このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
HDL Coder での速度および面積の最適化
HDL Coder™ で面積と速度の最適化を使用して、リソースを節約してターゲット FPGA デバイスでの設計のタイミングを改善します。最適化によって、アルゴリズムの機能的な動作は変わりませんが、設計内の特定のリソースを最適化したり、レイテンシを導入したり、サンプル レートに違いが生じたりする可能性があります。
最初に FPGA プラットフォームで最適化を有効にせずに HDL コードを生成して設計を合成します。設計がタイミング要件を満たさない場合、最適化を有効にして、設計が面積および速度の要件を満たすまでワークフローを再実行します。HDL コード生成のワークフローの基礎を参照してください。
MATLAB HDL コード生成での最適化
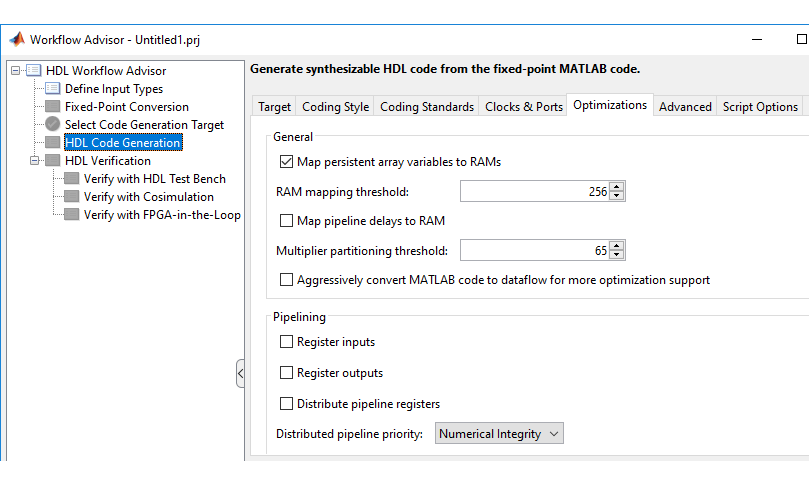
MATLAB® コードで最適化を有効にするには、MATLAB からワークフロー アドバイザーを開きます。アドバイザーの [HDL コード生成] タスクで、[最適化] タブの設定を有効にします。
Simulink HDL コード生成での最適化
モデル レベルとブロック レベルで最適化を有効にできます。以下の場所で、モデルレベルの最適化を指定します。
[コンフィギュレーション パラメーター] ダイアログ ボックスの [HDL コード生成] 、 [最適化] ペイン。
プロパティ値を設定するために、コマンド ラインで関数
makehdlまたはhdlset_paramを使用。Simulink® HDL ワークフロー アドバイザーの [HDL オプションの設定] タスク。[HDL コード生成の設定] ボタンをクリックすると、[コンフィギュレーション パラメーター] ダイアログ ボックスで HDL コード生成の設定が開きます。その後、[HDL コード生成] 、 [最適化] ペインに移動できます。
モデル内のサブシステムは、モデルレベルの最適化設定を継承します。サブシステムの [HDL ブロック プロパティ] ダイアログ ボックスで、または関数 hdlset_param を使用して、サブシステム レベルの設定を変更できます。また、入出力でのパイプラインの追加など、モデルの特定のブロックについて特定の追加設定を指定することもできます。次の表に、ブロック レベルとモデル レベルで利用可能なさまざまな最適化を示します。
| 最適化 | モデル レベル? | サブシステム レベル? | コメント |
|---|---|---|---|
| 遅延の均衡化 | はい | はい | – |
| RAM マッピング | はい | いいえ | – |
| 適応パイプライン | はい | はい | – |
| クロック レート パイプライン | はい | はい | – |
| 分散型パイプライン方式 | はい | はい | – |
| リソース共有 | はい | はい | モデル レベルでは、加算器や乗算器などの共有するリソースの種類を指定できます。ブロック レベルでは、[SharingFactor] を指定します。 |
| ストリーミング | いいえ | はい | – |
最適化の効果を確認するには、以下を実行できます。
HDL コードを使用して最適化レポートを生成できます。このレポートを有効にする方法の詳細については、コード生成レポートの作成と使用を参照してください。
生成されたモデルを開くか、検証モデルを生成します。生成されたモデルは、ブロックの実装と有効にした最適化の効果を示す HDL コードの動作モデルです。生成されたモデルと元のモデルの数値を検証するために、検証モデルを生成できます。生成されたモデルと検証モデルを参照してください。
ヒント
最適化を効率的に使用するには、Constant ブロックのサンプル時間の設定を [Inf] から [-1] に変更します。
一般的な最適化
モデルには設計上の遅延とパイプライン遅延を設定できます。"設計上の遅延" は、モデルに手動で追加する遅延です。"パイプライン遅延" は、ブロック、ニュートン・ラフソン法などのブロックの実装、ネイティブ浮動小数点演算子、または速度の最適化に対して指定されるパイプライン設定によって生じる遅延です。これらの遅延は、生成された HDL コード、生成されたモデル、および検証モデルで確認できます。
一般的な最適化パラメーターには、以下が含まれます。
RAM マッピング: RAM マッピングのパラメーターを使用して、大きな遅延、MATLAB コードの永続変数、およびパイプライン遅延を、しきい値のビット幅に基づいて RAM にマッピングします。Apply RAM Mapping to Optimize Area、RAM へのパイプライン遅延のマッピング、およびRAM マッピングのしきい値も参照してください。
遅延の均衡化: この最適化は既定で有効になっていて、一致する遅延を並列パスに挿入することでパイプライン遅延のバランスを取ります。最適化によって、生成されたモデルと元のモデルの数値が一致します。最適化レポートの [遅延の均衡化] セクションで、この最適化の効果を確認します。HDL Coder での遅延の均衡化の理解を参照してください。
速度の最適化
速度の最適化は、クリティカル パスを最適化することで、ターゲット FPGA での設計のタイミングを改善します。クリティカル パスを特定するために、Generic ASIC/FPGA ワークフローを FPGA デバイスに対して実行してから、クリティカル パスに注釈を付けるか、タイミング レポートを使用します。
クリティカル パスの特定をさらに迅速に行い、クリティカル パスの検索と最適化の反復処理を高速にするには、クリティカル パスの推定を使用します。合成を実行したり、HDL コードを生成したりする必要はありません。クリティカル パスの推定では、ターゲット固有のタイミング データベースのタイミング データを使用した静的タイミング解析を使用します。最適化レポートの [クリティカル パスの推定] セクションで、この最適化の効果を確認します。合成実行なしのクリティカル パスの推定を参照してください。
速度の最適化には、以下が含まれます。
"クロック レート パイプライン": 既定で有効になっていて、[オーバーサンプリング係数] に 1 を超える値を指定するときに、より速いクロック レートでパイプライン レジスタを実行する Simulink 最適化です。サブシステムの階層的境界を削除するためにフラットにした階層と一緒にクロックレート パイプラインを使用して、リタイミングを改善します。クロックレート パイプラインを参照してください。
"分散型パイプライン方式": 既存の遅延であるか、[InputPipeline] と [OutputPipeline] ブロック設定を使用して指定されるレジスタのリタイミングを行う最適化です。既存の遅延を保持するには、設計上の遅延分散を許可設定を無効にします。ハードウェアに対するコンポーネントの機能をより正確に反映することで、分散型パイプラインの精度を高めてターゲット デバイスのクロック速度を上げるには、分散型パイプライン方式で合成タイミング推定を使用します。Use synthesis estimates for distributed pipeliningを参照してください。階層全体でレジスタのリタイミングを行うために、モデルで分散型パイプライン方式を有効にします。最適化レポートの [分散型パイプライン] セクションで、この最適化の効果を確認します。分散型パイプラインの設定の指定を参照してください。
"適応パイプライン": ターゲット FPGA デバイスでブロックを DSP に効率的にマッピングするパターンを作成するために、入出力または特定のブロックの両方の端子でパイプライン レジスタを挿入する Simulink 最適化です。最適化では、ターゲット デバイス、ターゲット周波数、乗算器の語長、および HDL ブロック プロパティの設定を考慮します。最適化レポートの [適応パイプライン] セクションで、この最適化の効果を確認します。適応パイプライン設定の指定を参照してください。
"ループ展開": 生成されたコード内でループ本体の複数のインスタンスをインスタンス化することにより、ループを展開する MATLAB 最適化です。また、ループを部分的に展開することもできます。MATLAB ループの最適化を参照してください。
面積の最適化
面積の最適化は、設計のリソース使用率を削減します。面積について設計を最適化すると、FPGA で設計を実行するときの速度が低下する可能性があります。
面積の最適化には、以下が含まれます。
"リソース共有": 機能的に等価な複数のリソースを特定し、それらを単一のリソースに置き換える面積の最適化です。モデル レベルでは、加算器や乗算器などの共有するリソースを指定します。サブシステム レベルでは、設計内の共有可能なリソースの数に応じて [SharingFactor] を指定します。最適化をクロックレート パイプラインと一緒に使用することで、共有リソースをオーバークロックする方法を指定できます。リソース共有を参照してください。
"ストリーミング": サブシステムで指定する [StreamingFactor] に基づいて、ベクトル データ パスをさらに小さい複数のベクトル データ パスに分割して、ハードウェア リソース消費を削減する Simulink 最適化です。ストリーミングを参照してください。
"ループのストリーム": ループの本体を 1 回インスタンス化し、ループを反復するたびにこのインスタンスを使用することで、ループをストリームする MATLAB 最適化です。ループ本体のインスタンスはオーバーサンプリングされ、生成されたループは元のループと機能的に同等に維持されます。MATLAB ループの最適化を参照してください。