loss
クラス: RegressionLinear
線形回帰モデルの回帰損失
説明
L = loss(Mdl,Tbl,ResponseVarName)Tbl 内の予測子データと Tbl.ResponseVarName 内の真の応答に対する MSE を返します。
L = loss(___,Name,Value)
入力引数
名前と値の引数
出力引数
例
次のモデルにより、10000 個の観測値をシミュレートします。
は、10% の要素が非ゼロ標準正規である 10000 行 1000 列のスパース行列です。
e は、平均が 0、標準偏差が 0.3 のランダムな正規誤差です。
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);線形回帰モデルに学習をさせます。観測値の 30% をホールドアウト標本として予約します。
CVMdl = fitrlinear(X,Y,'Holdout',0.3);
Mdl = CVMdl.Trained{1}Mdl =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000×1 double]
Bias: -0.0066
Lambda: 1.4286e-04
Learner: 'svm'
Properties, Methods
CVMdl は RegressionPartitionedLinear モデルです。これには Trained プロパティが含まれています。これは 1 行 1 列の cell 配列で、学習セットにより学習させた RegressionLinear モデルが格納されています。
学習データとテスト データを分割の定義から抽出します。
trainIdx = training(CVMdl.Partition); testIdx = test(CVMdl.Partition);
学習標本とテスト標本の MSE を推定します。
mseTrain = loss(Mdl,X(trainIdx,:),Y(trainIdx))
mseTrain = 0.1496
mseTest = loss(Mdl,X(testIdx,:),Y(testIdx))
mseTest = 0.1798
Mdl 内の正則化強度は 1 つなので、mseTrain と mseTest は数値スカラーになります。
次のモデルにより、10000 個の観測値をシミュレートします。
は、10% の要素が非ゼロ標準正規である 10000 行 1000 列のスパース行列です。
e は、平均が 0、標準偏差が 0.3 のランダムな正規誤差です。
rng(1) % For reproducibility n = 1e4; d = 1e3; nz = 0.1; X = sprandn(n,d,nz); Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1); X = X'; % Put observations in columns for faster training
線形回帰モデルに学習をさせます。観測値の 30% をホールドアウト標本として予約します。
CVMdl = fitrlinear(X,Y,'Holdout',0.3,'ObservationsIn','columns'); Mdl = CVMdl.Trained{1}
Mdl =
RegressionLinear
ResponseName: 'Y'
ResponseTransform: 'none'
Beta: [1000×1 double]
Bias: -0.0066
Lambda: 1.4286e-04
Learner: 'svm'
Properties, Methods
CVMdl は RegressionPartitionedLinear モデルです。これには Trained プロパティが含まれています。これは 1 行 1 列の cell 配列で、学習セットにより学習させた RegressionLinear モデルが格納されています。
学習データとテスト データを分割の定義から抽出します。
trainIdx = training(CVMdl.Partition); testIdx = test(CVMdl.Partition);
次の Huber 損失 ( = 1) を評価する無名関数を作成します。
ここで
は観測値 j の残差です。カスタム損失関数は特定の形式で記述しなければなりません。カスタム損失関数の記述に関するルールについては、名前と値のペアの引数 'LossFun' を参照してください。
huberloss = @(Y,Yhat,W)sum(W.*((0.5*(abs(Y-Yhat)<=1).*(Y-Yhat).^2) + ...
((abs(Y-Yhat)>1).*abs(Y-Yhat)-0.5)))/sum(W);Huber 損失関数を使用して、学習セットおよびテスト セットの回帰損失を推定します。
eTrain = loss(Mdl,X(:,trainIdx),Y(trainIdx),'LossFun',huberloss,... 'ObservationsIn','columns')
eTrain = -0.4186
eTest = loss(Mdl,X(:,testIdx),Y(testIdx),'LossFun',huberloss,... 'ObservationsIn','columns')
eTest = -0.4010
次のモデルにより、10000 個の観測値をシミュレートします。
は、10% の要素が非ゼロ標準正規である 10000 行 1000 列のスパース行列です。
e は、平均が 0、標準偏差が 0.3 のランダムな正規誤差です。
rng(1) % For reproducibility
n = 1e4;
d = 1e3;
nz = 0.1;
X = sprandn(n,d,nz);
Y = X(:,100) + 2*X(:,200) + 0.3*randn(n,1);~ の範囲で対数間隔で配置された 15 個の正則化強度を作成します。
Lambda = logspace(-4,-1,15);
データの 30% をテスト用にホールドアウトします。テスト標本のインデックスを識別します。
cvp = cvpartition(numel(Y),'Holdout',0.30);
idxTest = test(cvp);Lambda 内の強度による LASSO ペナルティを使用して、線形回帰モデルに学習をさせます。正則化強度、目的関数を最適化するための SpaRSA の使用、およびデータ分割を指定します。実行速度を向上させるため、予測子データを転置し、観測値が列単位であることを指定します。
X = X'; CVMdl = fitrlinear(X,Y,'ObservationsIn','columns','Lambda',Lambda,... 'Solver','sparsa','Regularization','lasso','CVPartition',cvp); Mdl1 = CVMdl.Trained{1}; numel(Mdl1.Lambda)
ans = 15
Mdl1 は RegressionLinear モデルです。Lambda は正則化強度の 15 次元ベクトルなので、Mdl1 はそれぞれが正則化強度に対応する 15 個の学習済みモデルであると考えることができます。
各正則化モデルについてテスト標本の平均二乗誤差を推定します。
mse = loss(Mdl1,X(:,idxTest),Y(idxTest),'ObservationsIn','columns');
Lambda の値が大きくなると、予測子変数がスパースになります。これは回帰モデルの品質として優れています。データ セット全体と、以前に使用した、データ分割指定以外のすべてのオプションを使用して、モデルに再学習をさせます。モデルごとに非ゼロの係数を特定します。
Mdl = fitrlinear(X,Y,'ObservationsIn','columns','Lambda',Lambda,... 'Solver','sparsa','Regularization','lasso'); numNZCoeff = sum(Mdl.Beta~=0);
同じ図に、各正則化強度についての MSE と非ゼロ係数の頻度をプロットします。すべての変数を対数スケールでプロットします。
figure; [h,hL1,hL2] = plotyy(log10(Lambda),log10(mse),... log10(Lambda),log10(numNZCoeff)); hL1.Marker = 'o'; hL2.Marker = 'o'; ylabel(h(1),'log_{10} MSE') ylabel(h(2),'log_{10} nonzero-coefficient frequency') xlabel('log_{10} Lambda') hold off
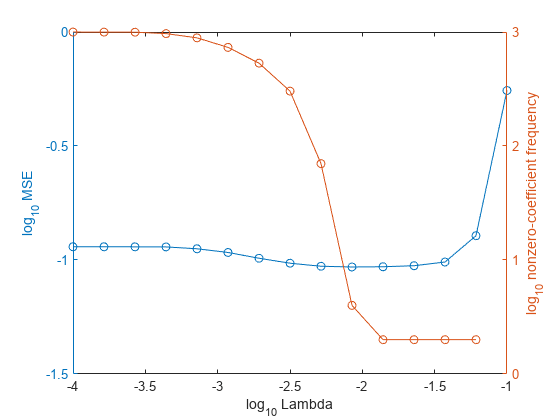
最小分類誤差と予測子変数のスパース性のバランスがとれている Lambda のインデックス (Lambda(11) など) を選択します。
idx = 11; MdlFinal = selectModels(Mdl,idx);
MdlFinal は、正則化強度として Lambda(11) を使用する学習済みの RegressionLinear モデル オブジェクトです。