plsregress
部分最小二乗 (PLS) 回帰
構文
説明
例
spectra データ セットを読み込みます。ガソリン 60 標本の近赤外線 (NIR) 401 波長のスペクトル強度を格納する数値行列として予測子 X を作成します。対応するオクタン価を格納する数値ベクトルとして応答 y を作成します。
load spectra
X = NIR;
y = octane;10 個の成分を使用して X の予測子に対する y の応答の PLS 回帰を実行します。
[XL,yl,XS,YS,beta,PCTVAR] = plsregress(X,y,10);
応答変数 (PCTVAR) で説明される分散の比率を成分の数の関数としてプロットします。
plot(1:10,cumsum(100*PCTVAR(2,:)),'-bo'); xlabel('Number of PLS components'); ylabel('Percent Variance Explained in y');
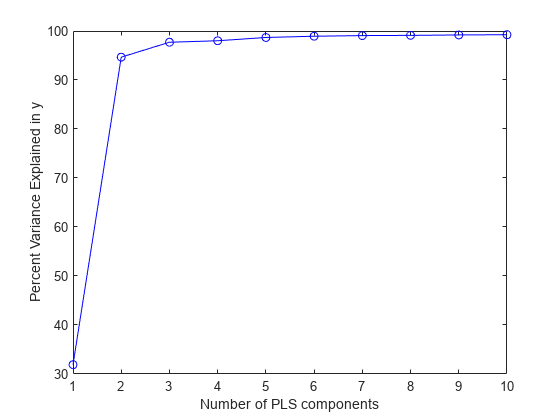
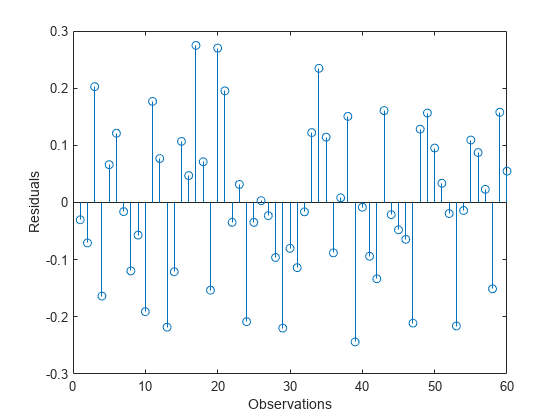
当てはめた応答を計算し、残差を表示します。
yfit = [ones(size(X,1),1) X]*beta; residuals = y - yfit; stem(residuals) xlabel('Observations'); ylabel('Residuals');
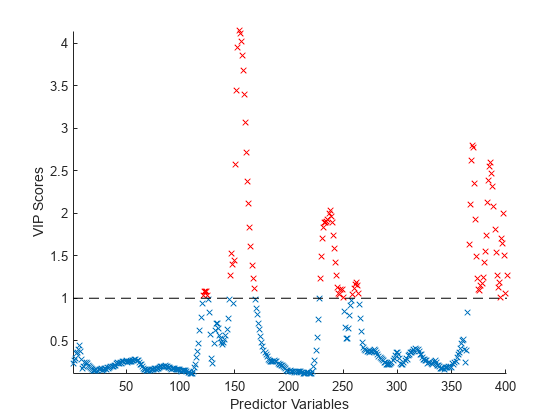
部分最小二乗 (PLS) 回帰モデルの投影における変数重要度 (VIP) スコアを計算します。VIP は、予測子変数の間に多重共線性が存在する場合の変数の選択に使用できます。VIP スコアが 1 より大きい変数は、PLS 回帰モデルの投影において重要であると見なされます[3]。
spectra データ セットを読み込みます。ガソリン 60 標本の近赤外線 (NIR) 401 波長のスペクトル強度を格納する数値行列として予測子 X を作成します。対応するオクタン価を格納する数値ベクトルとして応答 y を作成します。成分の数 ncomp を指定します。
load spectra
X = NIR;
y = octane;
ncomp = 10;10 個の成分を使用して X の予測子に対する y の応答の PLS 回帰を実行します。
[XL,yl,XS,YS,beta,PCTVAR,MSE,stats] = plsregress(X,y,ncomp);
正規化された PLS の重みを計算します。
W0 = stats.W ./ sqrt(sum(stats.W.^2,1));
ncomp 個の成分の VIP スコアを計算します。
p = size(XL,1); sumSq = sum(XS.^2,1).*sum(yl.^2,1); vipScore = sqrt(p* sum(sumSq.*(W0.^2),2) ./ sum(sumSq,2));
VIP スコアが 1 以上の変数を検索します。
indVIP = find(vipScore >= 1);
VIP スコアをプロットします。
scatter(1:length(vipScore),vipScore,'x') hold on scatter(indVIP,vipScore(indVIP),'rx') plot([1 length(vipScore)],[1 1],'--k') hold off axis tight xlabel('Predictor Variables') ylabel('VIP Scores')
入力引数
名前と値の引数
出力引数
アルゴリズム
plsregress では SIMPLS アルゴリズム[1]を使用します。モデルの当てはめに定数項 (切片) が含まれる場合、この関数は最初に列平均を差し引くことで X および Y をセンタリングし、予測子と応答のセンタリングされた変数 X0 および Y0 を求めます。ただし、この関数は列の再スケーリングは行いません。標準化された変数を使用して PLS 回帰を実行するには、zscore を使用して X および Y を正規化します (X0 および Y0 の列を平均値が 0 になるようにセンタリングしてから標準偏差が 1 になるようにスケーリング)。
X および Y を作成した後、plsregress は X0'*Y0 で特異値分解 (SVD) を計算します。予測と応答の負荷 XL および YL は、X0 および Y0 の予測子スコア XS での回帰によって得られる係数です。センタリングされたデータ X0 および Y0 は、それぞれ XS*XL' および XS*YL' を使用して再構成できます。
plsregress は最初に YS を YS = Y0*YL として計算します。ただし、慣例では[1]、plsregress はその後 YS の各列を XS の前の列と直交させ、XS'*YS が下三角行列になるようにします。
モデルの当てはめに定数項 (切片) が含まれない場合、X および Y は当てはめプロセスにおいてセンタリングされません。
参照
[1] de Jong, Sijmen. “SIMPLS: An Alternative Approach to Partial Least Squares Regression.” Chemometrics and Intelligent Laboratory Systems 18, no. 3 (March 1993): 251–63. https://doi.org/10.1016/0169-7439(93)85002-X.
[2] Rosipal, Roman, and Nicole Kramer. "Overview and Recent Advances in Partial Least Squares." Subspace, Latent Structure and Feature Selection: Statistical and Optimization Perspectives Workshop (SLSFS 2005), Revised Selected Papers (Lecture Notes in Computer Science 3940). Berlin, Germany: Springer-Verlag, 2006, vol. 3940, pp. 34–51. https://doi.org/10.1007/11752790_2.
[3] Chong, Il-Gyo, and Chi-Hyuck Jun. “Performance of Some Variable Selection Methods When Multicollinearity Is Present.” Chemometrics and Intelligent Laboratory Systems 78, no. 1–2 (July 2005) 103–12. https://doi.org/10.1016/j.chemolab.2004.12.011.
拡張機能
バージョン履歴
R2008a で導入