オブジェクトの検出とセグメント化
Computer Vision Toolbox™ は、AI モデルを使用したオブジェクト検出、テキスト検出 (OCR)、セグメンテーションのためのエンドツーエンドのワークフローをサポートします。イメージ ラベラー アプリとビデオ ラベラー アプリを使用し、対話形式および AI アシストによるイメージやビデオのラベル付けを行って、グラウンド トゥルース データを作成することから始められます。オブジェクト検出のために、Computer Vision Toolbox は YOLO、RTMDet、SSD、Grounding DINO などの事前学習済み深層学習モデルを提供しており、これらをそのまま使用することも、転移学習を使用して用途に合わせて微調整することもできます。オブジェクト検出器アナライザー アプリを使用して、オブジェクト検出のパフォーマンス メトリクスを評価することもできます。オブジェクト検出の詳細については、深層学習を使用したオブジェクト検出入門を参照してください。
セマンティック セグメンテーションには、U-Net、DeepLab v3+、BiseNet v2、3 次元 U-Net などの事前学習済み深層学習モデルを使用できます。セマンティック セグメンテーションの詳細については、深層学習を使用したセマンティック セグメンテーション入門を参照してください。インスタンス セグメンテーションには、SOLOv2 や Mask R-CNN などの事前学習済み深層学習モデルを使用できます。インスタンス セグメンテーションの詳細については、Get Started with Instance Segmentation Using Deep Learningを参照してください。
テキスト検出には、MSER 特徴検出器または CRAFT 深層学習モデルを使用し、検出されたテキストを OCR を使用して認識することができます。詳細については、Getting Started with OCRを参照してください。Computer Vision Toolbox には、人間の姿勢推定用に事前学習済みの HRNet キーポイント検出器も用意されており、これを他のオブジェクトのカスタム キーポイント検出用に微調整することも可能です。詳細については、Getting Started with HRNetを参照してください。
カテゴリ
- オブジェクトの検出
YOLO や Grounding DINO などの事前学習済み AI モデルを使用してグラウンド トゥルースにラベルを付け、オブジェクトを検出し、転移学習を使用してカスタム検出器を作成する
- セマンティック セグメンテーション
事前学習済み AI モデルを使用してグラウンド トゥルースにラベルを付け、セマンティック セグメンテーションを実行し、転移学習を使用して U-Net などのカスタム ネットワークに学習させる
- インスタンス セグメンテーション
SOLOv2、Mask R-CNN、SAM などの事前学習済み AI モデルを使用してグラウンド トゥルースにラベルを付け、インスタンス セグメンテーションを実行する、もしくは転移学習を使用してカスタム ネットワークに学習させる
- テキスト、バーコード、および基準マーカーの検出と認識
AI モデルを使用して、テキスト (OCR)、バーコード、および基準マーカーを検出および認識する
- キーポイントの検出
事前学習済みの HRNet キーポイント検出器を使用してイメージ内の人間の姿勢を推定する、もしくはカスタム オブジェクト キーポイント検出器に学習させる
- 自動外観検査
異常検出や位置推定の手法を使用して品質管理タスクを自動化する
注目の例

YOLO v2 深層学習を使用したマルチクラス オブジェクト検出
YOLO v2 マルチクラス オブジェクト検出器に学習させ、選択したクラスとオーバーラップしきい値についてオブジェクト検出器のパフォーマンスを評価する。

深層学習を使用したセマンティック セグメンテーション
この例では、セマンティック セグメンテーション ネットワークを使用してイメージをセグメント化する方法を説明します。

Mask R-CNN を使用したインスタンス セグメンテーションの実行
この例では、マルチクラスの Mask R-CNN (Region-based Convolutional Neural Network) を使用して、人と自動車の個々のインスタンスをセグメント化する方法を説明します。

Automatically Detect and Recognize Text Using Pretrained CRAFT Network and OCR
Perform text recognition by using a deep learning based text detector and OCR.

イメージに含まれるバーコードの読み取り
イメージに含まれる 1 次元および 2 次元バーコードの検出、復号化、位置推定を行います。
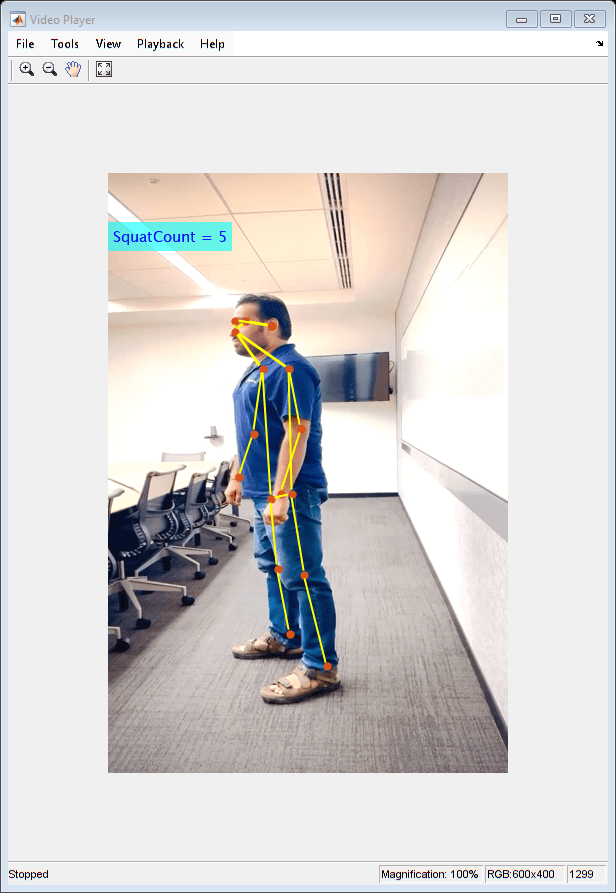
Deep Learning-based Human Pose Estimation for Squat Analysis
Use pretrained deep learning networks to estimate human body pose and perform squat analysis.

Detect Small Objects Using Tiled Training of YOLOX Network
Detect small objects in full-resolution images using tiled training of a you only look once version X (YOLOX) deep learning network.
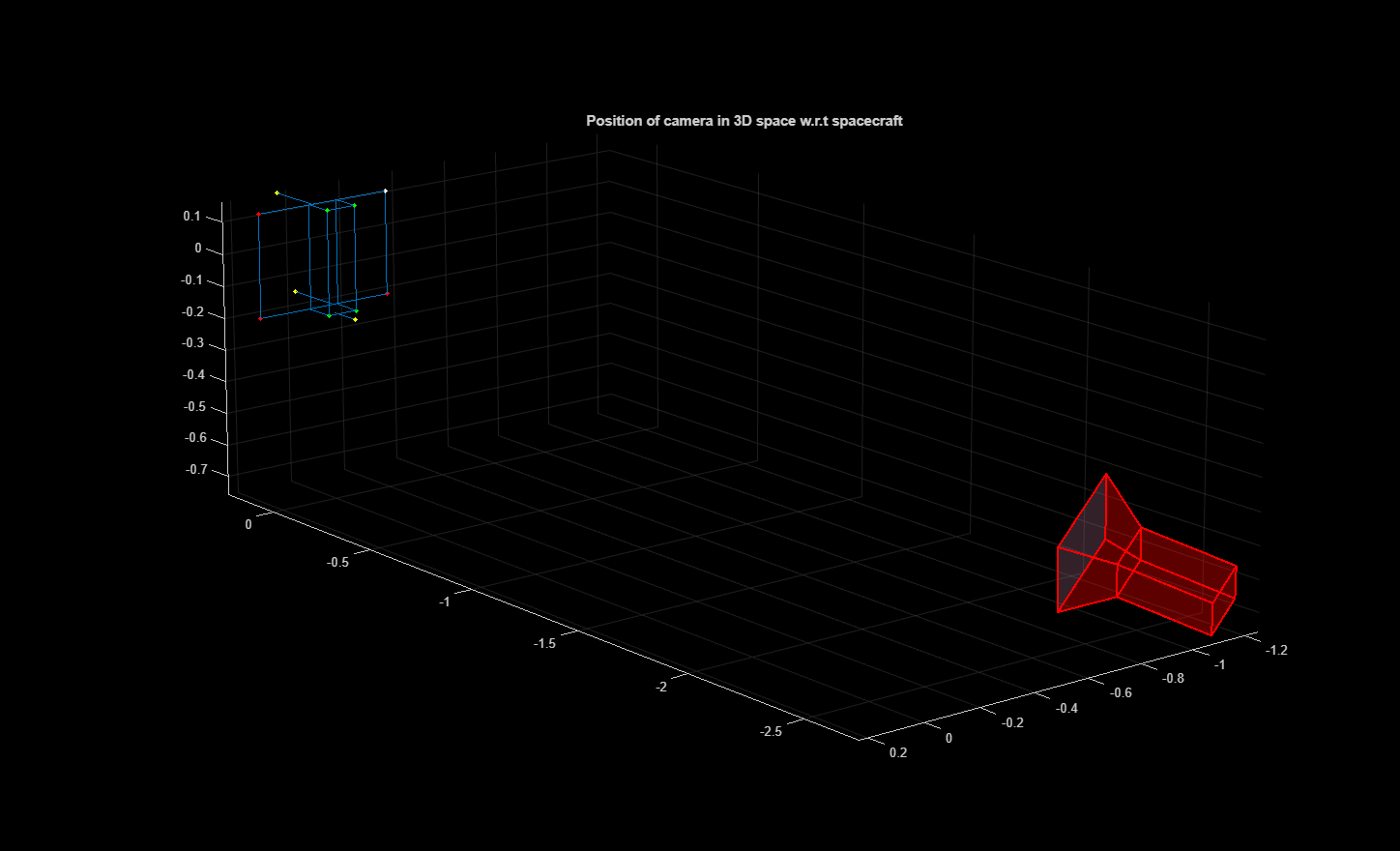
Spacecraft Pose Estimation Using HRNet Keypoint Detector and PnP Solver
Estimate keypoints and pose of spacecraft.

Augmented Reality Using AprilTag Markers
Use marker-based augmented reality to render virtual content into a scene.