fitrkernel
Fit Gaussian kernel regression model using random feature expansion
Syntax
Description
fitrkernel trains or cross-validates a Gaussian kernel
regression model for nonlinear regression. fitrkernel is more
practical to use for big data applications that have large training sets, but can also
be applied to smaller data sets that fit in memory.
fitrkernel maps data in a low-dimensional space into a
high-dimensional space, then fits a linear model in the high-dimensional space by
minimizing the regularized objective function. Obtaining the linear model in the
high-dimensional space is equivalent to applying the Gaussian kernel to the model in the
low-dimensional space. Available linear regression models include regularized support
vector machine (SVM) and least-squares regression models.
To train a nonlinear SVM regression model on in-memory data, see fitrsvm.
Mdl = fitrkernel(Tbl,ResponseVarName)Mdl trained using the
predictor variables contained in the table Tbl and the
response values in Tbl.ResponseVarName.
Mdl = fitrkernel(___,Name,Value)
[
also returns the hyperparameter optimization results when you specify
Mdl,FitInfo,HyperparameterOptimizationResults] = fitrkernel(___)OptimizeHyperparameters.
[
also returns Mdl,FitInfo,AggregateOptimizationResults] = fitrkernel(___)AggregateOptimizationResults, which contains
hyperparameter optimization results when you specify the
OptimizeHyperparameters and
HyperparameterOptimizationOptions name-value arguments.
You must also specify the ConstraintType and
ConstraintBounds options of
HyperparameterOptimizationOptions. You can use this
syntax to optimize on compact model size instead of cross-validation loss, and
to perform a set of multiple optimization problems that have the same options
but different constraint bounds.
Examples
Train a kernel regression model for a tall array by using SVM.
When you perform calculations on tall arrays, MATLAB® uses either a parallel pool (default if you have Parallel Computing Toolbox™) or the local MATLAB session. To run the example using the local MATLAB session when you have Parallel Computing Toolbox, change the global execution environment by using the mapreducer function.
mapreducer(0)
Create a datastore that references the folder location with the data. The data can be contained in a single file, a collection of files, or an entire folder. Treat 'NA' values as missing data so that datastore replaces them with NaN values. Select a subset of the variables to use. Create a tall table on top of the datastore.
varnames = {'ArrTime','DepTime','ActualElapsedTime'};
ds = datastore('airlinesmall.csv','TreatAsMissing','NA',...
'SelectedVariableNames',varnames);
t = tall(ds);Specify DepTime and ArrTime as the predictor variables (X) and ActualElapsedTime as the response variable (Y). Select the observations for which ArrTime is later than DepTime.
daytime = t.ArrTime>t.DepTime; Y = t.ActualElapsedTime(daytime); % Response data X = t{daytime,{'DepTime' 'ArrTime'}}; % Predictor data
Standardize the predictor variables.
Z = zscore(X); % Standardize the dataTrain a default Gaussian kernel regression model with the standardized predictors. Extract a fit summary to determine how well the optimization algorithm fits the model to the data.
[Mdl,FitInfo] = fitrkernel(Z,Y)
Found 6 chunks. |========================================================================= | Solver | Iteration / | Objective | Gradient | Beta relative | | | Data Pass | | magnitude | change | |========================================================================= | INIT | 0 / 1 | 4.307833e+01 | 9.925486e-02 | NaN | | LBFGS | 0 / 2 | 2.782790e+01 | 7.202403e-03 | 9.891473e-01 | | LBFGS | 1 / 3 | 2.781351e+01 | 1.806211e-02 | 3.220672e-03 | | LBFGS | 2 / 4 | 2.777773e+01 | 2.727737e-02 | 9.309939e-03 | | LBFGS | 3 / 5 | 2.768591e+01 | 2.951422e-02 | 2.833343e-02 | | LBFGS | 4 / 6 | 2.755857e+01 | 5.124144e-02 | 7.935278e-02 | | LBFGS | 5 / 7 | 2.738896e+01 | 3.089571e-02 | 4.644920e-02 | | LBFGS | 6 / 8 | 2.716704e+01 | 2.552696e-02 | 8.596406e-02 | | LBFGS | 7 / 9 | 2.696409e+01 | 3.088621e-02 | 1.263589e-01 | | LBFGS | 8 / 10 | 2.676203e+01 | 2.021303e-02 | 1.533927e-01 | | LBFGS | 9 / 11 | 2.660322e+01 | 1.221361e-02 | 1.351968e-01 | | LBFGS | 10 / 12 | 2.645504e+01 | 1.486501e-02 | 1.175476e-01 | | LBFGS | 11 / 13 | 2.631323e+01 | 1.772835e-02 | 1.161909e-01 | | LBFGS | 12 / 14 | 2.625264e+01 | 5.837906e-02 | 1.422851e-01 | | LBFGS | 13 / 15 | 2.619281e+01 | 1.294441e-02 | 2.966283e-02 | | LBFGS | 14 / 16 | 2.618220e+01 | 3.791806e-03 | 9.051274e-03 | | LBFGS | 15 / 17 | 2.617989e+01 | 3.689255e-03 | 6.364132e-03 | | LBFGS | 16 / 18 | 2.617426e+01 | 4.200232e-03 | 1.213026e-02 | | LBFGS | 17 / 19 | 2.615914e+01 | 7.339928e-03 | 2.803348e-02 | | LBFGS | 18 / 20 | 2.620704e+01 | 2.298098e-02 | 1.749830e-01 | |========================================================================= | Solver | Iteration / | Objective | Gradient | Beta relative | | | Data Pass | | magnitude | change | |========================================================================= | LBFGS | 18 / 21 | 2.615554e+01 | 1.164689e-02 | 8.580878e-02 | | LBFGS | 19 / 22 | 2.614367e+01 | 3.395507e-03 | 3.938314e-02 | | LBFGS | 20 / 23 | 2.614090e+01 | 2.349246e-03 | 1.495049e-02 | |========================================================================|
Mdl =
RegressionKernel
ResponseName: 'Y'
Learner: 'svm'
NumExpansionDimensions: 64
KernelScale: 1
Lambda: 8.5385e-06
BoxConstraint: 1
Epsilon: 5.9303
Properties, Methods
FitInfo = struct with fields:
Solver: 'LBFGS-tall'
LossFunction: 'epsiloninsensitive'
Lambda: 8.5385e-06
BetaTolerance: 1.0000e-03
GradientTolerance: 1.0000e-05
ObjectiveValue: 26.1409
GradientMagnitude: 0.0023
RelativeChangeInBeta: 0.0150
FitTime: 9.4743
History: [1×1 struct]
Mdl is a RegressionKernel model. To inspect the regression error, you can pass Mdl and the training data or new data to the loss function. Or, you can pass Mdl and new predictor data to the predict function to predict responses for new observations. You can also pass Mdl and the training data to the resume function to continue training.
FitInfo is a structure array containing optimization information. Use FitInfo to determine whether optimization termination measurements are satisfactory.
For improved accuracy, you can increase the maximum number of optimization iterations ('IterationLimit') and decrease the tolerance values ('BetaTolerance' and 'GradientTolerance') by using the name-value pair arguments of fitrkernel. Doing so can improve measures like ObjectiveValue and RelativeChangeInBeta in FitInfo. You can also optimize model parameters by using the 'OptimizeHyperparameters' name-value pair argument.
Load the carbig data set.
load carbigSpecify the predictor variables (X) and the response variable (Y).
X = [Acceleration,Cylinders,Displacement,Horsepower,Weight]; Y = MPG;
Delete rows of X and Y where either array has NaN values. Removing rows with NaN values before passing data to fitrkernel can speed up training and reduce memory usage.
R = rmmissing([X Y]); % Data with missing entries removed
X = R(:,1:5);
Y = R(:,end); Cross-validate a kernel regression model using 5-fold cross-validation. Standardize the predictor variables.
Mdl = fitrkernel(X,Y,'Kfold',5,'Standardize',true)
Mdl =
RegressionPartitionedKernel
CrossValidatedModel: 'Kernel'
ResponseName: 'Y'
NumObservations: 392
KFold: 5
Partition: [1×1 cvpartition]
ResponseTransform: 'none'
Properties, Methods
numel(Mdl.Trained)
ans = 5
Mdl is a RegressionPartitionedKernel model. Because fitrkernel implements five-fold cross-validation, Mdl contains five RegressionKernel models that the software trains on training-fold (in-fold) observations.
Examine the cross-validation loss (mean squared error) for each fold.
kfoldLoss(Mdl,'mode','individual')
ans = 5×1
13.1983
14.2686
23.9162
21.0763
24.3975
Optimize hyperparameters automatically using the OptimizeHyperparameters name-value argument.
Load the carbig data set.
load carbigSpecify the predictor variables (X) and the response variable (Y).
X = [Acceleration,Cylinders,Displacement,Horsepower,Weight]; Y = MPG;
Delete rows of X and Y where either array has NaN values. Removing rows with NaN values before passing data to fitrkernel can speed up training and reduce memory usage.
R = rmmissing([X Y]); % Data with missing entries removed
X = R(:,1:5);
Y = R(:,end); Find hyperparameters that minimize five-fold cross-validation loss by using automatic hyperparameter optimization. Specify OptimizeHyperparameters as 'auto' so that fitrkernel finds the optimal values of the KernelScale, Lambda, Epsilon, and Standardize name-value arguments. For reproducibility, set the random seed and use the 'expected-improvement-plus' acquisition function.
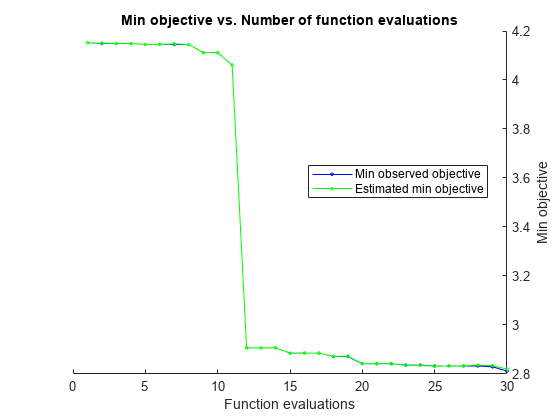
rng('default') [Mdl,FitInfo,HyperparameterOptimizationResults] = fitrkernel(X,Y,'OptimizeHyperparameters','auto',... 'HyperparameterOptimizationOptions',struct('AcquisitionFunctionName','expected-improvement-plus'))
|===================================================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | KernelScale | Lambda | Epsilon | Standardize |
| | result | log(1+loss) | runtime | (observed) | (estim.) | | | | |
|===================================================================================================================================|
| 1 | Best | 4.1521 | 0.26003 | 4.1521 | 4.1521 | 11.415 | 0.0017304 | 615.77 | true |
| 2 | Best | 4.1489 | 0.12585 | 4.1489 | 4.1503 | 509.07 | 0.0064454 | 0.048411 | true |
| 3 | Accept | 5.251 | 0.82629 | 4.1489 | 4.1489 | 0.0015621 | 1.8257e-05 | 0.051954 | true |
| 4 | Accept | 4.3329 | 0.13281 | 4.1489 | 4.1489 | 0.0053278 | 2.37 | 17.883 | false |
| 5 | Accept | 4.2414 | 0.092679 | 4.1489 | 4.1489 | 0.004474 | 0.13531 | 14.426 | true |
| 6 | Best | 4.148 | 0.066927 | 4.148 | 4.148 | 0.43562 | 2.5339 | 0.059928 | true |
| 7 | Accept | 4.1521 | 0.060774 | 4.148 | 4.148 | 3.2193 | 0.012683 | 813.56 | false |
| 8 | Best | 3.8438 | 0.07135 | 3.8438 | 3.8439 | 5.7821 | 0.065897 | 2.056 | true |
| 9 | Accept | 4.1305 | 0.080728 | 3.8438 | 3.8439 | 110.96 | 0.42454 | 7.6606 | true |
| 10 | Best | 3.7951 | 0.090688 | 3.7951 | 3.7954 | 1.1595 | 0.054292 | 0.012493 | true |
| 11 | Accept | 4.2311 | 0.39617 | 3.7951 | 3.7954 | 0.0011423 | 0.00015862 | 8.6125 | false |
| 12 | Best | 2.8871 | 0.75989 | 2.8871 | 2.8872 | 185.22 | 2.1981e-05 | 1.0401 | false |
| 13 | Accept | 4.1521 | 0.057363 | 2.8871 | 3.0058 | 993.92 | 2.6036e-06 | 58.773 | false |
| 14 | Best | 2.8648 | 0.66609 | 2.8648 | 2.8765 | 196.57 | 2.2026e-05 | 1.081 | false |
| 15 | Accept | 4.2977 | 0.15141 | 2.8648 | 2.8668 | 0.017949 | 1.5685e-05 | 15.01 | false |
| 16 | Best | 2.8016 | 0.44022 | 2.8016 | 2.8017 | 786 | 3.4462e-06 | 1.6117 | false |
| 17 | Accept | 2.9032 | 0.18368 | 2.8016 | 2.8026 | 974.16 | 0.00019486 | 1.6661 | false |
| 18 | Accept | 2.9051 | 0.86226 | 2.8016 | 2.8018 | 288.21 | 2.6218e-06 | 2.0933 | false |
| 19 | Accept | 3.4438 | 1.2058 | 2.8016 | 2.803 | 56.999 | 2.885e-06 | 1.3903 | false |
| 20 | Accept | 2.8436 | 0.82042 | 2.8016 | 2.8032 | 533.99 | 2.7293e-06 | 0.6719 | false |
|===================================================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | KernelScale | Lambda | Epsilon | Standardize |
| | result | log(1+loss) | runtime | (observed) | (estim.) | | | | |
|===================================================================================================================================|
| 21 | Accept | 2.8301 | 0.85817 | 2.8016 | 2.8024 | 411.02 | 3.4347e-06 | 0.98949 | false |
| 22 | Accept | 2.8233 | 0.43525 | 2.8016 | 2.8043 | 455.25 | 5.2936e-05 | 1.1189 | false |
| 23 | Accept | 4.1168 | 0.069902 | 2.8016 | 2.802 | 237.02 | 0.85493 | 0.42894 | false |
| 24 | Best | 2.7876 | 0.53458 | 2.7876 | 2.7877 | 495.51 | 1.8049e-05 | 1.9006 | false |
| 25 | Accept | 2.8197 | 0.40917 | 2.7876 | 2.7877 | 927.29 | 1.128e-05 | 1.1902 | false |
| 26 | Accept | 2.8361 | 0.36606 | 2.7876 | 2.7882 | 354.44 | 6.1939e-05 | 2.2591 | false |
| 27 | Accept | 2.7985 | 0.51881 | 2.7876 | 2.7906 | 506.54 | 1.4142e-05 | 1.3659 | false |
| 28 | Accept | 2.8163 | 0.37488 | 2.7876 | 2.7905 | 829.6 | 1.0965e-05 | 2.7415 | false |
| 29 | Accept | 2.8469 | 0.62784 | 2.7876 | 2.7902 | 729.48 | 3.4914e-06 | 0.039087 | false |
| 30 | Accept | 2.882 | 1.1371 | 2.7876 | 2.7902 | 255.25 | 3.2869e-06 | 0.059794 | false |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 20.5663 seconds
Total objective function evaluation time: 12.6832
Best observed feasible point:
KernelScale Lambda Epsilon Standardize
___________ __________ _______ ___________
495.51 1.8049e-05 1.9006 false
Observed objective function value = 2.7876
Estimated objective function value = 2.7902
Function evaluation time = 0.53458
Best estimated feasible point (according to models):
KernelScale Lambda Epsilon Standardize
___________ __________ _______ ___________
495.51 1.8049e-05 1.9006 false
Estimated objective function value = 2.7902
Estimated function evaluation time = 0.49372
Mdl =
RegressionKernel
ResponseName: 'Y'
Learner: 'svm'
NumExpansionDimensions: 256
KernelScale: 495.5140
Lambda: 1.8049e-05
BoxConstraint: 141.3376
Epsilon: 1.9006
Properties, Methods
FitInfo = struct with fields:
Solver: 'LBFGS-fast'
LossFunction: 'epsiloninsensitive'
Lambda: 1.8049e-05
BetaTolerance: 1.0000e-04
GradientTolerance: 1.0000e-06
ObjectiveValue: 1.3382
GradientMagnitude: 0.0051
RelativeChangeInBeta: 9.4332e-05
FitTime: 0.0700
History: []
HyperparameterOptimizationResults =
SupervisedLearningBayesianOptimization
ObjectiveFcn: @createObjFcn/inMemoryObjFcn
VariableDescriptions: [6×1 optimizableVariable]
Options: [1×1 struct]
MinObjective: 2.7876
XAtMinObjective: [1×4 table]
MinEstimatedObjective: 2.7902
XAtMinEstimatedObjective: [1×4 table]
NumObjectiveEvaluations: 30
TotalElapsedTime: 20.5663
NextPoint: [1×4 table]
XTrace: [30×4 table]
ObjectiveTrace: [30×1 double]
LossFun: 'mse'
LossTrace: [30×1 double]
ConstraintsTrace: []
UserDataTrace: {30×1 cell}
ObjectiveEvaluationTimeTrace: [30×1 double]
IterationTimeTrace: [30×1 double]
ErrorTrace: [30×1 double]
FeasibilityTrace: [30×1 logical]
FeasibilityProbabilityTrace: [30×1 double]
IndexOfMinimumTrace: [30×1 double]
ObjectiveMinimumTrace: [30×1 double]
EstimatedObjectiveMinimumTrace: [30×1 double]
For big data, the optimization procedure can take a long time. If the data set is too large to run the optimization procedure, you can try to optimize the parameters using only partial data. Use the datasample function and specify 'Replace','false' to sample data without replacement.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
Standardizing predictors before training a model can be helpful.
You can standardize training data and scale test data to have the same scale as the training data by using the
normalizefunction.Alternatively, use the
Standardizename-value argument to standardize the numeric predictors before training. The returned model includes the predictor means and standard deviations in itsMuandSigmaproperties, respectively. (since R2023b)
After training a model, you can generate C/C++ code that predicts responses for new data. Generating C/C++ code requires MATLAB Coder™. For details, see Introduction to Code Generation for Statistics and Machine Learning Functions.
Algorithms
fitrkernel minimizes the regularized objective function using a Limited-memory Broyden-Fletcher-Goldfarb-Shanno (LBFGS) solver with ridge (L2) regularization. To find the type of LBFGS solver used for training, type FitInfo.Solver in the Command Window.
'LBFGS-fast'— LBFGS solver.'LBFGS-blockwise'— LBFGS solver with a block-wise strategy. Iffitrkernelrequires more memory than the value ofBlockSizeto hold the transformed predictor data, then the function uses a block-wise strategy.'LBFGS-tall'— LBFGS solver with a block-wise strategy for tall arrays.
When fitrkernel uses a block-wise strategy, it implements LBFGS by
distributing the calculation of the loss and gradient among different parts of the data at
each iteration. Also, fitrkernel refines the initial estimates of the
linear coefficients and the bias term by fitting the model locally to parts of the data and
combining the coefficients by averaging. If you specify 'Verbose',1, then
fitrkernel displays diagnostic information for each data pass and
stores the information in the History field of
FitInfo.
When fitrkernel does not use a block-wise strategy, the initial estimates are zeros. If you specify 'Verbose',1, then fitrkernel displays diagnostic information for each iteration and stores the information in the History field of FitInfo.
References
[1] Rahimi, A., and B. Recht. “Random Features for Large-Scale Kernel Machines.” Advances in Neural Information Processing Systems. Vol. 20, 2008, pp. 1177–1184.
[2] Le, Q., T. Sarlós, and A. Smola. “Fastfood — Approximating Kernel Expansions in Loglinear Time.” Proceedings of the 30th International Conference on Machine Learning. Vol. 28, No. 3, 2013, pp. 244–252.
[3] Huang, P. S., H. Avron, T. N. Sainath, V. Sindhwani, and B. Ramabhadran. “Kernel methods match Deep Neural Networks on TIMIT.” 2014 IEEE International Conference on Acoustics, Speech and Signal Processing. 2014, pp. 205–209.
Extended Capabilities
Version History
Introduced in R2018aSee Also
bayesopt | bestPoint | fitrlinear | fitrsvm | loss | predict | RegressionKernel | resume | RegressionPartitionedKernel