loss
回帰ニューラル ネットワークの損失
説明
L = loss(___,Name=Value)
例
回帰ニューラル ネットワーク モデルのテスト セットの平均二乗誤差 (MSE) を計算します。
patients データ セットを読み込みます。データ セットから table を作成します。各行が 1 人の患者に対応し、各列が診断の変数に対応します。変数 Systolic を応答変数として使用し、残りの変数を予測子として使用します。
load patients
tbl = table(Diastolic,Height,Smoker,Weight,Systolic);非層化ホールドアウト分割を使用して、データを学習セット tblTrain とテスト セット tblTest に分割します。観測値の約 30% がテスト データ セット用に予約され、残りの観測値が学習データ セットに使用されます。
rng("default") % For reproducibility of the partition c = cvpartition(size(tbl,1),"Holdout",0.30); trainingIndices = training(c); testIndices = test(c); tblTrain = tbl(trainingIndices,:); tblTest = tbl(testIndices,:);
学習セットを使用して回帰ニューラル ネットワーク モデルに学習させます。tblTrain の列 Systolic を応答変数として指定します。数値予測子を標準化するための指定を行い、反復制限を 50 に設定します。
Mdl = fitrnet(tblTrain,"Systolic", ... "Standardize",true,"IterationLimit",50);
テスト セットの MSE を計算します。MSE の値が小さいほど、パフォーマンスが優れていることを示します。
testMSE = loss(Mdl,tblTest,"Systolic")testMSE = 22.2447
テスト セットの損失と予測を比較することにより、特徴選択を実行します。すべての予測子を使用して学習させた回帰ニューラル ネットワーク モデルのテスト セット メトリクスを予測子のサブセットのみを使用して学習させたモデルのテスト セット メトリクスと比較します。
標本ファイル fisheriris.csv を読み込みます。これには、アヤメについてのがく片の長さ、がく片の幅、花弁の長さ、花弁の幅、種の種類などのデータが格納されています。ファイルを table に読み込みます。
fishertable = readtable('fisheriris.csv');非層化ホールドアウト分割を使用して、データを学習セット trainTbl とテスト セット testTbl に分割します。観測値の約 30% がテスト データ セット用に予約され、残りの観測値が学習データ セットに使用されます。
rng("default") c = cvpartition(size(fishertable,1),"Holdout",0.3); trainTbl = fishertable(training(c),:); testTbl = fishertable(test(c),:);
学習セット内のすべての予測子を使用して 1 つの回帰ニューラル ネットワーク モデルに学習させ、PetalWidth を除くすべての予測子を使用してもう 1 つのモデルに学習させます。両方のモデルについて、PetalLength を応答変数として指定し、予測子を標準化します。
allMdl = fitrnet(trainTbl,"PetalLength","Standardize",true); subsetMdl = fitrnet(trainTbl,"PetalLength ~ SepalLength + SepalWidth + Species", ... "Standardize",true);
2 つのモデルのテスト セットの平均二乗誤差 (MSE) を比較します。MSE の値が小さいほど、パフォーマンスが優れていることを示します。
allMSE = loss(allMdl,testTbl)
allMSE = 0.0853
subsetMSE = loss(subsetMdl,testTbl)
subsetMSE = 0.0866
各モデルについて、テスト セットの予測される花弁の長さと実際の花弁の長さを比較します。予測される花弁の長さを縦軸に、実際の花弁の長さを横軸に沿ってプロットします。基準線上にある点は予測が正しいことを示します。
tiledlayout(2,1) % Top axes ax1 = nexttile; allPredictedY = predict(allMdl,testTbl); plot(ax1,testTbl.PetalLength,allPredictedY,".") hold on plot(ax1,testTbl.PetalLength,testTbl.PetalLength) hold off xlabel(ax1,"True Petal Length") ylabel(ax1,"Predicted Petal Length") title(ax1,"All Predictors") % Bottom axes ax2 = nexttile; subsetPredictedY = predict(subsetMdl,testTbl); plot(ax2,testTbl.PetalLength,subsetPredictedY,".") hold on plot(ax2,testTbl.PetalLength,testTbl.PetalLength) hold off xlabel(ax2,"True Petal Length") ylabel(ax2,"Predicted Petal Length") title(ax2,"Subset of Predictors")
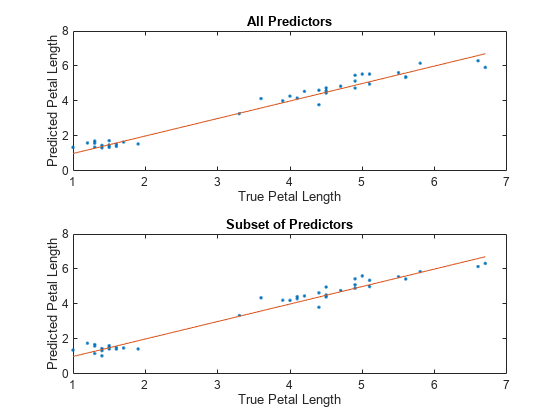
予測が基準線の近くに分布しており、両方のモデルが適切に機能しているようなので、PetalWidth を除くすべての予測子を使用して学習させたモデルを使用することを検討します。
R2024b 以降
複数の応答変数をもつ回帰ニューラル ネットワークを作成します。
carbig データ セットを読み込みます。このデータ セットには、1970 年代と 1980 年代初期に製造された自動車の測定値が格納されています。Displacement や Horsepower などの予測子変数と応答変数の Acceleration および MPG が格納された table を作成します。table の最初の 8 行を表示します。
load carbig cars = table(Displacement,Horsepower,Model_Year, ... Origin,Weight,Acceleration,MPG); head(cars)
Displacement Horsepower Model_Year Origin Weight Acceleration MPG
____________ __________ __________ _______ ______ ____________ ___
307 130 70 USA 3504 12 18
350 165 70 USA 3693 11.5 15
318 150 70 USA 3436 11 18
304 150 70 USA 3433 12 16
302 140 70 USA 3449 10.5 17
429 198 70 USA 4341 10 15
454 220 70 USA 4354 9 14
440 215 70 USA 4312 8.5 14
cars から table に欠損値がある行を削除します。
cars = rmmissing(cars);
米国製かどうかに基づいて、自動車を分類します。
cars.Origin = categorical(cellstr(cars.Origin)); cars.Origin = mergecats(cars.Origin,["France","Japan",... "Germany","Sweden","Italy","England"],"NotUSA");
データを学習セットとテスト セットに分割します。観測値の約 85% をニューラル ネットワーク モデルの学習に使用し、観測値の約 15% を学習済みモデルの新しいデータでの性能のテストに使用します。cvpartition を使用してデータを分割します。
rng("default") % For reproducibility c = cvpartition(height(cars),"Holdout",0.15); carsTrain = cars(training(c),:); carsTest = cars(test(c),:);
学習データ carsTrain を fitrnet 関数に渡して、多重応答ニューラル ネットワーク回帰モデルに学習させます。より良い結果を得るために、予測子データを標準化するように指定します。
Mdl = fitrnet(carsTrain,["Acceleration","MPG"], ... Standardize=true)
Mdl =
RegressionNeuralNetwork
PredictorNames: {'Displacement' 'Horsepower' 'Model_Year' 'Origin' 'Weight'}
ResponseName: {'Acceleration' 'MPG'}
CategoricalPredictors: 4
ResponseTransform: 'none'
NumObservations: 334
LayerSizes: 10
Activations: 'relu'
OutputLayerActivation: 'none'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [1000×7 table]
Properties, Methods
Mdl は学習させた RegressionNeuralNetwork モデルです。ドット表記を使用して Mdl のプロパティにアクセスできます。たとえば、Mdl.ConvergenceInfo と指定すると、モデルの収束についての詳細情報を取得できます。
検定の平均二乗誤差 (MSE) を計算して、テスト セットで回帰モデルの性能を評価します。MSE の値が小さいほど、パフォーマンスが優れていることを示します。名前と値の引数 OutputType を "per-response" に設定して、各応答変数の損失を個別に返します。
testMSE = loss(Mdl,carsTest,["Acceleration","MPG"], ... OutputType="per-response")
testMSE = 1×2
1.6527 5.0171
テスト セット内の観測値に対する応答値を予測します。予測された応答値を table として返します。
predictedY = predict(Mdl,carsTest,OutputType="table")predictedY=58×2 table
Acceleration MPG
____________ ______
8.7832 13.923
15.743 20.402
17.85 17.548
11.146 13.186
13.636 12.322
16.36 17.39
15.882 22.604
12.315 12.999
13.215 12.796
12.443 14.325
16.644 22.815
15.223 24.688
11.499 13.937
12.063 12.067
14.983 11.313
15.436 24.368
⋮