このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
fitrgam
回帰用の一般化加法モデル (GAM) の当てはめ
構文
説明
Mdl = fitrgam(Tbl,ResponseVarName)Tbl に格納されている標本データを使用して学習させた一般化加法モデル Mdl を返します。入力引数 ResponseVarName は、回帰用の応答値が含まれている Tbl 内の変数の名前です。
Mdl = fitrgam(___,Name,Value)'Interactions',5 は、モデルに交互作用項を 5 つ含めるように指定します。名前と値の引数 'Interactions' を使用して、交互作用項のリストを指定することもできます。
[ は、名前と値の引数 Mdl,AggregateOptimizationResults] = fitrgam(___)OptimizeHyperparameters と HyperparameterOptimizationOptions が指定されている場合に、ハイパーパラメーターの最適化の結果が格納された AggregateOptimizationResults も返します。HyperparameterOptimizationOptions の ConstraintType オプションと ConstraintBounds オプションも指定する必要があります。この構文を使用すると、交差検証損失ではなくコンパクトなモデル サイズに基づいて最適化したり、オプションは同じでも制約範囲は異なる複数の一連の最適化問題を実行したりできます。
例
予測子の線形項が格納されている一変量の GAM に学習させます。その後、関数plotLocalEffectsを使用して指定のデータ インスタンスについての予測を解釈します。
データ セット NYCHousing2015 を読み込みます。
load NYCHousing2015データ セットには、2015 年のニューヨーク市における不動産の売上に関する情報を持つ 10 の変数が含まれます。この例では、これらの変数を使用して売価 (SALEPRICE) を解析します。
データ セットを前処理します。外れ値を削除し、datetime 配列 (SALEDATE) を月番号に変換して、応答変数 (SALEPRICE) を最後の列に移動します。
idx = isoutlier(NYCHousing2015.SALEPRICE); NYCHousing2015(idx,:) = []; NYCHousing2015.SALEDATE = month(NYCHousing2015.SALEDATE); NYCHousing2015 = movevars(NYCHousing2015,'SALEPRICE','After','SALEDATE');
table の最初の 3 行を表示します。
head(NYCHousing2015,3)
BOROUGH NEIGHBORHOOD BUILDINGCLASSCATEGORY RESIDENTIALUNITS COMMERCIALUNITS LANDSQUAREFEET GROSSSQUAREFEET YEARBUILT SALEDATE SALEPRICE
_______ ____________ ____________________________ ________________ _______________ ______________ _______________ _________ ________ _________
2 {'BATHGATE'} {'01 ONE FAMILY DWELLINGS'} 1 0 4750 2619 1899 8 0
2 {'BATHGATE'} {'01 ONE FAMILY DWELLINGS'} 1 0 4750 2619 1899 8 0
2 {'BATHGATE'} {'01 ONE FAMILY DWELLINGS'} 1 1 1287 2528 1899 12 0
売価の一変量の GAM に学習させます。BOROUGH、NEIGHBORHOOD、BUILDINGCLASSCATEGORY および SALEDATE の変数をカテゴリカル予測子として指定します。
Mdl = fitrgam(NYCHousing2015,'SALEPRICE','CategoricalPredictors',[1 2 3 9])
Mdl =
RegressionGAM
PredictorNames: {'BOROUGH' 'NEIGHBORHOOD' 'BUILDINGCLASSCATEGORY' 'RESIDENTIALUNITS' 'COMMERCIALUNITS' 'LANDSQUAREFEET' 'GROSSSQUAREFEET' 'YEARBUILT' 'SALEDATE'}
ResponseName: 'SALEPRICE'
CategoricalPredictors: [1 2 3 9]
ResponseTransform: 'none'
Intercept: 3.7518e+05
IsStandardDeviationFit: 0
NumObservations: 83517
Properties, Methods
Mdl は RegressionGAM モデル オブジェクトです。モデル表示には、モデルのプロパティの一部のみが表示されます。プロパティの完全な一覧を表示するには、ワークスペースで変数名 Mdl をダブルクリックします。Mdl の変数エディターが開きます。あるいは、コマンド ウィンドウでドット表記を使用してプロパティを表示できます。たとえば、Mdl の推定された切片 (定数) 項を表示します。
Mdl.Intercept
ans = 3.7518e+05
学習データの最初の観測値について売価を予測し、予測に対する Mdl 内の項のローカルな効果をプロットします。
yFit = predict(Mdl,NYCHousing2015(1,:))
yFit = 4.4421e+05
plotLocalEffects(Mdl,NYCHousing2015(1,:))

関数predictで、最初の観測値の売価を 4.4421e5 として予測します。関数plotLocalEffectsで、予測に対する Mdl 内の項のローカルな効果を示す横棒グラフを作成します。ローカルな効果の各値は、予測売価への各項の寄与を示します。
3 つの異なる方法で、予測子の線形項と交互作用項が格納された一般化加法モデルに学習させます。
入力引数
formulaを使用して交互作用項を指定します。名前と値の引数
'Interactions'を指定します。線形項をもつモデルを構築してから、そのモデルに関数
addInteractionsを使用して交互作用項を追加します。
carbig データ セットを読み込みます。このデータ セットには、1970 年代と 1980 年代初期に製造された自動車の測定値が格納されています。
load carbig予測子変数 (Acceleration、Displacement、Horsepower、および Weight) と応答変数 (MPG) を格納する table を作成します。
tbl = table(Acceleration,Displacement,Horsepower,Weight,MPG);
formula の指定
4 つの線形項 (Acceleration、Displacement、Horsepower、および Weight) と 2 つの交互作用項 (Acceleration*Displacement および Displacement*Horsepower) が格納された GAM に学習させます。'Y ~ terms' という形式の式を使用して項を指定します。
Mdl1 = fitrgam(tbl,'MPG ~ Acceleration + Displacement + Horsepower + Weight + Acceleration:Displacement + Displacement:Horsepower');交互作用項は重要度の順序でモデルに追加されます。Interactions プロパティを使用して、モデル内の交互作用項とそれらが fitrgam でモデルに追加された順序を確認できます。Interactions プロパティを表示します。
Mdl1.Interactions
ans = 2×2
2 3
1 2
Interactions の各行は 1 つの交互作用項を表し、交互作用項の予測子変数の列インデックスを格納します。
'Interactions' の指定
学習データ (tbl) と tbl 内の応答変数の名前を fitrgam に渡し、それ以外のすべての変数の線形項が予測子として含まれるようにします。logical 行列を使用して名前と値の引数 'Interactions' を指定して、2 つの交互作用項 x1*x2 と x2*x3 を含めます。
Mdl2 = fitrgam(tbl,'MPG','Interactions',logical([1 1 0 0; 0 1 1 0])); Mdl2.Interactions
ans = 2×2
2 3
1 2
'Interactions' では、交互作用項の数を指定したり、'all' を指定して利用可能なすべての交互作用項を含めることもできます。fitrgam は、指定された交互作用項の中から p 値が 'MaxPValue' の値以下であるものを特定し、それらをモデルに追加します。'MaxPValue' の既定値は 1 であり、指定したすべての交互作用項がモデルに追加されます。
'Interactions','all' を指定し、名前と値の引数 'MaxPValue' を 0.05 に設定します。
Mdl3 = fitrgam(tbl,'MPG','Interactions','all','MaxPValue',0.05);
Warning: Model does not include interaction terms because all interaction terms have p-values greater than the 'MaxPValue' value, or the software was unable to improve the model fit.
Mdl3.Interactions
ans = 0×2 empty double matrix
Mdl3 には交互作用項が含まれていません。これは、すべての交互作用項に 0.05 より大きな p 値があるか、または交互作用項を追加してもモデルの当てはめが改善されないことを示します。
関数 addInteractions の使用
予測子の線形項が格納されている一変量の GAM に学習させ、学習済みのモデルに関数addInteractionsを使用して交互作用項を追加します。addInteractions の 2 番目の入力引数を fitrgam の名前と値の引数 'Interactions' と同じ方法で指定します。交互作用項のリスト (logical 行列を使用)、交互作用項の数、または 'all' を指定できます。
交互作用項の数を 3 と指定して、学習済みのモデルに上位 3 つの重要な交互作用項を追加します。
Mdl4 = fitrgam(tbl,'MPG');
UpdatedMdl4 = addInteractions(Mdl4,3);
UpdatedMdl4.Interactionsans = 3×2
2 3
1 2
3 4
Mdl4 は一変量の GAM、UpdatedMdl4 は Mdl4 のすべての項と 3 つの追加の交互作用項を格納する更新された GAM です。
fitrgam を使用して、交差検証済みの 10 分割 (既定の交差検証オプション) の GAM に学習させます。その後、kfoldPredict を使用し、学習分割観測値に対して学習をさせたモデルを使用して、検証分割観測値の応答を予測します。
carbig データ セットを読み込みます。このデータ セットには、1970 年代と 1980 年代初期に製造された自動車の測定値が格納されています。
load carbig予測子変数 (Acceleration、Displacement、Horsepower、および Weight) と応答変数 (MPG) を格納する table を作成します。
tbl = table(Acceleration,Displacement,Horsepower,Weight,MPG);
既定の交差検証オプションを使用して交差検証済み GAM を作成します。名前と値の引数 'CrossVal' を 'on' として指定します。
rng('default') % For reproducibility CVMdl = fitrgam(tbl,'MPG','CrossVal','on')
CVMdl =
RegressionPartitionedGAM
CrossValidatedModel: 'GAM'
PredictorNames: {'Acceleration' 'Displacement' 'Horsepower' 'Weight'}
ResponseName: 'MPG'
NumObservations: 398
KFold: 10
Partition: [1×1 cvpartition]
NumTrainedPerFold: [1×1 struct]
ResponseTransform: 'none'
IsStandardDeviationFit: 0
Properties, Methods
関数 fitrgam で 10 分割の RegressionPartitionedGAM モデル オブジェクト CVMdl が作成されます。交差検証時は、以下の手順が実行されます。
データを 10 個のセットに無作為に分割する。
各セットについて、そのセットを検証データとして予約し、他の 9 個のセットを使用してモデルに学習させる。
10 個のコンパクトな学習済みモデルを交差検証済みモデル オブジェクト
RegressionPartitionedGAMのTrainedプロパティに 10 行 1 列の cell ベクトルとして格納する。
既定の交差検証の設定は、名前と値の引数 'CVPartition'、'Holdout'、'KFold'、'Leaveout' を使用してオーバーライドできます。
kfoldPredict を使用して tbl の観測値の応答を予測します。それぞれの観測値に対する応答が、その観測値を使用せずに学習させたモデルを使用して予測されます。
yHat = kfoldPredict(CVMdl);
yHat は数値ベクトルです。最初の 5 つの予測応答を表示します。
yHat(1:5)
ans = 5×1
19.4848
15.7203
15.5742
15.3185
17.8223
回帰損失 (平均二乗誤差) を計算します。
L = kfoldLoss(CVMdl)
L = 17.7248
kfoldLoss から 10 個の分割についての平均二乗誤差の平均が返されます。
名前と値の引数 OptimizeHyperparameters を使用して、GAM のハイパーパラメーターを交差検証に関して最適化します。
carbig データ セットを読み込みます。このデータ セットには、1970 年代と 1980 年代初期に製造された自動車の測定値が格納されています。
load carbig予測子変数 (X) として Acceleration、Displacement、Horsepower および Weight を、応答変数 (Y) として MPG を指定します。
X = [Acceleration,Displacement,Horsepower,Weight]; Y = MPG;
データを学習セットとテスト セットに分割します。観測値の約 80% をモデルの学習に使用し、観測値の約 20% を学習済みモデルの新しいデータでの性能のテストに使用します。cvpartition を使用してデータを分割します。
rng('default') % For reproducibility cvp = cvpartition(length(MPG),'Holdout',0.20); XTrain = X(training(cvp),:); YTrain = Y(training(cvp)); XTest = X(test(cvp),:); YTest = Y(test(cvp));
学習データを関数 fitrgam に渡して回帰用の GAM に学習させ、OptimizeHyperparameters 引数を含めます。InitialLearnRateForPredictors、NumTreesPerPredictor、Interactions、InitialLearnRateForInteractions、および NumTreesPerInteraction の最適な値を fitrgam で求めるため、'auto' として 'OptimizeHyperparameters' を指定します。再現性を得るために、'expected-improvement-plus' の獲得関数を選択します。既定の獲得関数は実行時に決定されるので、結果が異なる場合があります。
rng('default') Mdl = fitrgam(XTrain,YTrain,'OptimizeHyperparameters','auto', ... 'HyperparameterOptimizationOptions', ... struct('AcquisitionFunctionName','expected-improvement-plus'))
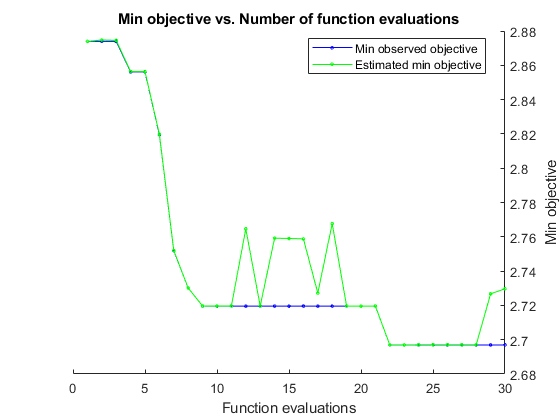
|==========================================================================================================================================================| | Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | InitialLearnRate-| NumTreesPerP-| Interactions | InitialLearnRate-| NumTreesPerI-| | | result | log(1+loss) | runtime | (observed) | (estim.) | ForPredictors | redictor | | ForInteractions | nteraction | |==========================================================================================================================================================| | 1 | Best | 2.874 | 4.6069 | 2.874 | 2.874 | 0.21533 | 500 | 1 | 0.35042 | 13 | | 2 | Accept | 2.89 | 0.20809 | 2.874 | 2.8748 | 0.062841 | 14 | 1 | 0.014907 | 10 | | 3 | Accept | 3.3298 | 1.796 | 2.874 | 2.8746 | 0.001387 | 222 | 0 | - | - | | 4 | Best | 2.8562 | 5.8182 | 2.8562 | 2.8564 | 0.08216 | 434 | 4 | 0.14875 | 283 | | 5 | Accept | 2.976 | 1.8052 | 2.8562 | 2.8564 | 0.99942 | 217 | 1 | 0.0017491 | 34 | | 6 | Best | 2.8195 | 1.382 | 2.8195 | 2.8198 | 0.13778 | 152 | 6 | 0.012566 | 13 | | 7 | Best | 2.7519 | 0.90985 | 2.7519 | 2.752 | 0.12531 | 42 | 4 | 0.27647 | 53 | | 8 | Best | 2.7301 | 3.565 | 2.7301 | 2.7301 | 0.18671 | 10 | 3 | 0.0063418 | 487 | | 9 | Best | 2.7196 | 0.46532 | 2.7196 | 2.7196 | 0.13792 | 10 | 5 | 0.1663 | 27 | | 10 | Accept | 2.8281 | 2.9027 | 2.7196 | 2.7196 | 0.23324 | 10 | 4 | 0.75904 | 314 | | 11 | Accept | 2.7864 | 0.25131 | 2.7196 | 2.7196 | 0.13035 | 10 | 1 | 0.30171 | 476 | | 12 | Accept | 2.7993 | 0.61803 | 2.7196 | 2.7647 | 0.16476 | 10 | 6 | 0.015498 | 32 | | 13 | Accept | 2.7847 | 4.5171 | 2.7196 | 2.7197 | 0.0090953 | 499 | 5 | 0.027878 | 40 | | 14 | Accept | 3.5847 | 0.27508 | 2.7196 | 2.7592 | 0.0035123 | 11 | 3 | 0.011127 | 11 | | 15 | Accept | 2.7237 | 4.9018 | 2.7196 | 2.759 | 0.015848 | 498 | 3 | 0.14359 | 238 | | 16 | Accept | 2.779 | 1.569 | 2.7196 | 2.7588 | 0.012829 | 10 | 3 | 0.028814 | 217 | | 17 | Accept | 2.7761 | 4.7776 | 2.7196 | 2.7272 | 0.023165 | 488 | 1 | 0.32642 | 302 | | 18 | Accept | 2.8604 | 4.1417 | 2.7196 | 2.7677 | 0.013548 | 495 | 2 | 0.97963 | 141 | | 19 | Accept | 3.5466 | 0.12735 | 2.7196 | 2.7196 | 0.019794 | 10 | 0 | - | - | | 20 | Accept | 2.7513 | 7.3431 | 2.7196 | 2.7196 | 0.02408 | 62 | 6 | 0.023502 | 490 | |==========================================================================================================================================================| | Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | InitialLearnRate-| NumTreesPerP-| Interactions | InitialLearnRate-| NumTreesPerI-| | | result | log(1+loss) | runtime | (observed) | (estim.) | ForPredictors | redictor | | ForInteractions | nteraction | |==========================================================================================================================================================| | 21 | Accept | 2.7243 | 0.92354 | 2.7196 | 2.7196 | 0.040761 | 11 | 3 | 0.10556 | 120 | | 22 | Best | 2.6969 | 5.0161 | 2.6969 | 2.697 | 0.0032557 | 494 | 2 | 0.039381 | 487 | | 23 | Accept | 2.8184 | 3.8034 | 2.6969 | 2.697 | 0.0072249 | 19 | 3 | 0.27653 | 494 | | 24 | Accept | 2.7788 | 4.3989 | 2.6969 | 2.697 | 0.0064015 | 482 | 1 | 0.013479 | 479 | | 25 | Accept | 2.7646 | 4.4343 | 2.6969 | 2.6971 | 0.0013222 | 473 | 2 | 0.17272 | 436 | | 26 | Accept | 2.8368 | 0.28304 | 2.6969 | 2.6971 | 0.93418 | 11 | 5 | 0.16983 | 11 | | 27 | Accept | 2.7724 | 1.7205 | 2.6969 | 2.6971 | 0.039216 | 11 | 2 | 0.037865 | 480 | | 28 | Accept | 2.8795 | 0.87918 | 2.6969 | 2.6971 | 0.73103 | 11 | 1 | 0.014567 | 480 | | 29 | Accept | 2.782 | 4.0221 | 2.6969 | 2.7267 | 0.0047632 | 493 | 1 | 0.069346 | 247 | | 30 | Accept | 2.7734 | 0.98578 | 2.6969 | 2.7297 | 0.038679 | 103 | 1 | 0.052986 | 68 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 88.0979 seconds
Total objective function evaluation time: 78.4482
Best observed feasible point:
InitialLearnRateForPredictors NumTreesPerPredictor Interactions InitialLearnRateForInteractions NumTreesPerInteraction
_____________________________ ____________________ ____________ _______________________________ ______________________
0.0032557 494 2 0.039381 487
Observed objective function value = 2.6969
Estimated objective function value = 2.7297
Function evaluation time = 5.0161
Best estimated feasible point (according to models):
InitialLearnRateForPredictors NumTreesPerPredictor Interactions InitialLearnRateForInteractions NumTreesPerInteraction
_____________________________ ____________________ ____________ _______________________________ ______________________
0.0032557 494 2 0.039381 487
Estimated objective function value = 2.7297
Estimated function evaluation time = 5.009
Mdl =
RegressionGAM
ResponseName: 'Y'
CategoricalPredictors: []
ResponseTransform: 'none'
Intercept: 23.7405
Interactions: [2×2 double]
IsStandardDeviationFit: 0
NumObservations: 318
HyperparameterOptimizationResults: [1×1 BayesianOptimization]
Properties, Methods
fitrgam は、最適な推定実行可能点を使用する RegressionGAM モデル オブジェクトを返します。最適な推定実行可能点は、ベイズ最適化プロセスの基となるガウス過程モデルに基づいて交差検証損失 (平均二乗誤差 MSE) の信頼限界の上限を最小化するハイパーパラメーターのセットです。
ベイズ最適化プロセスは、目的関数のガウス過程モデルを内部に保持します。目的関数は、回帰の場合、log(1 + 交差検証 MSE) です。各反復において、最適化プロセスによってガウス過程モデルが更新され、そのモデルを使用して新しいハイパーパラメーターのセットが求められます。反復表示の各行には、新しいハイパーパラメーターのセットと次の列の値が表示されます。
Objective— 新しいハイパーパラメーターのセットにおいて計算された目的関数値。Objective runtime— 目的関数の評価時間。Eval result—Accept、BestまたはErrorとして指定される結果レポート。Acceptは目的関数が有限値を返すことを示し、Errorは目的関数が有限の実数スカラーではない値を返すことを示します。Bestは、目的関数が以前に計算された目的関数値より小さい有限値を返すことを示します。BestSoFar(observed)— それまでに計算された最小の目的関数値。この値は、現在の反復の目的関数値 (現在の反復におけるEval resultの値がBestである場合)、または前回のBest反復の値です。BestSoFar(estim.)— 各反復で、更新されたガウス過程モデルを使用して、それまでに試行されたすべてのハイパーパラメーターのセットにおける目的関数値の信頼限界の上限が推定されます。次に、信頼限界の上限が最小になる点が選択されます。BestSoFar(estim.)の値は、最小点において関数predictObjectiveによって返される目的関数値です。
反復表示の下のプロットは、BestSoFar(observed) と BestSoFar(estim.) の値をそれぞれ青と緑で示しています。
返されるオブジェクト Mdl は、最適な推定実行可能点、つまり、最終的なガウス過程モデルに基づく最後の反復で BestSoFar(estim.) の値を生成するハイパーパラメーターのセットを使用します。
HyperparameterOptimizationResults プロパティの Mdl から最適な推定実行可能点を取得します。
Mdl.HyperparameterOptimizationResults.XAtMinEstimatedObjective
ans=1×5 table
InitialLearnRateForPredictors NumTreesPerPredictor Interactions InitialLearnRateForInteractions NumTreesPerInteraction
_____________________________ ____________________ ____________ _______________________________ ______________________
0.0032557 494 2 0.039381 487
代わりに、関数 bestPoint を使用することもできます。既定では、関数 bestPoint は基準 'min-visited-upper-confidence-interval' を使用します。
[x,CriterionValue,iteration] = bestPoint(Mdl.HyperparameterOptimizationResults)
x=1×5 table
InitialLearnRateForPredictors NumTreesPerPredictor Interactions InitialLearnRateForInteractions NumTreesPerInteraction
_____________________________ ____________________ ____________ _______________________________ ______________________
0.0032557 494 2 0.039381 487
CriterionValue = 2.7908
iteration = 22
また、HyperparameterOptimizationResults プロパティから、または Criterion として 'min-observed' を指定して、最適な観測実行可能点 (つまり、反復表示内の最後の Best 点) を抽出できます。
Mdl.HyperparameterOptimizationResults.XAtMinObjective
ans=1×5 table
InitialLearnRateForPredictors NumTreesPerPredictor Interactions InitialLearnRateForInteractions NumTreesPerInteraction
_____________________________ ____________________ ____________ _______________________________ ______________________
0.0032557 494 2 0.039381 487
[x_observed,CriterionValue_observed,iteration_observed] = bestPoint(Mdl.HyperparameterOptimizationResults,'Criterion','min-observed')
x_observed=1×5 table
InitialLearnRateForPredictors NumTreesPerPredictor Interactions InitialLearnRateForInteractions NumTreesPerInteraction
_____________________________ ____________________ ____________ _______________________________ ______________________
0.0032557 494 2 0.039381 487
CriterionValue_observed = 2.6969
iteration_observed = 22
この例では、2 つの基準がハイパーパラメーターの同じセット (22 回目の反復) を最適な点として選択しています。それぞれの基準値が異なるのは、CriterionValue は最終的なガウス過程モデルによって計算された目的関数値の上限であり、CriterionValue_observed は選択されたハイパーパラメーターを使用して計算された実際の目的関数値であるためです。詳細については、bestPoint の名前と値の引数Criterionを参照してください。
平均二乗誤差 (MSE) を計算して、学習セットおよびテスト セットで回帰モデルの性能を評価します。MSE の値が小さいほど、パフォーマンスが優れていることを示します。
LTraining = resubLoss(Mdl)
LTraining = 6.2224
LTest = loss(Mdl,XTest,YTest)
LTest = 18.5724
関数bayesoptを使用して、GAM のパラメーターを交差検証に関して最適化します。
代わりに、名前と値の引数OptimizeHyperparametersを使用して fitrgam の名前と値の引数の最適な値を特定することもできます。例については、OptimizeHyperparameters を使用した GAM の最適化を参照してください。
carbig データ セットを読み込みます。このデータ セットには、1970 年代と 1980 年代初期に製造された自動車の測定値が格納されています。
load carbig予測子変数 (X) として Acceleration、Displacement、Horsepower および Weight を、応答変数 (Y) として MPG を指定します。
X = [Acceleration,Displacement,Horsepower,Weight]; Y = MPG;
最適化のプロセスのために交差検証セットを決めるには、応答値が欠損している観測値を削除する必要があります。応答変数から欠損値を削除し、予測子変数の対応する観測値を削除します。
[Y,TF] = rmmissing(Y); X = X(~TF);
交差検証用の分割を設定します。これにより、各ステップで最適化に使用される交差検証セットが決まります。
c = cvpartition(length(Y),'KFold',5);ベイズ最適化を使用して最適化する名前と値の引数に合わせてoptimizableVariableオブジェクトを準備します。この例では、fitrgam の引数 MaxNumSplitsPerPredictor と NumTreesPerPredictor の最適な値を調べます。
maxNumSplits = optimizableVariable('maxNumSplits',[1,10],'Type','integer'); numTrees = optimizableVariable('numTrees',[1,500],'Type','integer');
入力として z = [maxNumSplits,numTrees] を受け入れ z の交差検証損失値を返す目的関数を作成します。
minfun = @(z)kfoldLoss(fitrgam(X,Y,'CVPartition',c, ... 'MaxNumSplitsPerPredictor',z.maxNumSplits, ... 'NumTreesPerPredictor',z.numTrees));
交差検証オプションを指定した場合、関数 fitrgam は交差検証済みモデル オブジェクト RegressionPartitionedGAM を返します。関数kfoldLossは、交差検証済みモデルで取得した回帰損失 (平均二乗誤差) を返します。そのため、関数ハンドル minfun は、z のパラメーターで交差検証損失を計算します。
bayesopt を使用して最適なパラメーター [maxNumSplits,numTrees] を求めます。再現性を得るために、'expected-improvement-plus' の獲得関数を選択します。既定の獲得関数は実行時に決定されるので、結果が異なる場合があります。
rng('default') results = bayesopt(minfun,[maxNumSplits,numTrees],'Verbose',0, ... 'IsObjectiveDeterministic',true, ... 'AcquisitionFunctionName','expected-improvement-plus');
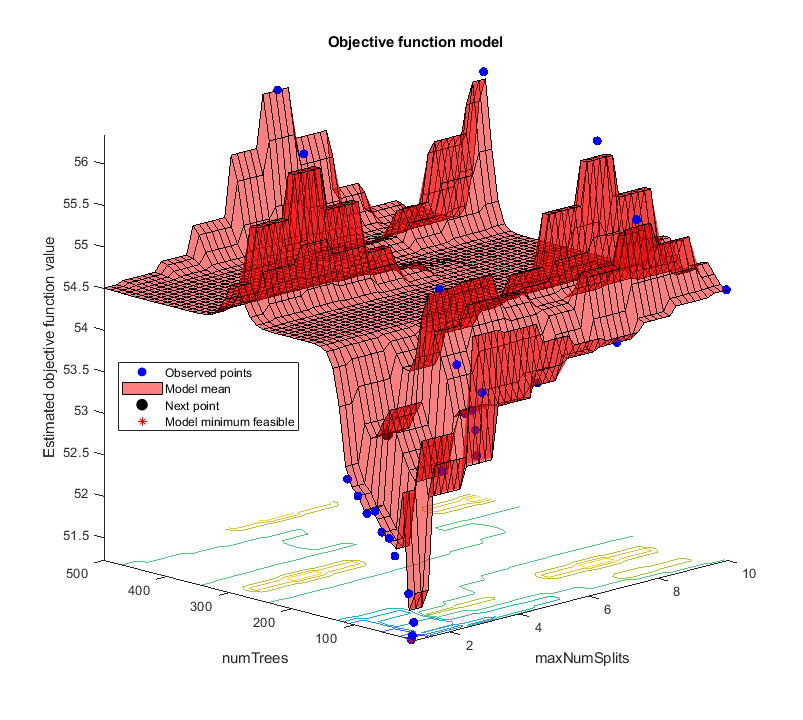
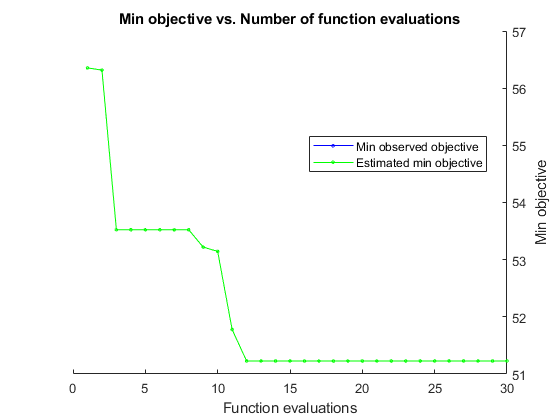
results から最適な点を取得します。
zbest = bestPoint(results)
zbest=1×2 table
maxNumSplits numTrees
____________ ________
1 8
zbest の値を使用して最適化された GAM に学習させます。
Mdl = fitrgam(X,Y, ... 'MaxNumSplitsPerPredictor',zbest.maxNumSplits, ... 'NumTreesPerPredictor',zbest.numTrees);