線形回帰
データの準備
回帰の当てはめを開始するには、データを近似関数に望ましい形式にします。すべての回帰手法は、配列 X の入力データと独立したベクトル y の応答データか、table tbl 内の入力データと tbl の列としての応答データで始まります。入力データの各行が、1 つの観測値を表します。各列が 1 つの予測子 (変数) を表します。
table tbl では、次のように 'ResponseVar' の名前と値のペアで応答変数を示します。
mdl = fitlm(tbl,'ResponseVar','BloodPressure');
応答変数は既定で最後の列です。
数値の "カテゴリカル" 予測子を使用できます。カテゴリカル予測子は可能性のある固定セットからの値をとります。
数値配列
Xでは、'Categorical'の名前と値のペアでカテゴリカル予測子を示します。たとえば、6 つの予測子から2と3が categorical であることを示すには、次のようにします。mdl = fitlm(X,y,'Categorical',[2,3]); % or equivalently mdl = fitlm(X,y,'Categorical',logical([0 1 1 0 0 0]));
table
tblでは、近似関数はこれらのデータ型が categorical であることを想定しています。logical ベクトル
categorical ベクトル
文字配列
string 配列
数値予測値が categorical であることを示すには、
'Categorical'名前と値のペアを使用します。
欠損数値データは NaN で表されています。他のデータ型用の欠損データを表すには、グループ化変数の欠損値を参照してください。
入力および応答データの table
Excel® スプレッドシートから table を作成するには、次のようにします。
tbl = readtable('hospital.xls', ... 'ReadRowNames',true);
ワークスペース変数から table を作成するには、次のようにします。
load carsmall
tbl = table(MPG,Weight);
tbl.Year = categorical(Model_Year);入力データの数値配列、応答の数値ベクトル
たとえば、ワークスペース変数から数値配列を作成するには、次のようにします。
load carsmall
X = [Weight Horsepower Cylinders Model_Year];
y = MPG;Excel スプレッドシートから数値配列を作成するには、次のようにします。
[X, Xnames] = xlsread('hospital.xls'); y = X(:,4); % response y is systolic pressure X(:,4) = []; % remove y from the X matrix
sex などの数値以外のエントリは X には表示されません。
近似手法の選択
モデルをデータに当てはめるには、以下の 3 つの方法があります。
最小二乗近似
fitlm を使用して、モデルのデータへの最小二乗近似を作成します。この方法は、モデルの型を十分に把握し、パラメーターを見つけることが主な目的である場合に最適です。いくつかのモデルを試す場合にも便利です。最小二乗近似を使う場合、外れ値を破棄するためにデータを手動で調べなければなりませんが、このタスクに役立つ方法もあります (品質の調査と当てはめたモデルの調整を参照)。
ロバスト近似
外れ値にほとんど影響されないモデルを作成するには、fitlm を RobustOpts 名前と値のペアと併用します。ロバスト近似は、外れ値を手動で破棄する手間が省けます。ただし、ロバスト近似では step が使えません。そのため、ロバスト近似を使用する場合、適正なモデルでステップワイズを検索できません。
ステップワイズ近似
モデルを検索し、パラメーターをそのモデルに当てはめるには、stepwiselm を使用します。stepwiselm は、定数などの 1 つのモデルから開始し、一度に 1 つずつ項を増減する貪欲法で、それ以上改良できなくなるまで、最適な項を毎回選択します。ステップワイズ近似を使用して、有効な項のみを含む適正なモデルを見つけます。
この結果は、開始モデルに依存します。通常、定数モデルで開始すると、小さいモデルになります。さらに多くの項で開始すると、複雑なモデルになりますが、平均二乗誤差はより小さくなります。大小のステップワイズ モデルの比較を参照してください。
ロバスト オプションはステップワイズ近似では使用できません。ステップワイズ近似の実行後に、モデルで外れ値を探してください (品質の調査と当てはめたモデルの調整を参照)。
単一モデルまたはモデル範囲の選択
線形回帰のモデルを指定する方法はいくつかあります。最も便利だと思う方法を使用してください。
fitlm で指定するのは近似のモデルです。モデル仕様を指定しない場合の既定値は 'linear' です。
stepwiselm では、指定するモデルの仕様は、ステップワイズ手順で改善を試みる最初のモデルです。モデルの仕様を指定しない場合の既定の最初のモデルは 'constant' で、既定の上限モデルは 'interactions' です。上限のモデルを変更するには、Upper 名前と値のペアを使用します。
メモ
関数 lasso、lassoglm、sequentialfs、plsregress などを使用するモデルの選択方法もあります。
省略名
| 名前 | モデル タイプ |
|---|---|
'constant' | モデルは定数 (切片) 項だけを含みます。 |
'linear' | モデルは各予測子に対して切片と線形項を含みます。 |
'interactions' | モデルは、切片、線形項、異なる予測子のペアのすべての積 (二乗項なし) を含みます。 |
'purequadratic' | モデルは、切片、線形項、二乗項を含みます。 |
'quadratic' | モデルは、切片、線形項、交互作用、二乗項を含みます。 |
'poly | モデルは多項式であり、最初の予測子は次数 i まで、2 番目の予測子は次数 j まで、3 番目以降も同様です。0 から 9 までの数値を使用します。たとえば、'poly2111' には、1 つの定数のほかにすべての線形項と積項があり、また、予測子 1 の二乗の項を含んでいます。 |
たとえば、行列予測子をもつ fitlm を使って交互作用モデルを指定するには、次のようにします。
mdl = fitlm(X,y,'interactions');stepwiselm と予測子の table tbl を使ってモデルを指定するには、1 つの定数から始め、線形モデル上限があると想定します。tbl 内の応答変数が 3 番目の列にあるとします。
mdl2 = stepwiselm(tbl,'constant', ... 'Upper','linear','ResponseVar',3);
項の行列
"項行列" T は、モデル内の項を指定する t 行 (p + 1) 列の行列です。ここで、t は項の数、p は予測子変数の数であり、+1 は応答変数に相当します。T(i,j) の値は、項 i の変数 j の指数です。
たとえば、3 つの予測子変数 x1、x2、x3 と応答変数 y が x1、x2、x3、y という順序で入力に含まれていると仮定します。T の各行は 1 つの項を表します。
[0 0 0 0]— 定数項 (切片)[0 1 0 0]—x2(x1^0 * x2^1 * x3^0と等価)[1 0 1 0]—x1*x3[2 0 0 0]—x1^2[0 1 2 0]—x2*(x3^2)
各項の最後の 0 は、応答変数を表します。一般に、項行列内のゼロの列ベクトルは、応答変数の位置を表します。予測子変数と応答変数が行列と列ベクトルにそれぞれ格納されている場合、各行の最後の列に応答変数を示す 0 を含めなければなりません。
式
モデル仕様の式は、次のような形式の文字ベクトルまたは string スカラーです。
',y ~ terms'
yは応答名です。terms次が含まれます変数名
+次の変数を含みます-次の変数を除外します:項の積である交互作用を定義します*交互作用とすべての次数の低い項を定義します*で繰り返されるとおり、^は予測子をべき乗にし、^は低い次数の項も含みます()項をグループ化します
ヒント
式には既定で定数 (切片) 項が含まれます。モデルから定数項を除外するには、式に -1 を含めます。
次に例を示します。
'y ~ x1 + x2 + x3' は、切片がある 3 変数線形モデルです。
'y ~ x1 + x2 + x3 - 1' は、切片がない 3 変数線形モデルです。
'y ~ x1 + x2 + x3 + x2^2' は、切片と x2^2 項がある 3 変数モデルです。
'y ~ x1 + x2^2 + x3' は、x2^2 に x2 項が含まれるので、前の例と同じです。
'y ~ x1 + x2 + x3 + x1:x2' には x1*x2 項が含まれています。
'y ~ x1*x2 + x3' は、x1*x2 = x1 + x2 + x1:x2 なので、前の例と同じです。
'y ~ x1*x2*x3 - x1:x2:x3' には、3 次交互作用を除く x1、x2、x3 間の交互作用がすべてあります。
'y ~ x1*(x2 + x3 + x4)' には、すべての線形項、および x1 と他の各変数の積があります。
たとえば、行列予測子をもつ fitlm を使って交互作用モデルを指定するには、次のようにします。
mdl = fitlm(X,y,'y ~ x1*x2*x3 - x1:x2:x3');stepwiselm と予測子の table tbl を使ってモデルを指定するには、1 つの定数から始め、線形モデル上限があると想定します。tbl の応答変数が 'y'、予測子変数が 'x1'、'x2' および'x3' という名前であるとします。
mdl2 = stepwiselm(tbl,'y ~ 1','Upper','y ~ x1 + x2 + x3');
モデルのデータへの当てはめ
最も一般的な近似のオプション引数は次のとおりです。
fitlmのロバスト回帰で'RobustOpts'名前と値のペアを'on'にします。stepwiselmで適切な上限モデルを指定します。たとえば、'Upper'を'linear'に設定します。'CategoricalVars'名前と値のペアを使用してどの変数が categorical であるか指定します。予測子1および6がカテゴリカル変数であることを指定するには、[1 6]などの列番号をもつベクトルを入力します。または、変数が categorical であることを示す1のエントリをもつ、データ列と同じ長さの logical ベクトルを入力します。7 つの予測子があり、予測子1と6が categorical である場合、logical([1,0,0,0,0,1,0])と指定します。table では名前と値のペア
'ResponseVar'で応答変数を示します。既定の設定は、配列の最後の列です。
以下に例を示します。
mdl = fitlm(X,y,'linear', ... 'RobustOpts','on','CategoricalVars',3); mdl2 = stepwiselm(tbl,'constant', ... 'ResponseVar','MPG','Upper','quadratic');
品質の調査と当てはめたモデルの調整
モデルを当てはめた後で、結果を確認して調整を行います。
モデル表示
線形回帰モデルの名前または disp(mdl) を入力すると、いくつかの診断情報が表示されます。この表示は、当てはめたモデルがデータを適切にあらわすかどうかを確認するために基本情報のいくつかを提供します。
たとえば、線形モデルを 5 つの予測子のうち 2 つが存在せず、切片の項がないデータにモデルを当てはめるには、次のようにします。
X = randn(100,5); y = X*[1;0;3;0;-1] + randn(100,1); mdl = fitlm(X,y)
mdl =
Linear regression model:
y ~ 1 + x1 + x2 + x3 + x4 + x5
Estimated Coefficients:
Estimate SE tStat pValue
_________ ________ ________ __________
(Intercept) 0.038164 0.099458 0.38372 0.70205
x1 0.92794 0.087307 10.628 8.5494e-18
x2 -0.075593 0.10044 -0.75264 0.45355
x3 2.8965 0.099879 29 1.1117e-48
x4 0.045311 0.10832 0.41831 0.67667
x5 -0.99708 0.11799 -8.4504 3.593e-13
Number of observations: 100, Error degrees of freedom: 94
Root Mean Squared Error: 0.972
R-squared: 0.93, Adjusted R-Squared: 0.926
F-statistic vs. constant model: 248, p-value = 1.5e-52
次の点に注意してください。
表示には
Estimate列に各係数の推定値が含まれます。これらは真の値[0;1;0;3;0;-1]にかなり近い値です。係数推定には標準誤差列があります。
予測子 1、3 および 5 に対してレポートされた (標準誤差の仮定により t 統計量
tStatから導出された)pValueは極端に小さい値です。これらは、応答データyを作成するために使われた 3 つの予測子です。(Intercept)、x2およびx4に対するpValueは 0.01 よりはるかに大きい値です。これらの 3 つの予測子は、応答データyを作成するためには使われませんでした。表示には、、自由度調整済み 、および F 統計量が含まれています。
ANOVA
近似されたモデルの品質を確認するには、ANOVA 表を調べます。たとえば、5 つの予測子をもつ線形モデルに対してanovaを次のように使用します。
tbl = anova(mdl)
tbl=6×5 table
SumSq DF MeanSq F pValue
_______ __ _______ _______ __________
x1 106.62 1 106.62 112.96 8.5494e-18
x2 0.53464 1 0.53464 0.56646 0.45355
x3 793.74 1 793.74 840.98 1.1117e-48
x4 0.16515 1 0.16515 0.17498 0.67667
x5 67.398 1 67.398 71.41 3.593e-13
Error 88.719 94 0.94382
この表には、モデルの表示と少し異なる結果が含まれています。x2 と x4 の効果が重要でないことが、この表で明確にわかります。目的によってはこのモデルから x2 と x4 を削除することを検討してください。
診断プロット
診断プロットによって外れ値を特定でき、モデルや当てはめで他の問題を確認できます。たとえば、carsmall データを読み込み、Cylinders (categorical) と Weight の関数として MPG のモデルを作成します。
load carsmall tbl = table(Weight,MPG,Cylinders); tbl.Cylinders = categorical(tbl.Cylinders); mdl = fitlm(tbl,'MPG ~ Cylinders*Weight + Weight^2');
データとモデルのてこ比のプロットを作成します。
plotDiagnostics(mdl)
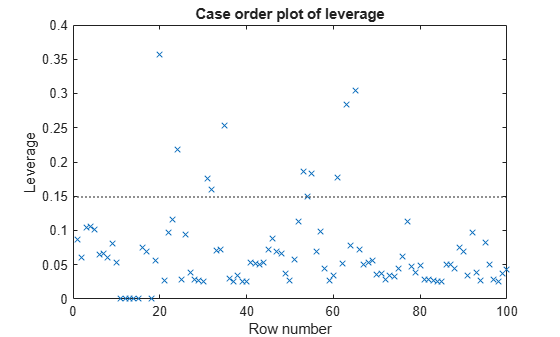
てこ比の高い点がいくつかあります。ただし、てこ比の高い点が外れ値かどうかはこのプロットではわかりません。
クックの距離が大きい点を探します。
plotDiagnostics(mdl,'cookd')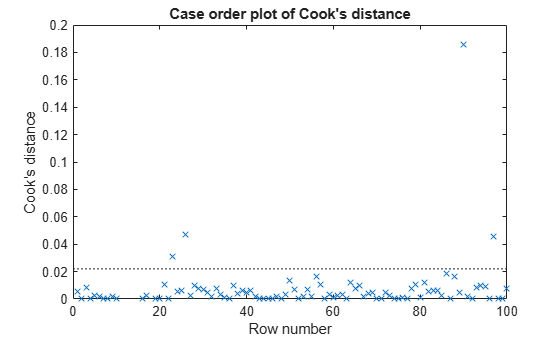
クックの距離が大きい点が 1 つあります。この点を特定してモデルから削除します。データ カーソルを使用して、外れ値をクリックして特定するか、プログラムを使用して次のように外れ値を特定します。
[~,larg] = max(mdl.Diagnostics.CooksDistance); mdl2 = fitlm(tbl,'MPG ~ Cylinders*Weight + Weight^2','Exclude',larg);
残差 — 学習データのモデル品質
モデルまたはデータ内の誤差、外れ値または相関を検出できるいくつかの残差プロットが存在します。最もシンプルな残差プロットは既定のヒストグラム プロットであり、これは残差の範囲と頻度を示します。また、確率プロットは残差の分布が正規分布と一致する分散を比較する方法を示します。
残差の検査
plotResiduals(mdl)
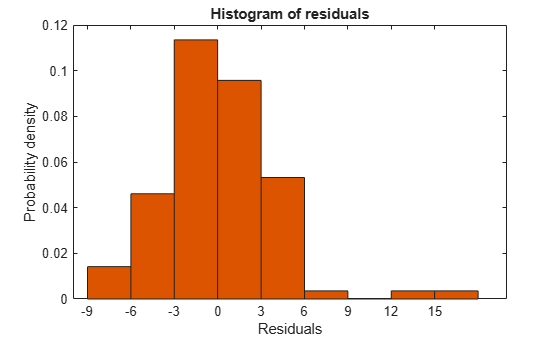
12 を超える観測は外れ値の可能性があります。
plotResiduals(mdl,'probability')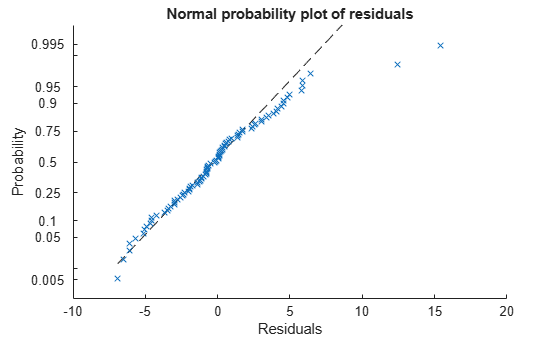
外れ値の可能性がある 2 つの値もこのプロットに表示されます。それ以外の場合は、確率プロットはかなり直線に見え、これは正規分布している残差に適切に近似していることを意味します。
次のように入力すると、2 つの外れ値を特定してデータから削除することができます。
outl = find(mdl.Residuals.Raw > 12)
outl = 2×1
90
97
外れ値を削除するには、次の Exclude 名前と値のペアを使用します。
mdl3 = fitlm(tbl,'MPG ~ Cylinders*Weight + Weight^2','Exclude',outl);
mdl2 の残差プロットを調べます。
plotResiduals(mdl3)
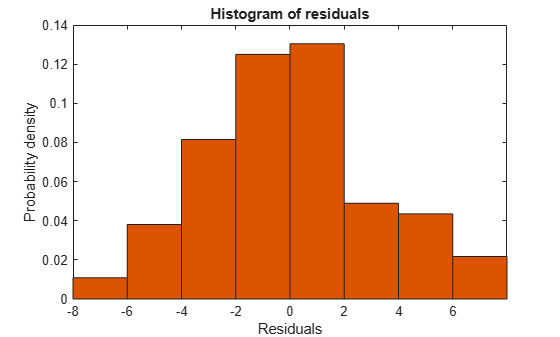
新しい残差プロットはかなり左右対称で、目立った問題はないように見えます。しかし、残差の間にいくらか系列相関が見られます。新しいプロットを作成して、そのような効果が存在するかどうかを確認します。
plotResiduals(mdl3,'lagged')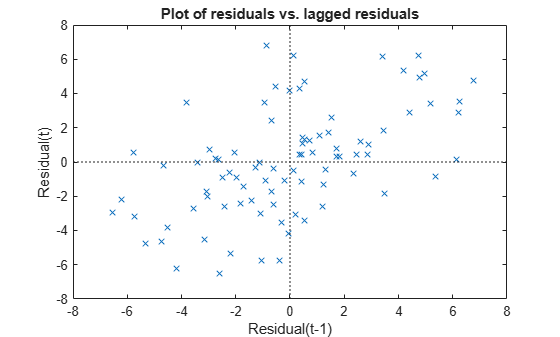
散布図は、第 1 象限と第 3 象限に他の 2 つの象限より多くのプロットが表示され、残差の間に正の系列相関があることを示しています。
可能性のある別の問題は、広範囲の観測で残差が大きい場合です。現在のモデルにこの問題がないか確認してください。
plotResiduals(mdl3,'fitted')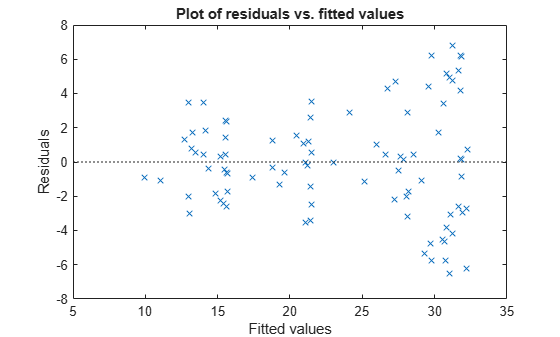
近似値が比較的大きい場合に残差が大きくなる傾向があります。モデルの誤差はおそらく測定値に比例します。
予測子の効果を理解するためのプロット
次の例では、さまざまなプロットを使用して各予測子が回帰モデルに与える影響を理解する方法について説明します。
応答のスライス プロットを調査します。これは、各予測子の効果を個別に表示します。
plotSlice(mdl)
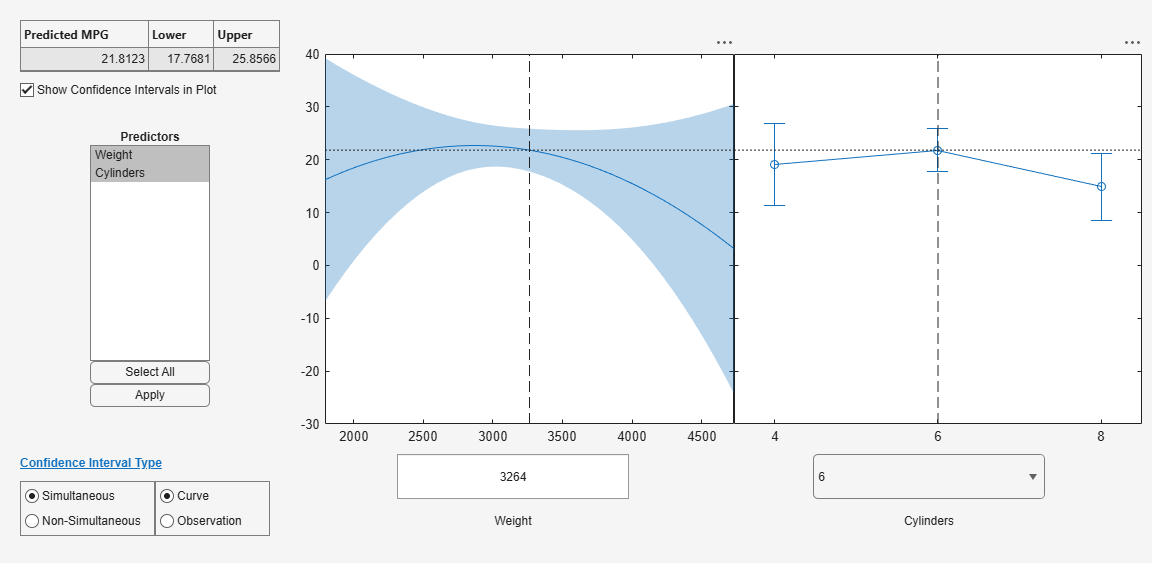
青い縦の破線によって表される個々の予測子値をドラッグできます。また、赤い破線の曲線で表されている、同時信頼限界と非同時信頼限界を選択することもできます。
効果のプロットを使用して、応答に対する予測子の効果を別に画面に表示します。
plotEffects(mdl)
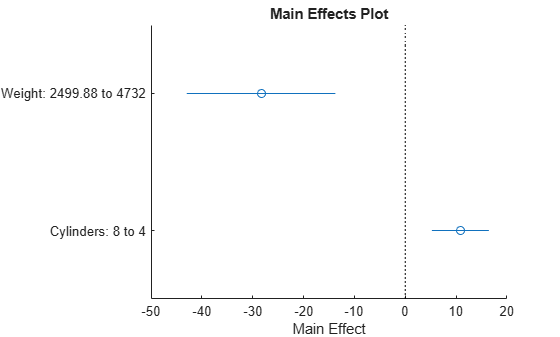
このプロットで、Weight が約 2,500 から 4,732 に変わると MPG が約 30 低下する (上の青い円の位置) ことがわかります。また、気筒の数が 8 から 4 に変化すると、MPG は約 10 増加します (下の青い円の位置)。青い水平ラインはこれらの予測子の信頼区間を表しています。この予測は、別の予測子が変化したときの 1 つの予測子の平均をもとにしています。このように 2 つの予測子が相関関係にある場合、結果の解釈を慎重に行ってください。
別の予測子が変化したときの 1 つの予測子の平均の効果を表示するのではなく、交互作用プロットの結合部の交互作用を調べます。
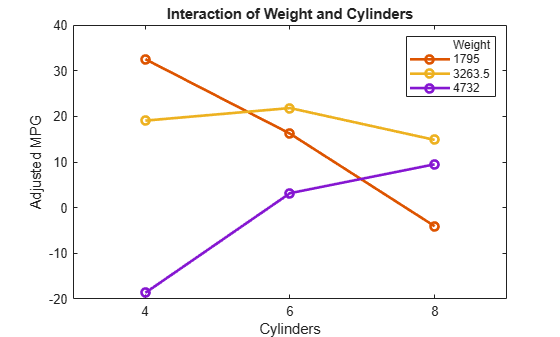
plotInteraction(mdl,'Weight','Cylinders')
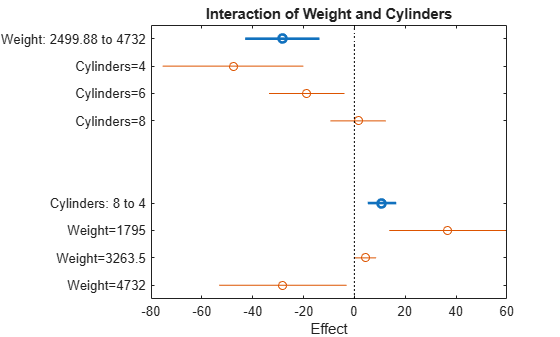
交互作用プロットは、別の予測子を固定して、1 つの予測子を変化させたときの効果を表します。このプロットのほうがはるかに多くの情報を提供します。たとえば、比較的軽量の自動車 (Weight = 1,795) では、気筒の数が減少すると燃費は向上しますが、比較的重い自動車 (Weight = 4,732) の場合は、気筒の数が減少すると燃費も低下します。
交互作用についてさらに詳しく理解するには、予測子を含む交互作用プロットを調べます。1 つの予測子を固定し、別の予測子を変化させたこのプロットでは、その効果が曲線で示されます。気筒をさまざまな数に固定して、交互作用を調べます。
plotInteraction(mdl,'Cylinders','Weight','predictions')
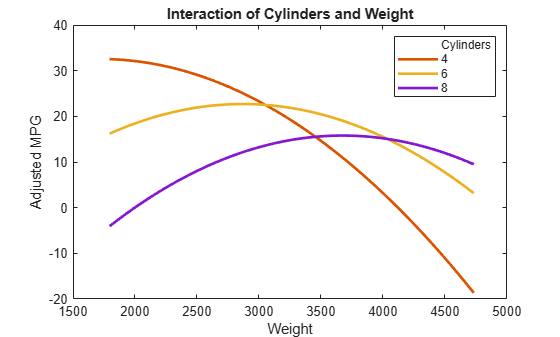
次に、重量のさまざまな固定水準で交互作用を調べます。
plotInteraction(mdl,'Weight','Cylinders','predictions')
項の効果を理解するためのプロット
次の例では、回帰モデルにおける各項の影響を理解する方法について、さまざまなプロットを使用して説明します。
追加変数としての Weight^2 で、追加変数プロットを作成します。
plotAdded(mdl,'Weight^2')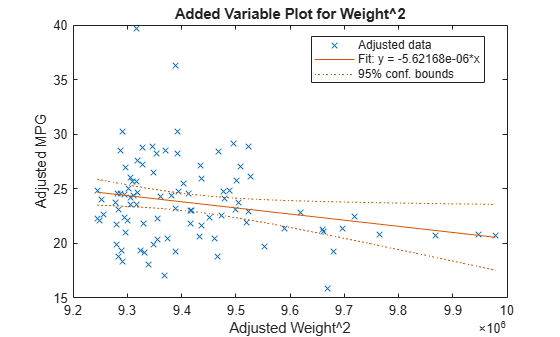
このプロットは、Weight^2 と MPG の両方を Weight^2 以外の項に近似した結果を示します。plotAdded を使用する理由は、Weight^2 を追加することによって、どのような追加の改善がモデルに期待できるかを理解するためです。これらの点を当てはめる線の係数は、完全なモデルの Weight^2 の係数です。係数表の表示から理解できるように、Weight^2 予測子は有意性 (pValue < 0.05) の境目を超えたあたりにあります。これはプロットでも確認できます。水平線 (定数 y) を信頼限界に含めることはできないように見えるので、傾きがゼロのモデルはデータと整合しません。
モデルの追加変数プロットを全体として作成します。
plotAdded(mdl)
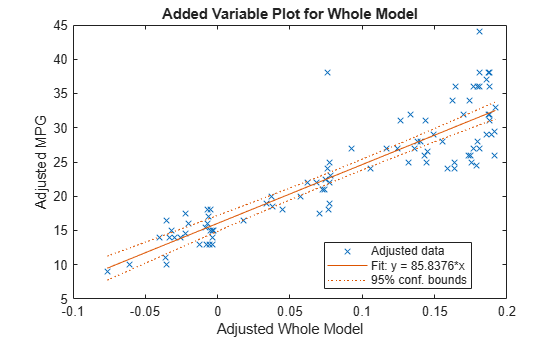
モデル全体は非常に有意性が高いため、信頼限界は水平ラインを包含するには至りません。そのラインの傾きは、最良近似の方向に投影された予測子への近似の傾き、すなわち、係数ベクトルのノルムです。
モデルの変更
モデルを変更するには、次の 2 つの方法があります。
step— 一度に 1 つずつ項を追加または削除します。stepは、追加または削除する最も重要な項を選択します。addTermsおよびremoveTerms— 指定された項を追加または削除します。単一モデルまたはモデル範囲の選択 で説明したいずれかの型を使用して、項を指定します。
stepwiselm を使用してモデルを作成した場合、異なる上位モデルまたは下位モデルを指定した場合のみ step の効果があります。RobustOpts を使用してモデルを当てはめた場合、step は機能しません。
たとえば、carbig データをもとに燃費の線形モデルから開始します。
load carbig tbl = table(Acceleration,Displacement,Horsepower,Weight,MPG); mdl = fitlm(tbl,'linear','ResponseVar','MPG')
mdl =
Linear regression model:
MPG ~ 1 + Acceleration + Displacement + Horsepower + Weight
Estimated Coefficients:
Estimate SE tStat pValue
__________ __________ ________ __________
(Intercept) 45.251 2.456 18.424 7.0721e-55
Acceleration -0.023148 0.1256 -0.1843 0.85388
Displacement -0.0060009 0.0067093 -0.89441 0.37166
Horsepower -0.043608 0.016573 -2.6312 0.008849
Weight -0.0052805 0.00081085 -6.5123 2.3025e-10
Number of observations: 392, Error degrees of freedom: 387
Root Mean Squared Error: 4.25
R-squared: 0.707, Adjusted R-Squared: 0.704
F-statistic vs. constant model: 233, p-value = 9.63e-102
最大 10 ステップに対して step を使用して、モデルの改良を試みます。
mdl1 = step(mdl,'NSteps',10)1. Adding Displacement:Horsepower, FStat = 87.4802, pValue = 7.05273e-19
mdl1 =
Linear regression model:
MPG ~ 1 + Acceleration + Weight + Displacement*Horsepower
Estimated Coefficients:
Estimate SE tStat pValue
__________ __________ _______ __________
(Intercept) 61.285 2.8052 21.847 1.8593e-69
Acceleration -0.34401 0.11862 -2.9 0.0039445
Displacement -0.081198 0.010071 -8.0623 9.5014e-15
Horsepower -0.24313 0.026068 -9.3265 8.6556e-19
Weight -0.0014367 0.00084041 -1.7095 0.088166
Displacement:Horsepower 0.00054236 5.7987e-05 9.3531 7.0527e-19
Number of observations: 392, Error degrees of freedom: 386
Root Mean Squared Error: 3.84
R-squared: 0.761, Adjusted R-Squared: 0.758
F-statistic vs. constant model: 246, p-value = 1.32e-117
1 回のみの変更後に step が停止しました。
モデルの単純化を試みるには、Acceleration および Weight の項を mdl1 から削除します。
mdl2 = removeTerms(mdl1,'Acceleration + Weight')mdl2 =
Linear regression model:
MPG ~ 1 + Displacement*Horsepower
Estimated Coefficients:
Estimate SE tStat pValue
__________ _________ _______ ___________
(Intercept) 53.051 1.526 34.765 3.0201e-121
Displacement -0.098046 0.0066817 -14.674 4.3203e-39
Horsepower -0.23434 0.019593 -11.96 2.8024e-28
Displacement:Horsepower 0.00058278 5.193e-05 11.222 1.6816e-25
Number of observations: 392, Error degrees of freedom: 388
Root Mean Squared Error: 3.94
R-squared: 0.747, Adjusted R-Squared: 0.745
F-statistic vs. constant model: 381, p-value = 3e-115
mdl2 は Displacement と Horsepower のみを使用し、Adjusted R-Squared メトリックの mdl1 とほぼ同じくらい良好なデータの近似を得ます。
新しいデータに対する応答を予測またはシミュレート
LinearModel オブジェクトには、新しいデータに対する応答を予測またはシミュレートする、predict、fevalおよびrandomという 3 つの関数があります。
predict
予測に対する信頼区間を予測および取得するには、関数predictを使用します。
carbig データを読み込み、予測子 Acceleration、Displacement、Horsepower および Weight に対する応答 MPG の既定の線形モデルを作成します。
load carbig
X = [Acceleration,Displacement,Horsepower,Weight];
mdl = fitlm(X,MPG);最小値、平均値、最大値から、3 行の予測子の配列を作成します。X には NaN 値が含まれているので、関数 mean の "omitnan" オプションを指定します。既定では、関数 min および max は計算で NaN 値を省略します。
Xnew = [min(X);mean(X,"omitnan");max(X)];予測モデル応答と予測子の信頼区間を求めます。
[NewMPG, NewMPGCI] = predict(mdl,Xnew)
NewMPG = 3×1
34.1345
23.4078
4.7751
NewMPGCI = 3×2
31.6115 36.6575
22.9859 23.8298
0.6134 8.9367
平均応答の信頼限界は、最大応答または最小応答の信頼限界よりも範囲が狭くなっています。
feval
応答を予測するには、関数fevalを使用します。table からのモデルの作成では、多くの場合に feval の方が predict よりも応答の予測に便利です。新しい予測子データがある場合、table または行列を作成せずに、その予測子データを feval に渡すことができます。ただし、feval は信頼限界を提供しません。
carbig データ セットを読み込み、予測子 Acceleration、Displacement、Horsepower および Weight に対する応答 MPG の既定の線形モデルを作成します。
load carbig tbl = table(Acceleration,Displacement,Horsepower,Weight,MPG); mdl = fitlm(tbl,"linear",ResponseVar="MPG");
予測子の平均値についてモデルの応答を予測します。
NewMPG = feval(mdl,mean(Acceleration,"omitnan"),mean(Displacement,"omitnan"),mean(Horsepower,"omitnan"),mean(Weight,"omitnan"))
NewMPG = 23.4078
random
応答をシミュレートするには、関数randomを使用します。関数 random は、新しいランダム応答値をシミュレートします。これは、学習データと同じ分散のランダム外乱を平均予測に加算したものと同じです。
carbig データを読み込み、予測子 Acceleration、Displacement、Horsepower および Weight に対する応答 MPG の既定の線形モデルを作成します。
load carbig
X = [Acceleration,Displacement,Horsepower,Weight];
mdl = fitlm(X,MPG);最小値、平均値、最大値から予測子の 3 行の配列を作成します。
Xnew = [min(X);mean(X,"omitnan");max(X)];ランダム性を含む新しい予測モデル応答を生成します。
rng("default") % for reproducibility NewMPG = random(mdl,Xnew)
NewMPG = 3×1
36.4178
31.1958
-4.8176
負の値の MPG は妥当ではないと思われるため、予測を 2 回試行してください。
NewMPG = random(mdl,Xnew)
NewMPG = 3×1
37.7959
24.7615
-0.7783
NewMPG = random(mdl,Xnew)
NewMPG = 3×1
32.2931
24.8628
19.9715
Xnew の 3 行目の予測 (maximal) は明らかに信頼できません。
当てはめたモデルの共有
以下のコマンドを使用して線形回帰モデル (たとえば mdl) を生成したとします。
load carbig tbl = table(Acceleration,Displacement,Horsepower,Weight,MPG); mdl = fitlm(tbl,'linear','ResponseVar','MPG');
このモデルを他のユーザーと共有するには、以下の手順が可能です。
モデルの表示を提供する。
mdl
mdl =
Linear regression model:
MPG ~ 1 + Acceleration + Displacement + Horsepower + Weight
Estimated Coefficients:
Estimate SE tStat pValue
__________ __________ ________ __________
(Intercept) 45.251 2.456 18.424 7.0721e-55
Acceleration -0.023148 0.1256 -0.1843 0.85388
Displacement -0.0060009 0.0067093 -0.89441 0.37166
Horsepower -0.043608 0.016573 -2.6312 0.008849
Weight -0.0052805 0.00081085 -6.5123 2.3025e-10
Number of observations: 392, Error degrees of freedom: 387
Root Mean Squared Error: 4.25
R-squared: 0.707, Adjusted R-Squared: 0.704
F-statistic vs. constant model: 233, p-value = 9.63e-102
モデル定義と係数を提供する。
mdl.Formula
ans = MPG ~ 1 + Acceleration + Displacement + Horsepower + Weight
mdl.CoefficientNames
ans = 1×5 cell
{'(Intercept)'} {'Acceleration'} {'Displacement'} {'Horsepower'} {'Weight'}
mdl.Coefficients.Estimate
ans = 5×1
45.2511
-0.0231
-0.0060
-0.0436
-0.0053
参考
fitlm | anova | stepwiselm | predict | LinearModel | plotResiduals | lasso | sequentialfs