パラメトリック近似
ライブラリ モデルによるパラメトリック近似
パラメトリック近似では、データの近似に使用する 1 つ以上のモデルの係数 (パラメーター) を求める必要があります。データは統計的性質をもっていると仮定し、次の 2 つの成分に分けます。
"データ" = "確定的な成分" + "ランダムな成分"
確定的な成分はパラメトリック モデルによって与えられ、ランダムな成分は多くの場合、データに関連する誤差として説明されます。
"データ" = "パラメトリック モデル" + "誤差"
モデルは、独立 (予測子) 変数と 1 つ以上の係数から成る関数です。誤差は、特定の確率分布 (通常はガウス分布) に従うデータのランダムな変動を表します。この変動は、さまざまなソースから生じる可能性があり、測定データを扱う場合はある程度必ず存在します。体系的な変動が存在する場合もあり、これが原因で、データを適切に表現できない近似モデルが得られる場合があります。
多くの場合、モデル係数には物理的な意味があります。たとえば、放射性核種の単独崩壊モードに対応するデータを収集し、崩壊の半減期 (T1/2) を推定する必要があるとします。放射性崩壊の法則によると、放射性物質の活性は時間と共に指数関数的に減衰します。したがって、近似に使用するモデルは次で与えられます
ここで、y0 は時刻 t = 0 における原子核の数、λ は崩壊定数です。データは次のように表すことができます。
y0 と λ はどちらも近似によって推定される係数です。T1/2 = ln(2)/λ であるため、崩壊定数の近似値から半減期の近似が得られます。ただし、データには誤差が含まれているため、方程式の確定的な成分はデータから正確には決定できません。そのため、係数と半減期の計算には、それらに関連する不確定性が存在します。この不確定性を許容できる場合、データの近似は終了です。不確定性を許容できない場合は、データを追加で収集するか測定誤差を減らして新しいデータを収集し、モデル近似を繰り返すことにより、不確定性を減らす手段を講じる必要があると考えられます。
モデルを決定する理論が存在しないその他の問題では、項を追加または削除してモデルを変更するか、まったく異なるモデルに置き換えることもできます。
以降のセクションでは、Curve Fitting Toolbox™ のパラメトリック ライブラリ モデルについて説明します。
モデル タイプの選択
モデル タイプの対話的な選択
MATLAB® コマンド ラインで curveFitter と入力して曲線フィッター アプリを開きます。または、[アプリ] タブの [数学、統計および最適化] グループで [曲線フィッター] をクリックします。
曲線フィッター アプリで、[曲線フィッター] タブの [近似タイプ] セクションに移動します。近似ギャラリーからモデル タイプを選択できます。矢印をクリックしてギャラリーを開きます。

次の表は、曲線および曲面に関して当てはめることができるモデルを説明しています。
| 近似グループ | 近似タイプ | 曲線 | 曲面 |
|---|---|---|---|
| 回帰モデル | 多項式 | あり (最大次数 9) | あり (最大次数 5) |
| 指数 | あり | なし | |
| 対数 | あり | なし | |
| フーリエ | あり | なし | |
| ガウス | あり | なし | |
| べき乗 | あり | なし | |
| 有理 | あり | なし | |
| 正弦波の和 | あり | なし | |
| ワイブル | あり | なし | |
| シグモイド | あり | なし | |
| 内挿 | 内挿 | あり (以下の手法を使用)
| あり (以下の手法を使用)
|
| 平滑化 | 平滑化スプライン | あり | なし |
| Lowess | なし | あり | |
| カスタム | カスタム式 | あり | あり |
| カスタム線形モデルの当てはめ | あり | なし |
[結果] ペインには、モデル仕様、係数の値、適合度の統計量が表示されます。
ヒント
近似に問題がある場合は、[結果] ペインのメッセージを参考に適切な設定を特定します。
曲線フィッター アプリにはさまざまな近似タイプと設定が用意されており、[近似オプション] ペインでそれらを変更して近似の改良を試みることができます。最初に既定の設定を試してから、その他の設定を試してください。利用可能な近似オプションを使用する方法の詳細については、係数の制約: 範囲と最適化された開始点の指定を参照してください。
1 つの近似に対してさまざまな設定を試したり、複数の近似を作成して比較したりできます。曲線フィッター アプリで複数の近似を作成すると、さまざまな近似タイプおよび設定を並べて比較できます。詳細については、曲線フィッター アプリにおける複数の近似の作成を参照してください。
モデル タイプのプログラムによる選択
関数 fit を呼び出すときに、ライブラリ モデル名を文字ベクトルまたは string スカラーとして指定できます。たとえば、次のように 2 次 poly2 モデルを指定できます。
f = fit(x,y,"poly2")利用可能なすべてのライブラリ モデル名を確認するには、曲線近似または曲面近似のライブラリ モデルのリストを参照してください。
関数 fittype を使用してライブラリ モデルの fittype オブジェクトを構築し、この fittype を関数 fit の入力として使用することもできます。
次のように関数 fitoptions を使用して、設定できるパラメーターを確認できます。
fitoptions(poly2)
例については、モデル タイプの対話的な選択の表にリストされている各モデル タイプのセクションを参照してください。モデルを作成および解析するすべての関数の詳細については、曲線近似および曲面近似を参照してください。
データのセンタリングとスケーリング
曲線フィッター アプリの近似の多くには、[近似オプション] ペインに [データのセンタリングとスケーリング] オプションが用意されています。このオプションを選択すると、センタリングおよびスケーリングされたデータにモデルが再度当てはめられます。
スケールの大きい変数の数値的な問題 (丸め誤差など) を緩和するには、入力データ ("予測子データ" とも呼ばれる) を正規化します。[データのセンタリングとスケーリング] を使用すると、すべての変数が同様に当てはめに寄与でき、数値的不安定性が緩和されるため、一般に当てはめが向上します。このオプションで入力を正規化すると、当てはめた係数の値も元のデータに比べて変化するため、係数が物理的な重要性をもつ場合 (地理的データの東距と北距など)、または係数を推定するために当てはめが行われる場合は、入力データを正規化しないでください。
曲線フィッター アプリのプロットでは、[データのセンタリングとスケーリング] の状態にかかわらず、元のスケールが使用されます。
コマンド ラインで当てはめの前にデータをセンタリングおよびスケーリングするには、Normalize="on" を指定して fit 関数を使用するか、fitoptions 関数を、options.Normalize を "on" に設定して使用し、options 構造体を作成します。その後、指定されたオプションで関数 fit を使用します。
options = fitoptions; options.Normalize = "on"; options options = basefitoptions with properties: Normalize: 'on' Exclude: [] Weights: [] Method: 'None' load census f1 = fit(cdate,pop,"poly3",options)
詳細オプション
曲線フィッター アプリ
曲線フィッター アプリでは、当てはめの詳細オプションを [近似オプション] ペインから対話的に指定できます。[内挿]、[平滑化スプライン]、および [局所回帰平滑化 (Lowess)] を除くすべての当てはめに、構成変更可能な当てはめの詳細オプションがあります。利用可能なオプションは、選択している近似 (線形近似か、非線形近似か、ノンパラメトリック近似か) によって異なります。
ノンパラメトリック近似 (つまり、[内挿] 近似、[平滑化スプライン] 近似、[局所回帰平滑化 (Lowess)] 近似) には [詳細オプション] はありません。
以下で説明しているオプションは、別途指定がない限り、非線形モデルにのみ利用可能なものです。
ここでは、単項 [指数] 近似の [近似オプション] ペインを示します。

コマンド ライン
既定の近似オプションの構造体を作成し、近似する前にデータをセンタリングおよびスケーリングするオプションを設定します。
options = fitoptions; options.Normalize = 'on'; options options = basefitoptions with properties: Normalize: 'on' Exclude: [] Weights: [] Method: 'None'
Normalize、Exclude または Weights フィールドを設定してから、さまざまな近似法で同じオプションを使用してデータを近似する場合、既定の近似オプションの構造体を変更すると便利です。以下に例を示します。
load census f1 = fit(cdate,pop,"poly3",options); f2 = fit(cdate,pop,"exp1",options); f3 = fit(cdate,pop,"cubicspline",options);
データ依存の近似オプションが関数 fit の 3 番目の出力引数として返されます。たとえば、平滑化スプラインの平滑化パラメーターはデータに依存します。
[f,gof,out] = fit(cdate,pop,"smoothingspline");
smoothparam = out.p
smoothparam =
0.0089近似オプションを使用して、新しい近似用に既定の平滑化パラメーターを変更できます。
options = fitoptions("Method","SmoothingSpline","SmoothingParam",0.0098); [f,gof,out] = fit(cdate,pop,"smoothingspline",options);
近似オプションの使用方法の詳細については、関数 fitoptions を参照してください。
係数の制約: 範囲と最適化された開始点の指定
係数の下限と上限を指定することで係数を制約し、係数の開始点を指定します。コマンド ラインでは、fit 関数または fitoptions 関数を使用して、Lower、Upper および StartPoint オプションを指定します。開始点は非線形の fittype に対してのみ指定できます。線形の fittype では開始点が不要なためです。既定の制約と最適化された開始点の詳細については、最適化された開始点と既定の制約を参照してください。

これらの近似オプションの詳細については、関数 lsqcurvefit (Optimization Toolbox) を参照してください。
最適化された開始点と既定の制約
[近似タイプ] ペイン内の近似について、既定の係数開始点および制約を次の表に示します。開始点が最適化される場合、開始点は現在のデータセットに基づいて経験則的に計算されます。ランダムな開始点は区間 [0 1] で定義され、線形モデルには開始点が必要ありません。モデルに制約がない場合、係数には下限も上限もありません。既定の開始点と制約をオーバーライドするには、[近似オプション] ペインで独自の値を指定します。
近似 | 開始点 | 制約 |
|---|---|---|
| 該当なし | なし |
| ランダム | なし |
| 最適化済み | なし |
対数 | 該当なし | なし |
| 最適化済み | なし |
| 最適化済み | ci > 0 |
| 該当なし | なし |
| 最適化済み | なし |
| ランダム | なし |
| 最適化済み | bi > 0 |
| ランダム | a, b > 0 |
シグモイド ([モデル] を [4 パラメーター ロジスティック] として指定) | 最適化済み | x/c > 0 |
[正弦波の和] 近似および [フーリエ] 近似は開始点の影響を特に受けやすく、また、最適化された値が対応する方程式の少数の項についてしか正確ではない場合があることに注意してください。
当てはめで考慮する制約点 (Optimization Toolbox が必要)
曲線フィッター アプリで、またはコマンド ラインで名前と値の引数 ConstraintPoints を使用して制約点を追加することで、回帰 fittype が特定の点を通過するように制約します。ノンパラメトリックな当てはめ (つまり、[内挿]、[平滑化スプライン]、[局所回帰平滑化 (Lowess)] の当てはめ) は制約点を受け入れません。

制約点を使用すると、原点、1 つ以上のデータ点、または任意の座標を考慮して曲線または曲面の当てはめを行うことができます。
制約点の数は、fittype の係数の数より大きくすることはできません。たとえば、1 次多項式
の当てはめは、最大 2 つの制約点を使用して行うことができます。
制約の許容誤差は、[TolCon] を設定して指定できます。これは、指定した制約点と当てはめた点を通過する実際の点との間の数値差の絶対値の上限です。これを超えると制約違反になります。
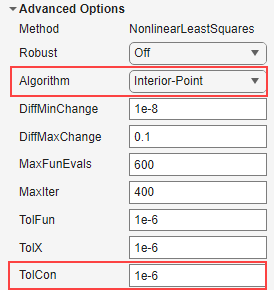
制約点を非線形の fittype に対して指定する場合、つまり [メソッド] が
NonlinearLeastSquaresの場合、近似アルゴリズムはInterior-Pointにする必要があります。
ヒント
制約違反が原因の警告をデバッグするには、コマンド ラインで名前と値の引数 Display を "iter" に設定して、制約点を使用したワークフローを繰り返します。