Viterbi Decoder
ビタビ アルゴリズムを使用した畳み込み符号化されたデータの復号化
ライブラリ:
Communications Toolbox /
Error Detection and Correction /
Convolutional
Communications Toolbox HDL Support /
Error Detection and Correction /
Convolutional
説明
Viterbi Decoder ブロックは、ビタビ アルゴリズムを使用して、畳み込み符号化された入力シンボルを復号化し、バイナリ出力シンボルを生成します。トレリス構造体は、畳み込み符号化スキームを指定します。詳細については、Trellis Description of a Convolutional Codeを参照してください。
このブロックは、パフォーマンスを高速化するために一度に複数のシンボルを処理でき、シミュレーション中に長さが変化する入力を受け入れることができます。可変サイズ信号の詳細については、可変サイズの信号の基礎 (Simulink)を参照してください。
このアイコンは、すべてのオプションのブロック端子が有効になっていることを示しています。
![]()
例
畳み込み符号化と BPSK 変調をバイナリ信号に適用し、変調後の信号を AWGN チャネルに渡します。BPSK 復調とビタビ復号化を適用した後の信号のシンボル エラー レート (SER) を計算します。
モデルの検証
doc_conv モデルは、Bernoulli Binary Generatorブロックを使用してバイナリ信号を生成します。Convolutional Encoderブロックは信号を符号化します。BPSK Modulator Basebandブロックは信号を変調します。AWGN Channelブロックは信号にノイズを付加します。BPSK 変調信号をゼロ位相シフトで復調するには、Complex to Real-Imag (Simulink)ブロックを使用して複素シンボル復調の実数成分の値を単に抽出します。Viterbi Decoderブロックは信号を復号化します。Error Rate Calculationブロックは SER を計算します。
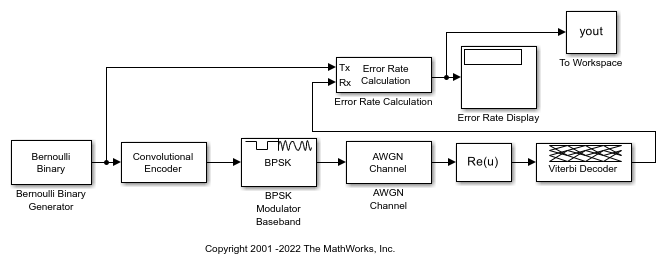
シミュレーションの実行
ans =
'Filtering the signal through an AWGN channel with the EsN0 set to -1 dB, the computed SER is 0.005608.'
ans =
'For 53499 transmitted symbols, there were 300 symbols errors.'
この例では、符号化率 1/2 の畳み込み符号化とビタビ復号化を使用するパンクチャド符号化システムをシミュレートします。ビタビ復号化器の複雑度は符号化率に伴い急激に増大します。パンクチャ手法を使用すると、符号化率の低い標準のコーダーを使用して符号化率の高い符号の符号化と復号化を行うことができます。
cm_punct_conv_code モデルは、畳み込み符号化後の BPSK 信号を AWGN チャネル経由で送信し、受信信号を復調し、ビタビ復号化を行って符号化前の信号を復元します。このモデルは、エラー レートを計算するため、元の % 信号と復号化後の信号を比較します。
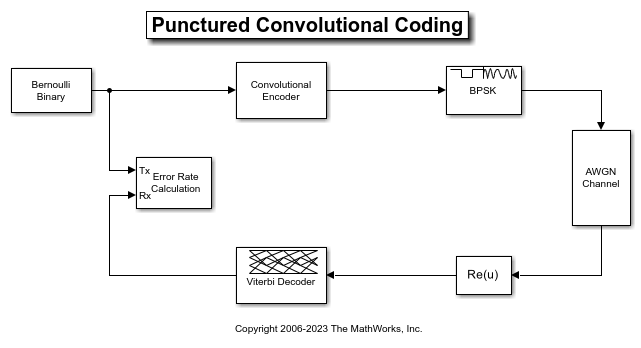
このモデルは、コールバック関数 PreloadFcn を使用してこれらのワークスペース変数を設定し、ブロック パラメーターを初期化します。
puncvec = [1;1;0;1;1;0]; EsN0dB = 2; traceback = 96; % Viterbi traceback depth
詳細については、モデル コールバック (Simulink)を参照してください。
このモデルのブロックは次の処理を行います。
Bernoulli Binary Generator — [フレームあたりのサンプル数] を
3に設定します。このブロックは、各サンプル時刻においてフレームあたり 3 つのサンプルを出力するランダム ビットから成るシーケンスを作成します。Convolutional Encoder — [Trellis structure] で既定の設定を使用し、[Puncture code] を選択し、[パンクチャ ベクトル] をワークスペース変数
puncvecに設定します。このブロックは、符号化率 1/2、拘束長 7 の畳み込み符号を符号化率 3/4 の符号にパンクチャすることによって、データのフレームを符号化します。puncvecで指定されたパンクチャ ベクトルは、符号化率が 1/2 で拘束長が 7 の畳み込み符号に最も適したパンクチャ ベクトルです。パンクチャ ベクトルにおいて、1は符号化されたベクトルの対応する位置にあるビットが出力ベクトルに送信されることを示し、0はそのビットが削除されることを示します。ここで構成した符号化器では、符号化後の位置 1、2、4、および 5 にあるビットは送信されますが、位置 3 および 6 にあるビットは削除されます。符号化率が 3/4 であるということは、3 ビットを入力するごとにパンクチャド符号によって 4 ビットの出力が生成されることを意味します。BPSK Modulator Baseband — 既定のパラメーター値を使用して、符号化されたメッセージを変調します。
AWGN Channel — [モード] を
Signal to noise ratio (Es/No)に設定し、Es/No (dB)をワークスペース変数EsN0dBに設定します。変調器ブロックは単位電力信号を生成するため、[Input signal power, referenced to 1 ohm (watts)] は既定値1のままにします。Viterbi Decoder — [Trellis structure]、[Punctured code]、および [パンクチャ ベクトル] を、Convolutional Encoder ブロックに合わせて設定します。このブロックは、[判定タイプ] を
Unquantizedに設定し、[トレースバック長] をワークスペース変数tracebackに設定します。符号のパンクチャ処理を行わない場合、指定した畳み込み符号を復号化するにはトレースバック長が 40 あれば十分です。ただし、このブロックは、パンクチャによって生じるあいまいさを解決するための十分なデータを復号化器に与えるため、トレースバック長を 96 にしてパンクチャド符号を復号化します。畳み込み符号化器と同様に、復号化器のパンクチャ ベクトルによってパンクチャの位置が示されます。パンクチャされたビットは送信されないため、その値を示す情報は存在しません。そのため、復号化器による復号化処理では、この位置にあるビットは無視されます。パンクチャ ベクトルの各 1 は送信されるビットを、各 0 は復号化器への入力で無視されるパンクチャされたビットを示します。Complex to Real-Imag (Simulink) — 複素数サンプルの実数部を抽出して BPSK 信号を復調します。
Error Rate Calculation — [受信遅延] の値を使用してシステム遅延のサンプル数の合計を表し、復号化されたビットを元のソース ビットと比較します。このブロックは、計算された BER、観測された誤り数、および処理されたビットの数で構成される 3 要素ベクトルを出力します。このシステムではビタビのトレースバック長によってのみ遅延が生じるため、[受信遅延] をワークスペース変数
tracebackに設定します。一般に、BER シミュレーションは、誤り数が最小となるまで、またはシミュレーションで最大数のビットが処理されるまで実行されます。Error Rate Calculation ブロックは、シミュレーション期間を制御するため、[シミュレーションの停止] パラメーターを選択し、目標誤り数を100に設定し、シンボルの最大数を1e6に設定します。
ビット エラー レートの評価
設定した EbN0 の範囲についてこのコードを実行してモデルをシミュレートし、ビット エラー レート曲線を作成します。
シミュレーション結果をパンクチャド符号ビット エラー確率の境界近似値と比較します [1]。符号化率 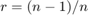 のパンクチャド符号のビット エラー レート性能は、次式のように上に有界となります。
のパンクチャド符号のビット エラー レート性能は、次式のように上に有界となります。
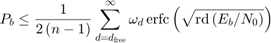
この式において、erfc は相補誤差関数を示し、 は符号化率を示します。
は符号化率を示します。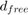 と
と 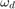 はどちらも個々のコードに依存します。この例で示す符号化率 3/4 の符号の場合、 = 5、
はどちらも個々のコードに依存します。この例で示す符号化率 3/4 の符号の場合、 = 5、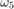 = 42、
= 42、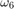 = 201、
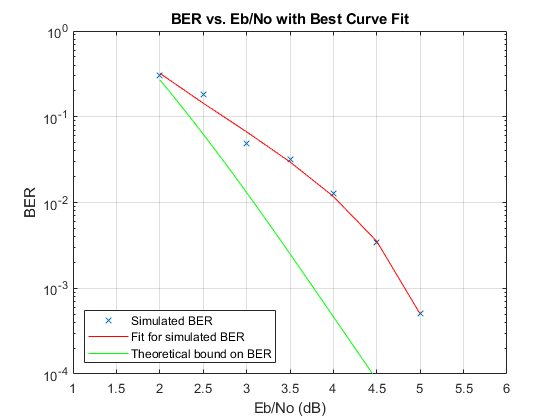
= 201、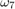 = 1492 などのようになります。詳細については、参考文献 [ 1 ] を参照してください。
= 1492 などのようになります。詳細については、参考文献 [ 1 ] を参照してください。
2:0.02:5 における Eb/N0 の値の積算の最初の 7 項を使用して、理論的な境界の近似値を計算します。nerr で使用する値は参考文献 [ 2 ] の Table II から取得します。
シミュレーション結果、近似曲線、および理論的な境界をプロットします。
場合によっては、下方ビットのエラー レートが限界より少し上回るようなシミュレーション結果になることがあります。これは、復号器のトレースバック長が有限なためです。または、ビット エラーの観測個数が 500 個未満の場合はシミュレーションのばらつきによるものです。
パンクチャを行わない畳み込み符号化を示す例については、誤りの検出と訂正の「軟判定復号化」のセクションを参照してください。
参考文献
Yasuda, Y., K. Kashiki, and Y. Hirata, "High Rate Punctured Convolutional Codes for Soft Decision Viterbi Decoding," IEEE Transactions on Communications, Vol. COM-32, March, 1984, pp. 315–319.
Begin, G., Haccoun, D., and Paquin, C., "Further results on High-Rate Punctured Convolutional Codes for Viterbi and Sequential Decoding," IEEE Transactions on Communications, Vol. 38, No. 11, November, 1990, p. 1923.
Viterbi Decoderブロックを固定小数点の硬判定畳み込み復号化と軟判定畳み込み復号化に使用します。ビット エラー レート解析アプリで計算された理論上の上限と結果を比較します。
シミュレーションの構成
cm_viterbi_harddec_fixpt モデルおよび cm_viterbi_softdec_fixpt モデルは、同様のレイアウトを使用して、ビタビ復号化器の固定小数点モデリング属性を強調表示します。モデルの既定の構成では、PreLoadFcn コールバックを使用して、AWGN Channelブロックの 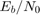 の設定を 4 dB に指定します。畳み込み符号化器は、符号化率 1/2 の符号化器として構成されます。具体的には、2 ビットごとに、符号化器がさらに 2 つの冗長ビットを追加します。符号化率に対応するため、AWGN ブロックの [Eb/No (dB)] パラメーターは、割り当てられた の設定から
の設定を 4 dB に指定します。畳み込み符号化器は、符号化率 1/2 の符号化器として構成されます。具体的には、2 ビットごとに、符号化器がさらに 2 つの冗長ビットを追加します。符号化率に対応するため、AWGN ブロックの [Eb/No (dB)] パラメーターは、割り当てられた の設定から 10*log10(2) を差し引くことにより、半分にされます。Error Rate Calculationブロックの実行期間を 100 エラーまたは 1e6 ビットに制限します。
固定小数点モデリング
固定小数点モデリングは、ハードウェア実装の検討およびデータとパラメーターのダイナミック レンジを考慮に入れたビットトゥルー シミュレーションを有効にします。たとえば、対象のハードウェアが DSP マイクロプロセッサである場合、可能性のある語長は 8、16、または 32 ビットであり、ターゲット ハードウェアが ASIC または FPGA の場合は語長の選択に柔軟性があります。
固定小数点のビタビ復号化を有効にするための条件は、次のとおりです。
硬判定の場合、ブロック入力は ufix1 型 (語長 1 の符号なし整数) でなければなりません。この入力 ( a 0 または a 1 のいずれか) に基づき、内部分岐メトリクスは、トレリス構造体に指定された (硬判定例の場合は 2 に等しい) ように、語長の符号なし整数 = (出力ビットの数) を使用して計算されます。
軟判定の場合、ブロック入力は ufixN 型 (語長 N の符号なし整数) でなければなりません。ここで、N は固定長小数点の復号化を有効にするための軟判定ビットの数です。ブロック入力は、0 ~
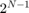 の範囲の整数でなければなりません。内部分岐メトリクスは、トレリス構造体に指定された (軟判定例の場合は 4 に等しい) ように、語長の符号なし整数 = (N + 出力ビットの数 - 1) を使用して計算されます。
の範囲の整数でなければなりません。内部分岐メトリクスは、トレリス構造体に指定された (軟判定例の場合は 4 に等しい) ように、語長の符号なし整数 = (N + 出力ビットの数 - 1) を使用して計算されます。
[State metric word length] は、ユーザーによって指定され、通常は既に計算されている分岐メトリクス語長よりも長くなければなりません。これは、システム用に記録されたデータを確認することによって、最も適した値に (ハードウェアやデータの検討に基づいて) 調整することができます。
ログを有効にするため、[アプリ]、[固定小数点ツール] を選択します。[固定小数点設定] メニューで、[固定小数点のインストルメンテーション モード] を [Minimums, maximums and overflows] に設定し、シミュレーションを再実行します。オーバーフローが確認できた場合は、データが選択したコンテナーに収まらなかったことを示しています。データを処理する前にデータのスケーリングを行うか、語長のサイズを増やしてみる (ハードウェアで許可されている場合) ことができます。データの最小値と最大値に基づいて、選択したコンテナーが適切なサイズであるかどうかを判断することもできます。
[State metric word length] のさまざまな値でシミュレーションを実行して、その値のアルゴリズムへの影響を理解します。BER の結果に悪影響を及ぼさない適切な値になるようにパラメーターを絞り込むこともできます。
cm_viterbi_harddec_fixpt モデルの硬判定構成:

BPSK Demodulator Basebandは、復号化器に渡される硬判定を生成します。
Data Type Conversion (Simulink)ブロックは
ModeパラメーターをFixed pointに設定し、出力データ型をfixdt(0,1,0)にキャストします。Viterbi Decoderブロックに対する信号入力はufix1です。
Viterbi Decoder ブロックの
Decision typeパラメーターはHard decisionに設定されます。[Data Types] タブでは、State metric word lengthが4に設定され、Output data typeがbooleanに設定されます。ビット エラー レートが表示され、ワークスペース変数BERに取得されます。
cm_viterbi_softdec_fixpt モデルの軟判定構成:
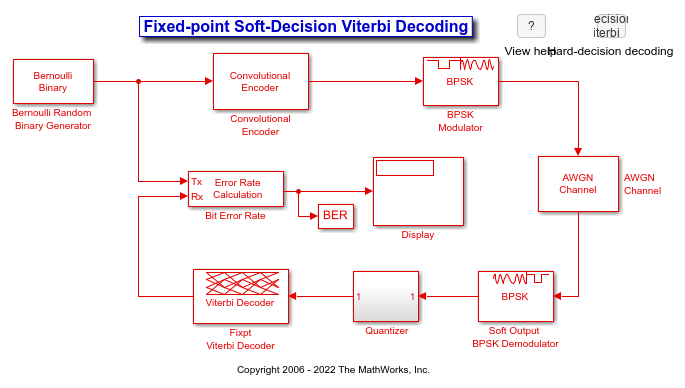
BPSK Demodulator Basebandは、対数尤度比を使用して軟判定を生成します。これらの軟出力は、3 ビットで量子化され、復号化器に渡されます。
Quantizer サブシステム (Gain (Simulink)、Scalar Quantizer Encoder、Data Type Conversion (Simulink)ブロックを含む) は信号を量子化し、出力データ型を
fixdt(0,3,0)にキャストします。Viterbi Decoderブロックに対する信号入力はufix3です。
Viterbi Decoderブロックでは、
Decision typeパラメーターはSoft decision、Number of soft decision bitsは 3 に設定されています。[Data Types] タブでは、State metric word lengthが6、Output data typeがbooleanに設定されています。ビット エラー レートが表示され、ワークスペース変数BERに取得されます。
硬判定と軟判定の復号化の比較
2 つのモデルは、ビット エラー レート解析アプリ内から実行してシミュレーション曲線を生成し、硬判定復号化と軟判定復号化の BER 性能を比較するように構成されています。
以下に概説する手順に従って、次のプロットで結果を生成できます。
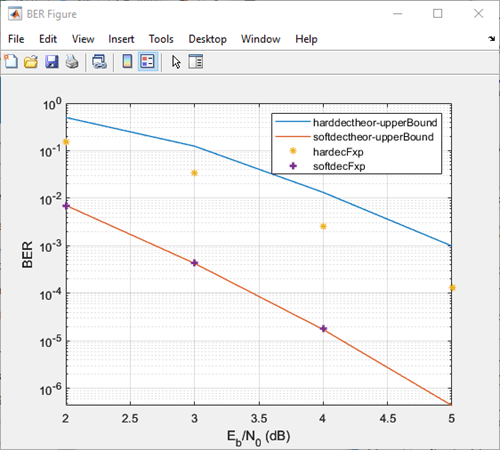
以下の手順により、理論値と固定小数点の硬判定/軟判定ビタビ復号化のシミュレーション結果が生成されます。
[アプリ] タブで選択するか、MATLAB コマンド プロンプトで
bertoolと入力して、ビット エラー レート解析アプリを開きます。[Theoretical] ペインで、[Eb/N0 range] を 2:5 に設定し、[Channel type] を
[AWGN]に設定し、[Modulation type] を[PSK]に設定し、[Channel coding] を[Convolutional]に設定し、[Decision method] を[Hard]に設定して実行した後[Soft]に設定して実行します。理論上の結果の硬判定データ セットと軟判定データ セットを識別できるように、[BER Data Set] の名前を変更します。[Monte Carlo] ペインで、[Eb/N0 range] を 2:1:5 に設定し、[Simulation environment] で
[Simulink]を選択し、[BER variable name] を[BER]に設定し、[Simulation limits] の [Number of errors] を 100、[Number of bits] を 1e6 に設定します。[Model name] をcm_viterbi_harddec_fixptに設定して実行した後cm_viterbi_softdec_fixptに設定して実行します。Simulink の結果の硬判定データ セットと軟判定データ セットを識別できるように、[BER Data Set] の名前を変更します。
この 4 回の実行により、アプリは次のイメージのようになります。

倍精度データとの比較
さらに詳しく調べるために、Apps > Fixed-Point Tool を選択して、倍精度データで同じモデルを実行できます。Fixed-Point Tool アプリで、Data type override を選択して Double にします。この選択によって、すべてのブロックのすべてのデータ型設定がオーバーライドされて倍精度を使用します。Viterbi Decoder ブロックでは、Output type が boolean に設定されているため、このパラメーターも double に設定しなければなりません。
モデルのシミュレーション時に、倍精度と固定小数点の BER の結果が同じであることに注意してください。これらが同じになるのは、精度の低下を避け、メモリ効率を最適化するためにモデルの固定小数点パラメーターが選択されているためです。
拡張例
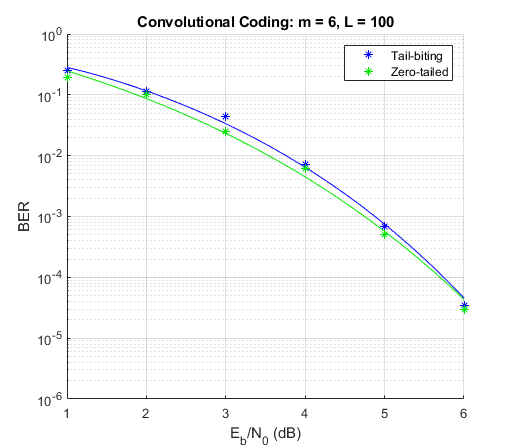
テールバイティング畳み込み符号化
Convolutional Encoder ブロックと Viterbi Decoder ブロックを使用して、テールバイティング畳み込み符号をシミュレートする。
端子
入力
出力
パラメーター
ブロックの特性
詳細
ビタビ復号化アルゴリズムには 3 つの主なコンポーネントがあります。それらは、分岐メトリクス計算 (BMC)、追加比較と選択 (ACS)、およびトレースバック復号化 (TBD) です。次の図は、符号化率 k/n の符号の信号の流れを示しています。

次の図は、符号化率 1/2、nsdec = 3 の信号の流れの BMC を示しています。

次の図は、ユーザーによってマスクに WL2 が指定された ACS コンポーネントのサイクルを示しています。

これらの流れ図では、inNT、bMetNT、stMetNT、および outNT は numerictype (Fixed-Point Designer) オブジェクトであり、bMetFIMATH と stMetFIMATH は fimath (Fixed-Point Designer) オブジェクトです。
参照
[1] Clark, George C., and J. Bibb Cain. Error-Correction Coding for Digital Communications. Applications of Communications Theory. New York: Plenum Press, 1981.
[2] Gitlin, Richard D., Jeremiah F. Hayes, and Stephen B. Weinstein. Data Communications Principles. Applications of Communications Theory. New York: Plenum Press, 1992.
[3] Heller, J., and I. Jacobs. “Viterbi Decoding for Satellite and Space Communication.” IEEE® Transactions on Communication Technology 19, no. 5 (October 1971): 835–48. https://doi.org/10.1109/TCOM.1971.1090711.
[4] Yasuda, Y., K. Kashiki, and Y. Hirata. “High-Rate Punctured Convolutional Codes for Soft Decision Viterbi Decoding.” IEEE Transactions on Communications 32, no. 3 (March 1984): 315–19. https://doi.org/10.1109/TCOM.1984.1096047.
[5] Haccoun, D., and G. Begin. “High-Rate Punctured Convolutional Codes for Viterbi and Sequential Decoding.” IEEE Transactions on Communications 37, no. 11 (November 1989): 1113–25. https://doi.org/10.1109/26.46505.
[6] Begin, G., D. Haccoun, and C. Paquin. “Further Results on High-Rate Punctured Convolutional Codes for Viterbi and Sequential Decoding.” IEEE Transactions on Communications 38, no. 11 (November 1990): 1922–28. https://doi.org/10.1109/26.61470.
[7] Moision, B. "A Truncation Depth Rule of Thumb for Convolutional Codes." In Information Theory and Applications Workshop (January 27 2008-February 1 2008, San Diego, California), 555-557. New York: IEEE, 2008.