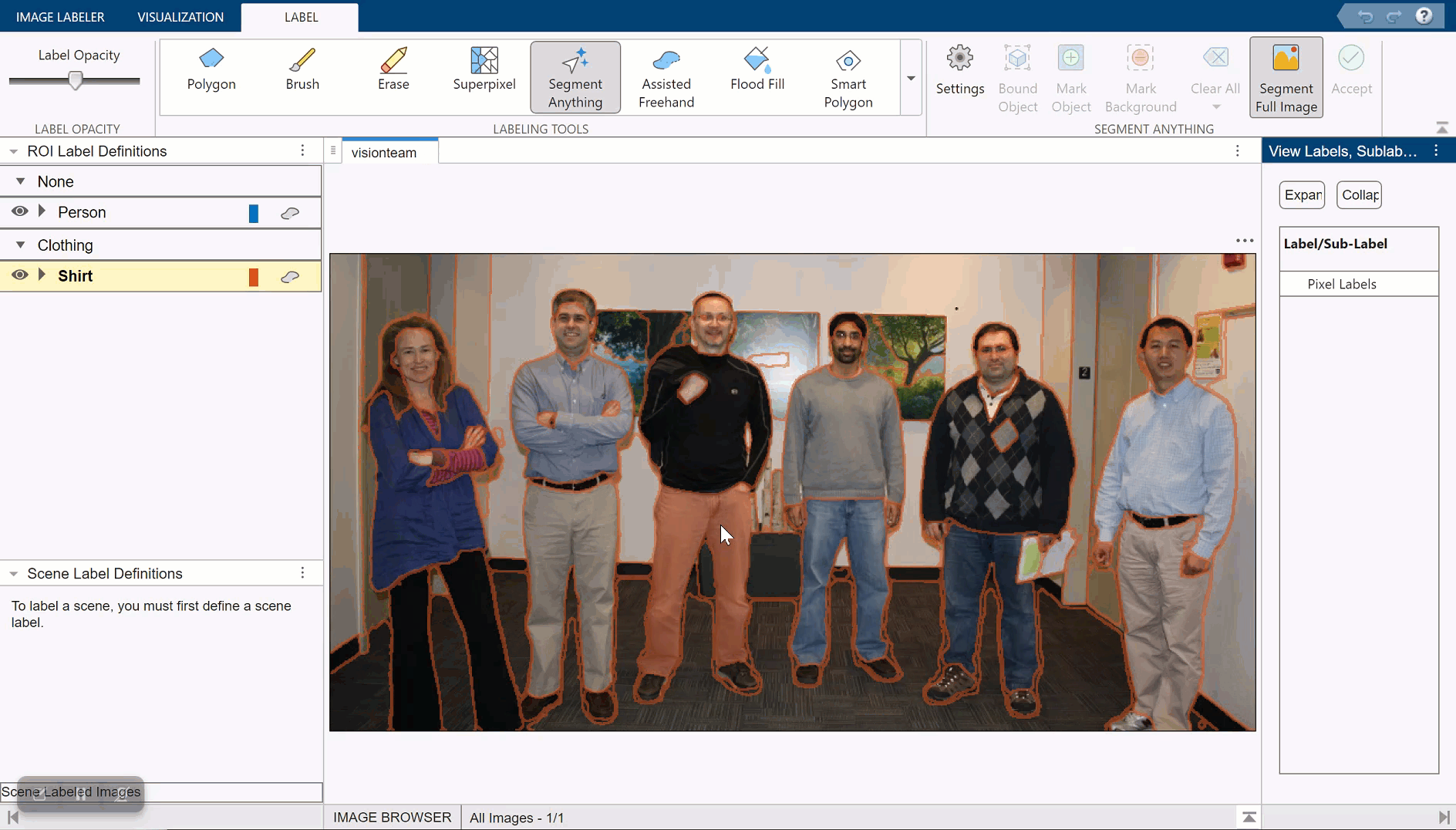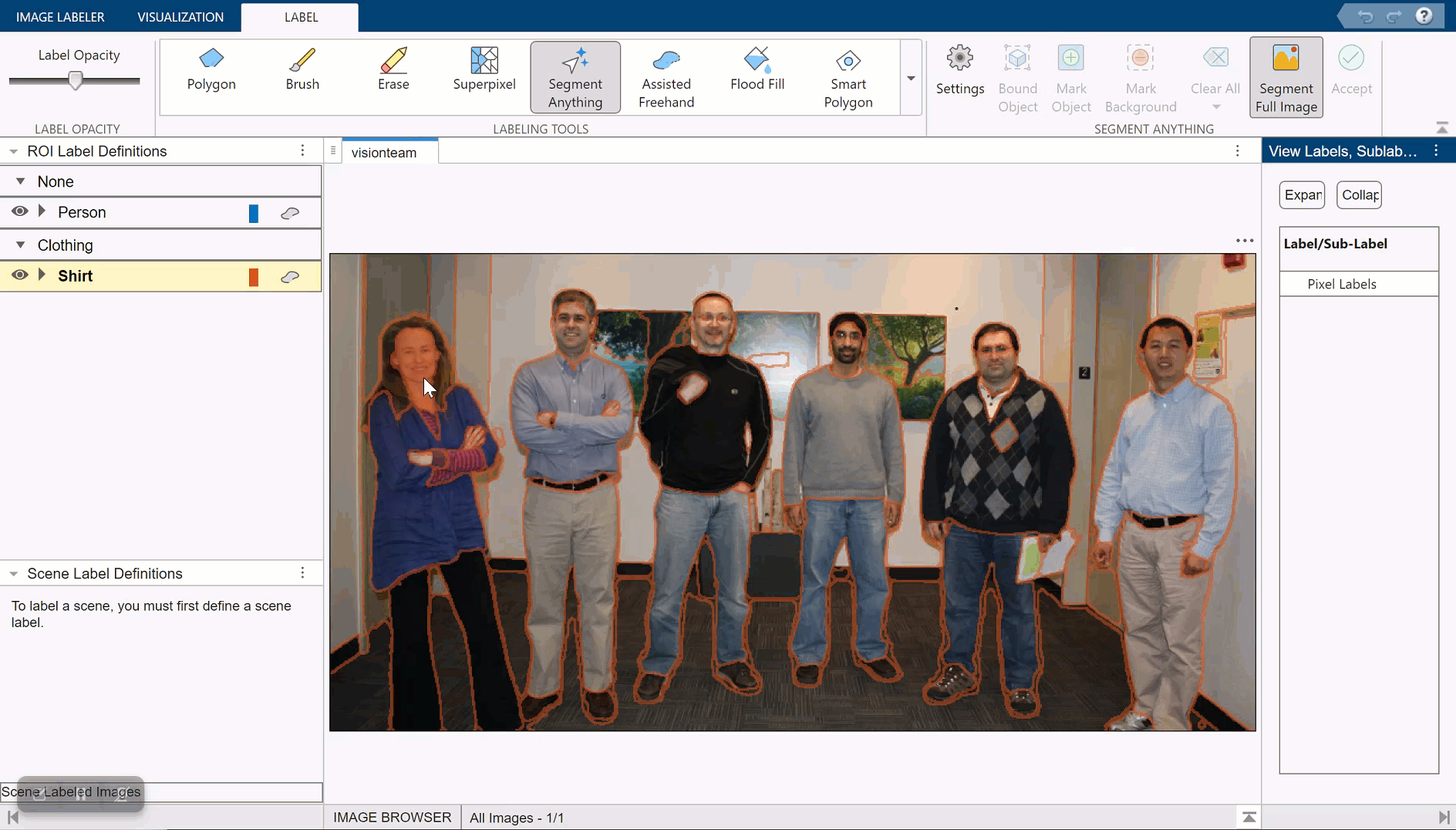
Automatically Label Ground Truth Using Segment Anything Model
Produce pixel labels for semantic segmentation using the Segment Anything Model (SAM) in the イメージ ラベラー app. The SAM is an automatic segmentation technique that you can use to segment object regions to label with just a few clicks, or automatically segment the entire image and instantaneously create labels for selected regions. In this example, you interactively label pixels for semantic segmentation in two ways.

Segment Objects in Interactive ROI Using Segment Anything Model
Perform interactive segmentation of an object in a selected region of interest (ROI) of an image using the Segment Anything Model (SAM).

深層学習を使用したビン ピッキングの 6-DoF 姿勢推定の実行
この例では、RGB-D イメージと深層学習ネットワークを使用して、ビン内の機械部品の 3 次元位置と向きを推定することにより、6 自由度 (6-DoF) の姿勢推定を実行する方法を示します。