指数モデルの当てはめ
指数モデルについて
このツールボックスでは、次で与えられる 1 項および 2 項の指数モデルが用意されています
指数関数は、多くの場合、ある量の変化率がその量の初期量に比例するときに使用されます。b または d に関連する係数が負の場合、y は指数関数的減衰を表します。この係数が正の場合、y は指数関数的増加を表します。
たとえば、核種の 1 つの放射性崩壊モードは、1 項の指数関数で記述されます。a は核種の初期数と解釈され、b は崩壊定数、x は時間、y は特定の時間が経過した後の残りの核種数です。2 つの崩壊モードが存在する場合は、2 項指数モデルを使用しなければなりません。2 番目の崩壊モードのために、もう 1 つの指数項をモデルに追加します。
指数関数的増加の例には、治療法がない伝染病や、捕食や環境要因などにより増加が抑制されていない生物学的個体群があります。
指数モデルによる対話的な近似
MATLAB® コマンド ラインで
curveFitterと入力して曲線フィッター アプリを開きます。または、[アプリ] タブの [数学、統計および最適化] グループで [曲線フィッター] をクリックします。曲線フィッター アプリで、曲線データを選択します。[曲線フィッター] タブの [データ] セクションで [データの選択] をクリックします。[近似データの選択] ダイアログ ボックスで、[X データ] および [Y データ] を選択するか、インデックスに対する [Y データ] のみを選択します。
[近似タイプ] セクションの矢印をクリックしてギャラリーを開き、[回帰モデル] グループの [指数] をクリックします。
ここでは、単項 [指数] 近似の [近似オプション] ペインを示します。

[近似オプション] ペインで、次のオプションを指定できます。
exp1で近似する場合は項数として 1、exp2の場合は 2 を選択します。[結果] ペインを参照し、モデル項、係数の値、適合度の統計量を確認します。必要に応じて [詳細オプション] セクション内で、データに適した係数の開始値と制約範囲を指定するか、アルゴリズム設定を変更します。ここで示す係数の開始値と制約は、
censusデータのものです。データセットに基づいて、[指数] 近似の最適化された開始点が計算されます。開始点をオーバーライドして、[近似オプション] ペインで独自の値を指定することができます。データに適した開始値を指定する例については、指数関数的背景のあるガウス近似を参照してください。

設定の詳細については、係数の制約: 範囲と最適化された開始点の指定を参照してください。
関数 fit による指数モデル近似
この例では、関数 fit を使用して指数モデルをデータに当てはめる方法を示します。
指数ライブラリ モデルは、関数 fit および fittype の入力引数です。モデル タイプ 'exp1' または 'exp2' を指定します。
単項指数モデルによる近似
指数関数的トレンドのデータを生成し、単項指数関数を使用してそのデータを近似します。近似とデータをプロットします。
x = (0:0.2:5)';
y = 2*exp(-0.2*x) + 0.1*randn(size(x));
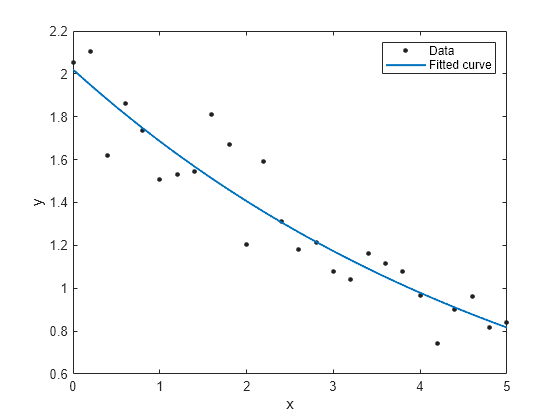
f = fit(x,y,'exp1')f =
General model Exp1:
f(x) = a*exp(b*x)
Coefficients (with 95% confidence bounds):
a = 2.021 (1.89, 2.151)
b = -0.1812 (-0.2104, -0.152)
plot(f,x,y)
2 項指数モデルによる近似
f2 = fit(x,y,'exp2')f2 =
General model Exp2:
f2(x) = a*exp(b*x) + c*exp(d*x)
Coefficients (with 95% confidence bounds):
a = 384.8 (-4.78e+09, 4.78e+09)
b = -0.2572 (-2939, 2938)
c = -382.8 (-4.78e+09, 4.78e+09)
d = -0.2577 (-2957, 2957)
plot(f2,x,y)

開始点の設定
現在のデータセットに基づいて指数近似の最適化された開始点が計算されます。開始点をオーバーライドして、独自の値を指定することができます。
関数 coeffnames を使用して 1 番目のモデル (f) の係数のエントリ順序を確認します。
coeffnames(f)
ans = 2×1 cell
{'a'}
{'b'}
開始点を指定する場合、データに適した値を選択します。例として、係数 a および b に任意の開始点を設定します。
f = fit(x,y,'exp1','StartPoint',[1,2])
f =
General model Exp1:
f(x) = a*exp(b*x)
Coefficients (with 95% confidence bounds):
a = 2.021 (1.89, 2.151)
b = -0.1812 (-0.2104, -0.152)
plot(f,x,y)

指数近似オプションの確認
係数の開始値や制約範囲などの近似オプションをデータに合わせて変更したり、アルゴリズム設定を変更したりする場合は、近似オプションを確認します。これらのオプションの詳細については、fitoptions のリファレンス ページにある NonlinearLeastSquares のプロパティの表を参照してください。
fitoptions('exp1')ans =
nlsqoptions with properties:
StartPoint: []
Algorithm: 'Trust-Region'
DiffMinChange: 1.0000e-08
DiffMaxChange: 0.1000
Display: 'Notify'
MaxFunEvals: 600
MaxIter: 400
TolFun: 1.0000e-06
TolX: 1.0000e-06
Lower: []
Upper: []
ConstraintPoints: []
TolCon: 1.0000e-06
Robust: 'Off'
Normalize: 'off'
Exclude: []
Weights: []
Method: 'NonlinearLeastSquares'
参考
アプリ
関数
fit|fittype|fitoptions