predictObjective
一連の点における目的関数の予測
説明
例
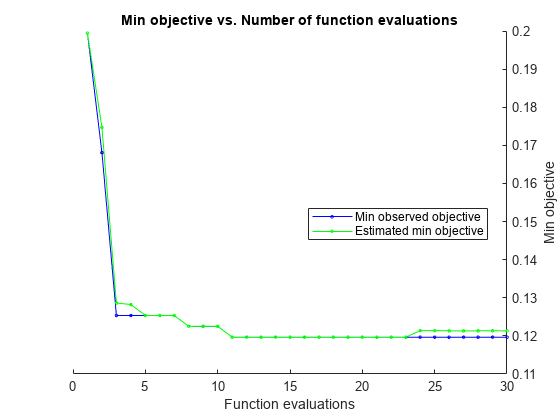
この例では、最適化された分類器の交差検証損失を推定する方法を示します。
ionosphere データの KNN 分類器を最適化します。つまり、交差検証損失が最小になるパラメーターを求めます。1 ~ 30 の最近傍サイズと距離関数 'chebychev'、'euclidean' および 'minkowski' に対して最小化を行います。
再現性を得るため、乱数シードを設定し、AcquisitionFunctionName オプションを 'expected-improvement-plus' に設定します。
load ionosphere rng default num = optimizableVariable('n',[1,30],'Type','integer'); dst = optimizableVariable('dst',{'chebychev','euclidean','minkowski'},'Type','categorical'); c = cvpartition(351,'Kfold',5); fun = @(x)kfoldLoss(fitcknn(X,Y,'CVPartition',c,'NumNeighbors',x.n,... 'Distance',char(x.dst),'NSMethod','exhaustive')); results = bayesopt(fun,[num,dst],'Verbose',0,... 'AcquisitionFunctionName','expected-improvement-plus');

推定する点のテーブルを作成します。
b = categorical({'chebychev','euclidean','minkowski'});
n = [1;1;1;4;2;2];
dst = [b(1);b(2);b(3);b(1);b(1);b(3)];
XTable = table(n,dst);これらの点における目的関数の値と標準偏差を推定します。
[objective,sigma] = predictObjective(results,XTable); [XTable,table(objective,sigma)]
ans=6×4 table
n dst objective sigma
_ _________ _________ _________
1 chebychev 0.12132 0.0068029
1 euclidean 0.14052 0.0079128
1 minkowski 0.14057 0.0079117
4 chebychev 0.1227 0.0068805
2 chebychev 0.12176 0.0066739
2 minkowski 0.1437 0.0075448