fit
曲線または曲面によるデータへの近似
構文
説明
fitobject = fit(x,y,fitType,Name=Value)fitType と、1 つ以上の Name=Value ペア引数で指定された追加オプションを使用してデータの近似を作成します。fitoptions を使用すると、特定のライブラリ モデルの使用可能なプロパティ名と既定の値を表示できます。
例
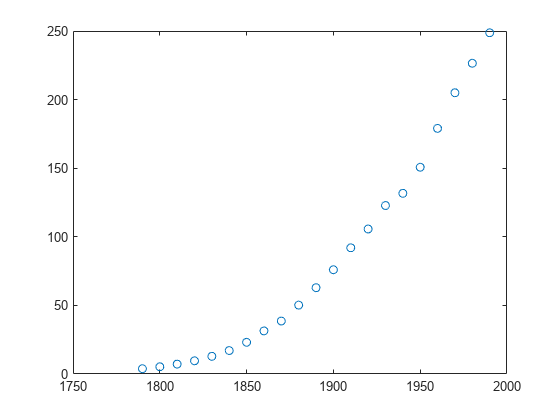
census サンプル データ セットを読み込みます。
load census;ベクトル pop と cdate には、人口サイズと国勢調査の実施年に関するデータがそれぞれ含まれています。
人口データに 2 次曲線を当てはめます。
f=fit(cdate,pop,'poly2')f =
Linear model Poly2:
f(x) = p1*x^2 + p2*x + p3
Coefficients (with 95% confidence bounds):
p1 = 0.006541 (0.006124, 0.006958)
p2 = -23.51 (-25.09, -21.93)
p3 = 2.113e+04 (1.964e+04, 2.262e+04)
f に 95% 信頼限界の係数推定値を含む近似の結果が格納されます。
f の近似をデータの散布図と一緒にプロットします。
plot(f,cdate,pop)

プロットは、近似曲線が人口データに密接に追従していることを示しています。
franke サンプル データ セットを読み込みます。
load frankeベクトル x、y、および z には、フランケの二変量テスト関数から生成され、ノイズとスケーリングが追加されたデータが格納されています。
データに多項式曲面を当てはめます。x の項の次数を 2、y の項の次数を 3 と指定します。
sf = fit([x, y],z,'poly23')sf =
Linear model Poly23:
sf(x,y) = p00 + p10*x + p01*y + p20*x^2 + p11*x*y + p02*y^2 + p21*x^2*y
+ p12*x*y^2 + p03*y^3
Coefficients (with 95% confidence bounds):
p00 = 1.118 (0.9149, 1.321)
p10 = -0.0002941 (-0.000502, -8.623e-05)
p01 = 1.533 (0.7032, 2.364)
p20 = -1.966e-08 (-7.084e-08, 3.152e-08)
p11 = 0.0003427 (-0.0001009, 0.0007863)
p02 = -6.951 (-8.421, -5.481)
p21 = 9.563e-08 (6.276e-09, 1.85e-07)
p12 = -0.0004401 (-0.0007082, -0.0001721)
p03 = 4.999 (4.082, 5.917)
sf に 95% 信頼限界の係数推定値を含む近似の結果が格納されます。
sf の近似をデータの散布図と一緒にプロットします。
plot(sf,[x,y],z)

データを読み込んでプロットし、関数 fittype および fitoptions を使用して近似オプションと近似タイプを作成してから、近似を作成してプロットします。
census.mat のデータを読み込んでプロットします。
load census plot(cdate,pop,'o')
カスタム非線形モデル について近似オプション オブジェクトと近似タイプを作成します。ここで、a と b は係数、n は問題依存のパラメーターです。
fo = fitoptions('Method','NonlinearLeastSquares',... 'Lower',[0,0],... 'Upper',[Inf,max(cdate)],... 'StartPoint',[1 1]); ft = fittype('a*(x-b)^n','problem','n','options',fo);
近似オプションと n = 2 の値を使用して、データに当てはめます。
[curve2,gof2] = fit(cdate,pop,ft,'problem',2)curve2 =
General model:
curve2(x) = a*(x-b)^n
Coefficients (with 95% confidence bounds):
a = 0.006092 (0.005743, 0.006441)
b = 1789 (1784, 1793)
Problem parameters:
n = 2
gof2 = struct with fields:
sse: 246.1543
rsquare: 0.9980
dfe: 19
adjrsquare: 0.9979
rmse: 3.5994
近似オプションと n = 3 の値を使用して、データに当てはめます。
[curve3,gof3] = fit(cdate,pop,ft,'problem',3)curve3 =
General model:
curve3(x) = a*(x-b)^n
Coefficients (with 95% confidence bounds):
a = 1.359e-05 (1.245e-05, 1.474e-05)
b = 1725 (1718, 1731)
Problem parameters:
n = 3
gof3 = struct with fields:
sse: 232.0058
rsquare: 0.9981
dfe: 19
adjrsquare: 0.9980
rmse: 3.4944
近似結果をデータと共にプロットします。
hold on plot(curve2,'m') plot(curve3,'c') legend('Data','n=2','n=3') hold off

carbon12alpha 核反応サンプル データセットを読み込みます。
load carbon12alphaangle は、放出角度 (ラジアン単位) のベクトルです。counts は、angle 内の角度に対応する生のアルファ粒子数のベクトルです。
角度に対してプロットされた粒子数の散布図を表示します。
scatter(angle,counts)

散布図は、粒子数が、角度の増加に合わせて、0 と 4.5 の間で振動していることを示しています。多項式モデルをデータに当てはめるため、fitType 入力引数に "poly#" を指定します。ここで、# は 1 から 9 の任意の整数です。最大 9 次のモデルを当てはめられます。詳細については、曲線近似または曲面近似のライブラリ モデルのリストを参照してください。
5 次、7 次、9 次の多項式を核反応データに当てはめます。近似ごとに、適合度の統計量を返します。
[f5,gof5] = fit(angle,counts,"poly5"); [f7,gof7] = fit(angle,counts,"poly7"); [f9,gof9] = fit(angle,counts,"poly9");
関数linspaceを使用して、0 と 4.5 の間のクエリ点のベクトルを生成します。クエリ点で多項式近似を評価し、それを核反応データと一緒にプロットします。
xq = linspace(0,4.5,1000); figure hold on scatter(angle,counts,"k") plot(xq,f5(xq)) plot(xq,f7(xq)) plot(xq,f9(xq)) ylim([-100,550]) legend("original data","fifth-degree polynomial","seventh-degree polynomial","ninth-degree polynomial")

プロットは、9 次多項式が最も密接にデータに追従していることを示しています。
関数struct2tableを使用して、近似ごとに適合度の統計量を表示します。
gof = struct2table([gof5 gof7 gof9],RowNames=["f5" "f7" "f9"])
gof=3×5 table
sse rsquare dfe adjrsquare rmse
__________ _______ ___ __________ ______
f5 1.0901e+05 0.54614 18 0.42007 77.82
f7 32695 0.86387 16 0.80431 45.204
f9 3660.2 0.98476 14 0.97496 16.169
9 次多項式近似の二乗和誤差 (SSE) は、5 次および 7 次の近似の SSE より小さくなっています。この結果から、9 次多項式が最も密接にデータに追従していることが確認されます。
census サンプル データ セットを読み込みます。3 次多項式を当てはめ、Normalize (センタリングとスケーリング) と Robust の近似オプションを指定します。
load census; f = fit(cdate,pop,'poly3','Normalize','on','Robust','Bisquare')
f =
Linear model Poly3:
f(x) = p1*x^3 + p2*x^2 + p3*x + p4
where x is normalized by mean 1890 and std 62.05
Coefficients (with 95% confidence bounds):
p1 = -0.4619 (-1.895, 0.9707)
p2 = 25.01 (23.79, 26.22)
p3 = 77.03 (74.37, 79.7)
p4 = 62.81 (61.26, 64.37)
近似をプロットします。
plot(f,cdate,pop)

指数関数的トレンドのデータを生成し、単項指数関数を使用してそのデータを近似します。近似とデータをプロットします。
rng(2,"twister"); x = (0:0.2:10)'; y = 2*exp(0.2*x) + 0.2*randn(size(x)); % Without constraints fitresult1 = fit(x,y,"exp1"); plot(fitresult1,x,y); hold on

2 番目のデータ点を制約として使用して新しい指数曲線を当てはめます。非線形の fittype であるため、制約点を使用した当てはめを行うには Algorithm を "Interior-Point" として指定する必要があります。指定しない場合、"Interior-Point" アルゴリズムを使用するように内部で切り替わります。
% With constraints point = [x(2) y(2)]; fitresult2 = fit(x,y,"exp1",ConstraintPoints=point,Algorithm="Interior-Point"); plot(fitresult2); plot(point(:,1),point(:,2),"*"); legend("Data","Without Constraints","With Constraints", ... "Constraint Point",Location="best");

ファイルに関数を定義し、それを使用して近似タイプを作成し曲線で近似します。
関数を MATLAB® ファイルに定義します。
type piecewiseLine.mfunction y = piecewiseLine(x,a,b,c,k)
% PIECEWISELINE A line made of two pieces
y = zeros(size(x));
% This example includes a for-loop and if statement
% purely for example purposes.
for i = 1:length(x)
if x(i) < k
y(i) = a + b.*x(i);
else
y(i) = a + b*k + c.*(x(i)-k);
end
end
end
ファイルを保存します。
データをいくつか定義し、関数 piecewiseLine を指定して近似タイプを作成します。
x = [0.81;0.91;0.13;0.91;0.63;0.098;0.28;0.55;... 0.96;0.96;0.16;0.97;0.96]; y = [0.17;0.12;0.16;0.0035;0.37;0.082;0.34;0.56;... 0.15;-0.046;0.17;-0.091;-0.071]; ft = fittype('piecewiseLine( x, a, b, c, k )')
ft =
General model:
ft(a,b,c,k,x) = piecewiseLine( x, a, b, c, k )
ft への入力は、係数をアルファベット順に並べ、その後に独立変数を指定します。詳細については、無名関数の入力順序を参照してください。
係数の順序を制御する場合は、無名関数の入力を使用します。たとえば、係数 a と b の順序を変更するには次のようにします。
ft = fittype(@(b,a,c,k,x) piecewiseLine(x,a,b,c,k))
独立変数 x は最後に指定する必要があります。
近似タイプ ft を使用して近似を作成し、結果をプロットします。
f = fit(x, y, ft, 'StartPoint', [1, 0, 1, 0.5]);
plot(f, x, y)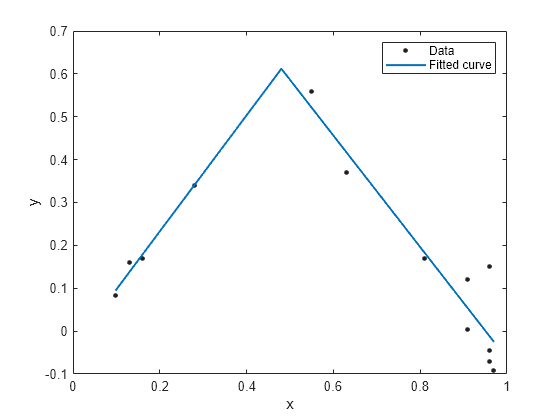
除外する点を関数 fit への入力として指定する前に、それらの点を変数として定義できます。以下の手順では、前述の例の近似を再作成し、除外した点をデータと近似と共にプロットします。
データを読み込み、カスタム式と開始点を定義します。
[x, y] = titanium;
gaussEqn = 'a*exp(-((x-b)/c)^2)+d'gaussEqn = 'a*exp(-((x-b)/c)^2)+d'
startPoints = [1.5 900 10 0.6]
startPoints = 1×4
1.5000 900.0000 10.0000 0.6000
インデックス ベクトルと式を使用して、除外する 2 組の点を定義します。
exclude1 = [1 10 25]; exclude2 = x < 800;
カスタム式、開始点および 2 組の異なる除外点を使用して 2 つの近似を作成します。
f1 = fit(x',y',gaussEqn,'Start', startPoints, 'Exclude', exclude1); f2 = fit(x',y',gaussEqn,'Start', startPoints, 'Exclude', exclude2);
両方の近似をプロットし、除外したデータを強調表示します。
plot(f1,x,y,exclude1)
title('Fit with data points 1, 10, and 25 excluded')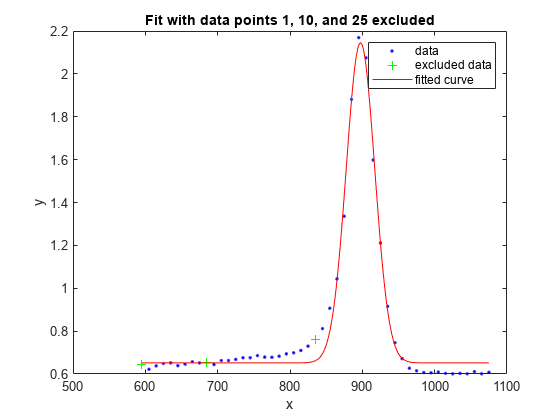
figure;
plot(f2,x,y,exclude2)
title('Fit with data points excluded such that x < 800')
除外点を使用する曲面近似の例として、曲面データを読み込み、除外するデータを指定して近似を作成しプロットします。
load franke f1 = fit([x y],z,'poly23', 'Exclude', [1 10 25]); f2 = fit([x y],z,'poly23', 'Exclude', z > 1); figure plot(f1, [x y], z, 'Exclude', [1 10 25]); title('Fit with data points 1, 10, and 25 excluded')

figure plot(f2, [x y], z, 'Exclude', z > 1); title('Fit with data points excluded such that z > 1')

関数 membrane とrandnを使用してノイズを含むデータを生成します。
n = 41; M = membrane(1,20)+0.02*randn(n); [X,Y] = meshgrid(1:n);
行列 M には、ノイズを追加した L 型膜のデータが格納されています。行列 X と Y には、M 内の対応する要素の行と列のインデックス値がそれぞれ格納されています。
データの表面プロットを表示します。
figure(1) surf(X,Y,M)

プロットは、しわのある L 型膜を示します。膜内のしわは、データ内のノイズが原因で生じています。
線形内挿を使用して、2 つの曲面をしわのある膜に当てはめます。最初の曲面には、線形外挿法を指定します。2 番目の曲面には、外挿法として最近傍を指定します。
flinextrap = fit([X(:),Y(:)],M(:),"linearinterp",ExtrapolationMethod="linear"); fnearextrap = fit([X(:),Y(:)],M(:),"linearinterp",ExtrapolationMethod="nearest");
関数meshgridを使用して X と Y のデータの凸包の外側に拡張しているクエリ点で近似を評価し、外挿法の違いを調べます。
[Xq,Yq] = meshgrid(-10:50); Zlin = flinextrap(Xq,Yq); Znear = fnearextrap(Xq,Yq);
評価された近似をプロットします。
figure(2) surf(Xq,Yq,Zlin) title("Linear Extrapolation") xlabel("X") ylabel("Y") zlabel("M")

figure(3) surf(Xq,Yq,Znear) title("Nearest Neighbor Extrapolation") xlabel("X") ylabel("Y") zlabel("M")

線形外挿法は、凸包の外側にスパイクを生成します。スパイクを形成している平面セグメントは、凸包の境界上の点での勾配に従います。最近傍外挿法は、境界上のデータを使って各方向に曲面を拡張します。この外挿法は、境界を再現する波形を生成します。
平滑化スプライン曲線を当てはめ、適合度の統計量と近似アルゴリズムに関する情報を返します。
enso サンプル データ セットを読み込みます。enso サンプル データ セットには、イースター島とオーストラリアのダーウィンの月間平均大気圧の差に関するデータが含まれています。
load enso;month と pressure のデータに平滑化スプライン曲線を当てはめ、適合度の統計量と output 構造体を返します。
[curve,gof,output] = fit(month,pressure,"smoothingspline");当てはめた曲線を、曲線の当てはめに使用したデータと共にプロットします。
plot(curve,month,pressure); xlabel("Month"); ylabel("Pressure");

x データ (month) に対する残差をプロットします。
plot(curve,month,pressure,"residuals") xlabel("Month") ylabel("Residuals")

output 構造体の residuals のデータを使用して、y データ (pressure) に対する残差をプロットします。output の residuals フィールドにアクセスするには、ドット表記を使用します。
residuals = output.residuals; plot( pressure,residuals,".") xlabel("Pressure") ylabel("Residuals")

無名関数を使用すると、他のデータを関数 fit に簡単に渡せます。
データを読み込み、無名関数を定義する前に Emax を 1 に設定します。
data = importdata( 'OpioidHypnoticSynergy.txt' );
Propofol = data.data(:,1);
Remifentanil = data.data(:,2);
Algometry = data.data(:,3);
Emax = 1;モデル方程式を無名関数として定義します。
Effect = @(IC50A, IC50B, alpha, n, x, y) ... Emax*( x/IC50A + y/IC50B + alpha*( x/IC50A )... .* ( y/IC50B ) ).^n ./(( x/IC50A + y/IC50B + ... alpha*( x/IC50A ) .* ( y/IC50B ) ).^n + 1);
無名関数 Effect を関数 fit への入力として使用し、結果をプロットします。
AlgometryEffect = fit( [Propofol, Remifentanil], Algometry, Effect, ... 'StartPoint', [2, 10, 1, 0.8], ... 'Lower', [-Inf, -Inf, -5, -Inf], ... 'Robust', 'LAR' ) plot( AlgometryEffect, [Propofol, Remifentanil], Algometry )
無名関数の使用例と他の近似用カスタム モデルの詳細については、関数 fittype を参照してください。
プロパティ Upper、Lower、StartPoint については、係数のエントリ順序を確認する必要があります。
近似タイプを作成します。
ft = fittype('b*x^2+c*x+a');関数 coeffnames を使用して係数名と順序を取得します。
coeffnames(ft)
ans = 3×1 cell
{'a'}
{'b'}
{'c'}
これは、fittype を使用して ft を作成するときに使用する式の係数の順序とは異なることに注意してください。
データを読み込み、近似を作成し、開始点を設定します。
load enso fit(month,pressure,ft,'StartPoint',[1,3,5])
ans =
General model:
ans(x) = b*x^2+c*x+a
Coefficients (with 95% confidence bounds):
a = 10.94 (9.362, 12.52)
b = 0.0001677 (-7.985e-05, 0.0004153)
c = -0.0224 (-0.06559, 0.02079)
これにより、a = 1、b = 3、c = 5 のように、係数に初期値が代入されます。
または、近似オプションを取得し、開始点と下限を設定してから、新しいオプションを使用して再近似することもできます。
options = fitoptions(ft)
options =
nlsqoptions with properties:
StartPoint: []
Algorithm: 'Trust-Region'
DiffMinChange: 1.0000e-08
DiffMaxChange: 0.1000
Display: 'Notify'
MaxFunEvals: 600
MaxIter: 400
TolFun: 1.0000e-06
TolX: 1.0000e-06
Lower: []
Upper: []
ConstraintPoints: []
TolCon: 1.0000e-06
Robust: 'Off'
Normalize: 'off'
Exclude: []
Weights: []
Method: 'NonlinearLeastSquares'
options.StartPoint = [10 1 3]; options.Lower = [0 -Inf 0]; fit(month,pressure,ft,options)
ans =
General model:
ans(x) = b*x^2+c*x+a
Coefficients (with 95% confidence bounds):
a = 10.23 (9.448, 11.01)
b = 4.335e-05 (-1.82e-05, 0.0001049)
c = 5.523e-12 (fixed at bound)