groupsummary
グループごとの要約統計量を計算
構文
説明
テーブル データ
G = groupsummary(T,groupvars)T に対応する一意のグループ化変数の組み合わせと各グループのメンバー数を返します。グループは、同じ一意の値の組み合わせをもつ groupvars の変数の行により定義されます。出力 table の各行は 1 つのグループに対応しています。たとえば、G = groupsummary(T,"HealthStatus") は、変数 HealthStatus の各グループの数を含む table を返します。
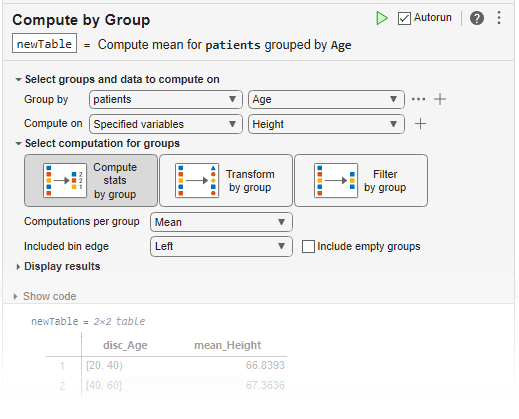
groupsummary の機能を対話的に使用するには、ライブ スクリプトに [グループ別に計算] タスクを追加します。
詳細については、グループ要約の計算を参照してください。
G = groupsummary(___,Name,Value)G = groupsummary(T,"Category1","IncludeMissingGroups",false) は、Category1 の <undefined> で示される categorical 型の欠損データからなるグループを除外します。
配列データ
B = groupsummary(A,groupvars,method)A の一意のグループに method のグループ単位の計算を適用した結果を連結したものを返します。グループは、同じ一意の値の組み合わせをもつ groupvars の列ベクトルの行により定義されます。出力配列の各行は、1 つのグループについての計算結果を含みます。
groupsummary の機能を対話的に使用するには、ライブ スクリプトに [グループ別に計算] タスクを追加します。
B = groupsummary(___,Name,Value)
例
table 変数の要約統計量を計算します。
8 人の個人に関する情報を含む table T を作成します。
HealthStatus = categorical(["Poor"; "Good"; "Fair"; "Fair"; "Poor"; "Excellent"; "Good"; "Excellent"]); Age = [38; 43; 38; 40; 49; 51; 52; 35]; Height = [71; 68; 64; 67; 64; 62; 65; 55]; Weight = [176; 153; 131; 133; 119; 120; 140; 129]; T = table(HealthStatus,Age,Height,Weight)
T=8×4 table
HealthStatus Age Height Weight
____________ ___ ______ ______
Poor 38 71 176
Good 43 68 153
Fair 38 64 131
Fair 40 67 133
Poor 49 64 119
Excellent 51 62 120
Good 52 65 140
Excellent 35 55 129
グループ化変数として HealthStatus を指定して、健康状態グループのカウントを計算します。
G = groupsummary(T,"HealthStatus")G=4×2 table
HealthStatus GroupCount
____________ __________
Excellent 2
Fair 2
Good 2
Poor 2
各健康状態グループの平均年齢、身長、体重を計算します。
G = groupsummary(T,"HealthStatus","mean")
G=4×5 table
HealthStatus GroupCount mean_Age mean_Height mean_Weight
____________ __________ ________ ___________ ___________
Excellent 2 43 58.5 124.5
Fair 2 39 65.5 132
Good 2 47.5 66.5 146.5
Poor 2 43.5 67.5 147.5
健康状態でグループ化して、平均身長のみを計算します。
G = groupsummary(T,"HealthStatus","median","Height")
G=4×3 table
HealthStatus GroupCount median_Height
____________ __________ _____________
Excellent 2 58.5
Fair 2 65.5
Good 2 66.5
Poor 2 67.5
2 つのグループ化変数を使用してテーブル データをグループ化します。
8 人の個人に関する情報を含む table T を作成します。
HealthStatus = categorical(["Poor"; "Good"; "Fair"; "Fair"; "Poor"; "Excellent"; "Good"; "Excellent"]); Smoker = logical([1; 0; 0; 1; 1; 0; 0; 1]); Weight = [176; 153; 131; 133; 119; 120; 140; 129]; T = table(HealthStatus,Smoker,Weight)
T=8×3 table
HealthStatus Smoker Weight
____________ ______ ______
Poor true 176
Good false 153
Fair false 131
Fair true 133
Poor true 119
Excellent false 120
Good false 140
Excellent true 129
健康状態および喫煙状態でグループ化した、平均体重を計算します。既定では、健康状態と喫煙状態の一部の組み合わせは空のグループであるため、出力に表されません。
G = groupsummary(T,["HealthStatus","Smoker"],"mean","Weight")
G=6×4 table
HealthStatus Smoker GroupCount mean_Weight
____________ ______ __________ ___________
Excellent false 1 120
Excellent true 1 129
Fair false 1 131
Fair true 1 133
Good false 2 146.5
Poor true 2 147.5
IncludeEmptyGroups の値を true に設定して、空の組み合わせを含む、すべてのグループの組み合わせを表示します。
G = groupsummary(T,["HealthStatus","Smoker"],"mean","Weight","IncludeEmptyGroups",true)
G=8×4 table
HealthStatus Smoker GroupCount mean_Weight
____________ ______ __________ ___________
Excellent false 1 120
Excellent true 1 129
Fair false 1 131
Fair true 1 133
Good false 2 146.5
Good true 0 NaN
Poor false 0 NaN
Poor true 2 147.5
指定されたビンに従ってデータをグループ化します。
1 か月以内の日数分の売上情報が含まれる timetable を作成します。
TimeStamps = datetime([2017 3 4; 2017 3 2; 2017 3 15; 2017 3 10; ... 2017 3 14; 2017 3 31; 2017 3 25; ... 2017 3 29; 2017 3 21; 2017 3 18]); Profit = [2032 3071 1185 2587 1998 2899 3112 909 2619 3085]'; ItemsSold = [14 13 8 5 10 16 8 6 7 11]'; TT = timetable(TimeStamps,Profit,ItemsSold)
TT=10×2 timetable
04-Mar-2017 2032 14
02-Mar-2017 3071 13
15-Mar-2017 1185 8
10-Mar-2017 2587 5
14-Mar-2017 1998 10
31-Mar-2017 2899 16
25-Mar-2017 3112 8
29-Mar-2017 909 6
21-Mar-2017 2619 7
18-Mar-2017 3085 11
品目番号の区間にグループをビン化し、販売済み品目別にビン化された利益の平均とモードを計算します。
format shorte G = groupsummary(TT,"ItemsSold",[0 4 8 12 16],{"mean","mode"},"Profit")
G=3×4 table
[4, 8) 3 2.0383e+03 909
[8, 12) 4 2.3450e+03 1185
[12, 16] 3 2.6673e+03 2032
曜日別にグループ化された平均利益を計算します。
G = groupsummary(TT,"TimeStamps","dayname","mean","Profit")
G=5×3 table
Tuesday 2 2.3085e+03
Wednesday 2 1.0470e+03
Thursday 1 3.0710e+03
Friday 2 2.7430e+03
Saturday 3 2.7430e+03
日付のベクトルと、対応する利益額のベクトルを作成します。
TimeStamps = datetime([2017 3 4; 2017 3 2; 2017 3 15; 2017 3 10; ... 2017 3 14; 2017 3 31; 2017 3 25; ... 2017 3 29; 2017 3 21; 2017 3 18]); Profit = [2032 3071 1185 2587 1998 2899 3112 909 2619 3085]';
各曜日の平均利益を計算します。各グループの平均、グループ名、メンバー数を表示します。
format shorte [meanDailyProfit,dayOfWeek,dailyCounts] = groupsummary(Profit,TimeStamps,"dayname","mean")
meanDailyProfit = 5×1
2.3085e+03
1.0470e+03
3.0710e+03
2.7430e+03
2.7430e+03
dayOfWeek = 5×1 categorical
Tuesday
Wednesday
Thursday
Friday
Saturday
dailyCounts = 5×1
2
2
1
2
3
健康状態と喫煙状況によりグループ化された集団の平均体重を計算します。
個人に関する情報を異なるタイプの 3 つのベクトルとして保存します。
HealthStatus = categorical(["Poor"; "Good"; "Fair"; "Fair"; "Poor"; "Excellent"; "Good"; "Excellent"]); Smoker = logical([1; 0; 0; 1; 1; 0; 0; 1]); Weight = [176; 153; 131; 133; 119; 120; 140; 129];
健康状態と喫煙状況でグループ化し、平均体重を計算します。
B には各グループの平均値 (空のグループの場合は NaN) が格納されます。BG は、行基準で要素を見た場合のグループを表す 2 つのベクトルを含む cell 配列です。たとえば、BG{1} の最初の行からは、最初のグループの患者の健康状態が Excellent であることがわかり、BG{2} の最初の行からは、これらの患者が非喫煙者であることがわかります。最後に、BC には、BG の対応する各グループのメンバー数が格納されます。
[B,BG,BC] = groupsummary(Weight,{HealthStatus,Smoker},"mean","IncludeEmptyGroups",true);
BB = 8×1
120.0000
129.0000
131.0000
133.0000
146.5000
NaN
NaN
147.5000
BG{1}ans = 8×1 categorical
Excellent
Excellent
Fair
Fair
Good
Good
Poor
Poor
BG{2}ans = 8×1 logical array
0
1
0
1
0
1
0
1
BC
BC = 8×1
1
1
1
1
2
0
0
2
患者情報を含むデータを読み込み、各患者のいる場所、収縮期および拡張期の血圧、身長、体重を記述する table を作成します。
load patients
Location = categorical(Location);
T = table(Location,Systolic,Diastolic,Height,Weight)T=100×5 table
Location Systolic Diastolic Height Weight
_________________________ ________ _________ ______ ______
County General Hospital 124 93 71 176
VA Hospital 109 77 69 163
St. Mary's Medical Center 125 83 64 131
VA Hospital 117 75 67 133
County General Hospital 122 80 64 119
St. Mary's Medical Center 121 70 68 142
VA Hospital 130 88 64 142
VA Hospital 115 82 68 180
St. Mary's Medical Center 115 78 68 183
County General Hospital 118 86 66 132
County General Hospital 114 77 68 128
St. Mary's Medical Center 115 68 66 137
VA Hospital 127 74 71 174
VA Hospital 130 95 72 202
St. Mary's Medical Center 114 79 65 129
VA Hospital 130 92 71 181
⋮
場所でグループ化し、患者の身長と体重の間の相関と収縮期および拡張期の血圧の間の相関を計算します。相関を計算する方法として関数 xcov を使用します。xcov の最初の 2 つの入力引数は相関するデータを記述し、3 番目の引数はラグ サイズを記述し、4 番目の引数は正規化の種類を記述します。各グループ計算で、xcov に渡される引数 x と y は、2 つの cell 要素 ["Height","Systolic"] と ["Weight","Diastolic"] の変数によってペアで指定されます。
G = groupsummary(T,"Location",@(x,y) xcov(x,y,0,"coeff"),{["Height","Systolic"],["Weight","Diastolic"]})
G=3×4 table
Location GroupCount fun1_Height_Weight fun1_Systolic_Diastolic
_________________________ __________ __________________ _______________________
County General Hospital 39 0.65483 0.44187
St. Mary's Medical Center 24 0.62047 0.44466
VA Hospital 37 0.78438 0.62256
あるいは、データが table ではなくベクトルまたは行列形式である場合、相関するデータを groupsummary の最初の入力引数として提供できます。
[B,BG,BC] = groupsummary({[Height,Systolic],[Weight,Diastolic]},Location,@(x,y) xcov(x,y,0,"coeff"))B = 3×2
0.6548 0.4419
0.6205 0.4447
0.7844 0.6226
BG = 3×1 categorical
County General Hospital
St. Mary's Medical Center
VA Hospital
BC = 3×1
39
24
37
入力引数
入力 table。table または timetable として指定します。
入力配列。列ベクトル、行列として保存された列ベクトルのグループ、または列ベクトル、文字の行ベクトル、行列の cell 配列として指定します。
複数の入力引数を受け入れる method の関数ハンドルを指定する場合、入力配列 A は列ベクトル、文字の行ベクトル、行列の cell 配列でなければなりません。グループ単位での関数の各呼び出しでは、入力引数は cell 配列の各要素の対応する列です。以下に例を示します。
groupsummary({x1,y1},groupvars,@(x,y) myFun(x,y))は各グループのmyFun(x1,y1)を計算します。groupsummary({[x1 x2],[y1 y2]},groupvars,@(x,y) myFun(x,y))は最初に各グループのmyFun(x1,y1)を計算し、次に各グループのmyFun(x2,y2)を計算します。
グループ化変数またはベクトル。次のオプションのいずれかとして指定します。
配列の入力データの場合、
groupvarsはAと同じ行数をもつ列ベクトルか、行列内あるいは cell 配列内に配置した列ベクトルのグループのいずれかにすることができます。入力データが table または timetable の場合、
groupvarsはデータ内のグループの計算にどの変数を使用するかを表します。グループ化変数は、次の表のオプションのいずれかを使用して指定できます。インデックス方式 指定する値 例 変数名
string スカラーまたは文字ベクトル
string 配列または文字ベクトルの cell 配列
patternオブジェクト
"A"または'A'—Aという名前の変数["A" "B"]または{'A','B'}—AおよびBという名前の 2 つの変数"Var"+digitsPattern(1)—"Var"の後に数字 1 桁が続く名前の変数
変数インデックス
table 内の変数の位置を参照するインデックス番号
数値のベクトル
logicalベクトル。通常、このベクトルの長さは変数の数と同じですが、末尾の0(false) 値は省略できます。
3— table の 3 番目の変数[2 3]— table の 2 番目と 3 番目の変数[false false true]— 3 番目の変数
関数ハンドル
入力として table 変数を取り、
logicalスカラーを返す関数ハンドル
@isnumeric— 数値を含んでいるすべての変数
変数の型
指定した型の変数を選択する
vartype添字
vartype("numeric")— 数値を含んでいるすべての変数
例: groupsummary(T,"Var3")
計算メソッド。次の値のいずれかとして指定します。
メソッド | 説明 |
|---|---|
"sum" | 総和 |
"mean" | 平均値 |
"median" | 中央値 |
"mode" | モード |
"var" | 分散 |
"std" | 標準偏差 |
"min" | 最小値 |
"max" | 最大値 |
"range" | 最大値から最小値を引いた値 |
"nummissing" | 欠損要素の数 |
"numunique" | 異なる非欠損要素の数 |
"nnz" | 非ゼロと非 |
"all" | 前述のすべての計算 |
最初の次元の長さが 1 であるグループごとに 1 つの出力を返す関数ハンドルとして method を指定することもできます。table 入力データの場合、関数はそれぞれの table 変数に対して個別に演算を行います。
入力データが table T であり、複数の入力引数を受け入れる method の関数ハンドルを指定する場合、datavars を指定しなければなりません。datavars 引数は、cell 配列 (その要素が、メソッドへの各入力に使用する table 変数を示す) でなければなりません。グループ単位での関数の各呼び出しでは、入力引数は cell 配列の要素の対応する table 変数です。以下に例を示します。
groupsummary(T,groupvars,@(x,y) myFun(x,y),{"x1","y1"})は各グループのmyFun(T.x1,T.y1)を計算します。groupsummary(T,groupvars,@(x,y) myFun(x,y),{["x1" "x2"],["y1" "y2"]})は最初に各グループのmyFun(T.x1,T.y1)を計算し、次に各グループのmyFun(T.x2,T.y2)を計算します。
入力データがベクトルまたは行列であり、複数の入力引数を受け入れる method の関数ハンドルを指定する場合、入力データ A はベクトルまたは行列の cell 配列でなければなりません。関数の各呼び出しでは、入力引数は cell 配列の各要素の対応する列です。以下に例を示します。
groupsummary({x1,y1},groupvars,@(x,y) myFun(x,y))は各グループのmyFun(x1,y1)を計算します。groupsummary({[x1 x2],[y1 y2]},groupvars,@(x,y) myFun(x,y))は最初に各グループのmyFun(x1,y1)を計算し、次に各グループのmyFun(x2,y2)を計算します。
一度に複数の計算を指定するには、{"mean","median"} または {myFun1,myFun2} などのように cell 配列にオプションをリストします。
入力データ内の NaN 値は、"nummissing" を除いて、ここで説明されているメソッド名を使用すると自動的に省略されます。NaN 値を含めるには、メソッドで "sum" の代わりに @sum などの関数ハンドルを使用します。
データ型: char | string | cell | function_handle
演算の対象とする table 変数。次の表のオプションのいずれかとして指定します。datavars は、メソッドを適用する入力 table または timetable の変数を示します。datavars で指定されていないその他の変数は演算されず、出力に渡されません。datavars が指定されない場合、groupsummary はそれぞれの非グループ化変数を処理します。
| インデックス方式 | 指定する値 | 例 |
|---|---|---|
変数名 |
|
|
変数インデックス |
|
|
関数ハンドル |
|
|
変数の型 |
|
|
入力データが table T であり、複数の入力引数を受け入れる method の関数ハンドルを指定する場合、datavars を指定しなければなりません。datavars 引数は、その要素がこの表のオプションのいずれかである cell 配列でなければなりません。cell 配列の要素は、メソッドへの各入力に使用する table 変数を示します。グループ単位での関数の各呼び出しでは、入力引数は cell 配列の要素の対応する table 変数です。以下に例を示します。
groupsummary(T,groupvars,@(x,y) myFun(x,y),{"x1","y1"})は各グループのmyFun(T.x1,T.y1)を計算します。groupsummary(T,groupvars,@(x,y) myFun(x,y),{["x1" "x2"],["y1" "y2"]})は最初に各グループのmyFun(T.x1,T.y1)を計算し、次に各グループのmyFun(T.x2,T.y2)を計算します。
例: groupsummary(T,groupvars,method,["Var1" "Var2" "Var4"])
グループ化変数またはベクトルのビン化スキーム。以下の 1 つ以上のビン化方法として指定します。グループ化変数またはベクトルとビン化スキーム引数は同じサイズでなければなりませんが、いずれかをスカラーにすることもできます。
"none"— ビン化なし。ビンのエッジのベクトル — ビンのエッジはビンを定義します。エッジは、数値として指定するか、
datetimeグループ化変数またはベクトルのdatetime値として指定できます。ビンの数 — この数字は、作成する等間隔のビンの数を決定します。ビンの数を正の整数スカラーとして指定できます。
時間の長さ (ビンの幅) — この時間の長さは各ビンの幅を決定します。ビンの幅は、
datetimeまたはdurationグループ化変数またはベクトルのdurationまたはcalendarDurationスカラーとして指定できます。時間単位の名前 (ビンの幅) — この時間単位の名前は各ビンの幅を決定します。ビンの幅は、
datetimeまたはdurationグループ化変数またはベクトルについての以下の表のいずれかのオプションとして指定できます。値 説明 データ型 "second"各ビンは 1 秒です。
datetimeとduration"minute"各ビンは 1 分です。
datetimeとduration"hour"各ビンは 1 時間です。
datetimeとduration"day"各ビンは 1 カレンダー日です。この値には、夏時間のシフトが考慮されます。
datetimeとduration"week"各ビンは 1 カレンダー週です。 datetimeのみ"month"各ビンは 1 カレンダー月です。 datetimeのみ"quarter"各ビンは 1 カレンダー四半期です。 datetimeのみ"year"各ビンは 1 カレンダー年です。この値には、うるう日が考慮されます。
datetimeとduration"decade"各ビンは 10 年 (10 カレンダー年) です。 datetimeのみ"century"各ビンは 1 世紀 (100 カレンダー年) です。 datetimeのみ"secondofminute"ビンは 0 から 59 までの秒です。
datetimeのみ"minuteofhour"ビンは 0 から 59 までの分です。
datetimeのみ"hourofday"ビンは 0 から 23 までの時間です。
datetimeのみ"dayofweek"ビンは 1 から 7 までの曜日です。週の始まりは日曜日です。
datetimeのみ"dayname"ビンは "Sunday"などの完全な曜日名です。datetimeのみ"dayofmonth"ビンは 1 から 31 までの日です。 datetimeのみ"dayofyear"ビンは 1 から 366 までの日です。 datetimeのみ"weekofmonth"ビンは 1 から 6 までの週です。 datetimeのみ"weekofyear"ビンは 1 から 54 までの週です。 datetimeのみ"monthname"ビンは "January"などの完全な月名です。datetimeのみ"monthofyear"ビンは 1 から 12 までの月です。
datetimeのみ"quarterofyear"ビンは 1 から 4 までの四半期です。 datetimeのみ
例: G = groupsummary(T,"Var1",[-Inf 0 Inf])
例: G = groupsummary(T,["Var1" "Var2"],{"none" "year"})
名前と値の引数
オプションの引数のペアを Name1=Value1,...,NameN=ValueN として指定します。ここで、Name は引数名で、Value は対応する値です。名前と値の引数は他の引数の後に指定しなければなりませんが、ペアの順序は重要ではありません。
例: G = groupsummary(T,groupvars,groupbins,IncludedEdge="right")
R2021a より前では、コンマを使用して名前と値をそれぞれ区切り、Name を引用符で囲みます。
例: G = groupsummary(T,groupvars,groupbins,"IncludedEdge","right")
ビン化スキームに含めるビン エッジ。"left" または "right" のいずれかとして指定し、ビン区間のどちらの端が含まれるかを示します。
IncludedEdge を指定できるのは、groupbins も指定し、かつその値がすべてのグループ化変数またはベクトルのすべてのビン化方法に適用される場合のみです。
欠損値をグループとして処理するオプション。数値または logical 1 (true) または 0 (false) として指定します。IncludeMissingGroups が true の場合、groupsummary はグループ化変数またはベクトルに含まれる欠損値 (NaN など) をグループとして処理します。グループ化変数またはベクトルに欠損値が含まれていない場合、または IncludeMissingGroups が false の場合、groupsummary は欠損値をグループとして処理しません。
グループ要約操作に空のグループを含めるオプション。数値または logical 0 (false) または 1 (true) として指定します。IncludeEmptyGroups が false の場合、groupsummary は空のグループを除外します。IncludeEmptyGroups が true の場合、groupsummary は空のグループを含めます。
空のグループは次の場合に発生します。
グループ化変数またはベクトルの可能な値が入力データ (categorical、logical、ビン化された数値変数またはベクトルなど) で表されていない。たとえば、入力 table に logical グループ化変数の
trueの値を含む行がない場合、trueは空のグループを定義します。グループ化変数またはベクトルの一意の組み合わせが入力データで表されていない。たとえば、入力 table にグループ化変数
Aの値がA1かつグループ化変数Bの値がB1である行がない場合、A1_B1は空のグループを定義します。
出力引数
table または timetable 入力データの出力 table。G には計算されたグループ、各グループの要素数、および method を指定した場合は指定した計算の結果が含まれます。
配列の入力データの出力配列。ベクトルまたは行列として返されます。B にはグループ別に指定された計算が含まれます。複数の方法を指定した場合、groupsummary はリストされた順序で計算を横方向に連結します。
配列の入力データのグループ。列ベクトルまたは列ベクトルの cell 配列として返されます。グループ化ベクトルが 1 つの場合、"sorted" オプションを指定した関数 unique により返された順序に従って、出力グループが並べ替えられます。
入力ベクトルが複数ある場合、BG は長さの等しい列ベクトルを含む cell 配列になります。各グループの情報は、BG のすべてのベクトルにまたがる行の要素に格納されます。各グループは、出力配列 B の対応する行にマッピングされます。
配列の入力データのグループ カウント。列ベクトルとして返されます。BC には各グループの要素数が含まれます。BC の長さは、BG で返されるグループ列ベクトルの長さと同じです。
詳細
この表はグループ要約の計算を示します。
サンプル表 T | 構文の例 | 結果の表 |
|---|---|---|
| | groupsummary(T,"VarA") | |
groupsummary(T,"VarA","mean") | | |
groupsummary(T,["VarA" "VarB"],{"none",[-Inf 0 Inf]},"min") | | |
groupsummary(T,"VarA",["mean" "median" "mode"],"VarB") | |
ヒント
groupsummaryを何度も呼び出す場合、可能であればパフォーマンス向上のためグループ変数をcategorical型またはlogical型に変換することを検討してください。たとえば、string 配列のグループ化変数 (要素が"Poor"、"Fair"、"Good"、"Excellent"であるHealthStatusなど) がある場合、categorical(HealthStatus)コマンドを使用してこれを categorical 変数に変換することができます。関数
groupsummaryは 1 次元の要約統計量を計算します。2 次元のグループ化された要約を計算する場合は、pivot関数の使用を検討してください。
代替機能
拡張機能
groupsummary 関数は tall 配列をサポートしていますが、以下の使用上の注意および制限があります。
Aとgroupvarsが両方とも tall 行列の場合、その行数は同じでなければなりません。最初の入力が tall 行列の場合、
groupvarsを tall グループ化ベクトルを含む cell 配列にすることができます。引数
groupvarsと引数datavarsは関数ハンドルをサポートしていません。名前と値の引数
IncludeEmptyGroupsはサポートされていません。"median"、"mode"、および"numunique"メソッドはサポートされておらず、"all"メソッドを指定した場合に含まれません。tall datetime 配列の場合、
"std"メソッドはサポートされていません。引数
methodが関数ハンドルの場合は、tall 配列を扱うsplitapplyの有効な入力でなければなりません。関数ハンドルが複数の入力を受け入れる場合、groupsummaryへの最初の入力は tall table でなければなりません。グループの順序は、インメモリ
groupsummaryの計算と比べ異なっている場合があります。離散化された datetime 配列によってグループ化する場合、カテゴリのグループ名はインメモリ
groupsummary計算と比べ異なっています。
詳細については、tall 配列を参照してください。
使用上の注意および制限:
スパース入力はサポートされません。
datetime データと duration データの場合、ビン化スキームはサポートされません。
可変サイズのコンテンツが格納された異種混合 cell 配列は入力データとしてサポートされません。
多次元配列が含まれる入力 table はサポートされません。
文字ベクトルの cell 配列、または cell 配列の cell 配列が含まれる入力データはサポートされません。
計算メソッドは定数でなければなりません。
最初の入力引数が table である場合、グループ化変数は定数でなければなりません。
データ変数は定数でなければなりません。
データ変数は入れ子の table にはできません。
文字ベクトルまたは string として指定するビン化スキームは定数でなければなりません。
名前と値の引数は定数でなければなりません。
計算メソッドはスパース、多次元、または cell 配列の結果を返すことはできません。
グループ変数の数が実行時に変動する可能性がある場合、2 番目の出力
BGは cell 配列です。
使用上の注意および制限については、「C/C++ コード生成」セクションを参照してください。GPU コード生成にも同様の、使用上の注意および制限が適用されます。
groupsummary 関数はスレッドベースの環境を完全にサポートしています。詳細については、スレッドベースの環境での MATLAB 関数の実行を参照してください。
バージョン履歴
R2018a で導入groupsummary 関数で、グループ化変数またはグループ化ベクトルの型が数値または string のときのパフォーマンスが向上しています。
この向上は、グループ化変数またはグループ化ベクトルが数値の場合は、要素の総数とグループごとの要素数が多いときに最も顕著です。グループ化変数またはグループ化ベクトルの型が string の場合は、要素の総数が多く、グループごとの要素数が少ないときに向上が最も顕著になります。
たとえば、次のコードでは、長さが 12,500,000 でグループ数が 25 の数値ベクトルについて、グループ単位の平均を計算しています。以前のリリースと比較して、このコードは約 7.1 倍速くなっています。
function timingTest numberOfGroups = 25; elementsPerGroup = 5e5; groups = repmat(1:numberOfGroups,1,elementsPerGroup)'; data = randn(numel(groups),1); G = @() groupsummary(data,groups,"mean"); t = timeit(G) end
おおよその実行時間は以下のとおりです。
R2025b: 1.35 秒
R2026a: 0.19 秒
このコードの時間測定では、Windows® 11、AMD EPYC™ 74F3 24 コア プロセッサ (3.19 GHz) 搭載のテスト システムで、関数 timingTest を呼び出しました。
groupsummary 関数で、"sum"、"mean"、"min"、または "max" の計算メソッドを 2 つ以上指定する場合のパフォーマンスが向上しています。特に、グループごとのデータ点の数が少ない場合です。
たとえば、以下のコードでは、1 つのデータ変数と 1 つのグループ化変数をもつ table の総和と最大値を計算します。以前のリリースと比較して、このコードは約 6.6 倍速くなっています。
function timingTest data = rand(1000,1); groups = categorical(randi(500,[1000 1])); for i = 1:1200 groupsummary(data,groups,["sum" "max"]); end end
おおよその実行時間は以下のとおりです。
R2024b: 2.11 秒
R2025a: 0.32 秒
このコードの時間測定では、Windows 11、AMD EPYC 74F3 24 コア プロセッサ (3.19 GHz) 搭載のテスト システムで、関数 timeit を使用しました。
timeit(@timingTest)
ビン化方法の cell 配列を指定して、1 つのグループ化変数またはベクトルに複数のビン化方法を適用します。
データの各グループの異なる非欠損要素の数を計算します。"numunique" または "all" 計算メソッドを指定します。
以前のリリースの計算メソッドに加えて、計算メソッド "all" では、一意の値の数が返されるようになりました。
文字配列には、標準欠損値の既定の定義がありません。このため、nummissing メソッドは、空白文字の配列要素 (' ') を非欠損として扱います。
関数 groupsummary の C または C++ コードを生成します。使用上の注意および制限については、C/C++ コード生成を参照してください。
関数 groupsummary は、特に各グループのデータ数が少ない場合に、パフォーマンスが向上しています。
たとえば、次のコードでは、それぞれ 10 カウントの 500 のグループをもつ行列に対してグループ要約の計算を実行しています。直前のリリースと比較して、このコードは約 2.70 倍速くなっています。
function timingGroupsummary data = (1:5000)'; groups = repelem(1:length(data)/10,10)'; p = randperm(length(data)); data = data(p); groups = groups(p); tic for k = 1:300 G = groupsummary(data,groups,"mean"); end toc end
おおよその実行時間は以下のとおりです。
R2021b: 2.65 秒
R2022a: 0.98 秒
このコードの時間測定では、Windows 10、Intel® Xeon® CPU E5-1650 v4 @ 3.60 GHz を使用するテスト システムで、関数 timingGroupsummary を呼び出しました。
"nummissing" および "nnz" メソッドで、標準欠損値の既定の定義がない入力データ型を使用してもエラーは発生しないようになりました。
このような入力に対して MATLAB がスローしていたエラーを使用するコード (try/catch ブロック内のコードなど) は、そうしたエラーをキャッチしなくなる可能性があります。
参考
関数
pivot|grouptransform|groupfilter|groupcounts|summary|findgroups|splitapply|discretize|varfun|rowfun|convertvars|vartype|numunique
ライブ エディター タスク
MATLAB Command
You clicked a link that corresponds to this MATLAB command:
Run the command by entering it in the MATLAB Command Window. Web browsers do not support MATLAB commands.
Web サイトの選択
Web サイトを選択すると、翻訳されたコンテンツにアクセスし、地域のイベントやサービスを確認できます。現在の位置情報に基づき、次のサイトの選択を推奨します:
また、以下のリストから Web サイトを選択することもできます。
最適なサイトパフォーマンスの取得方法
中国のサイト (中国語または英語) を選択することで、最適なサイトパフォーマンスが得られます。その他の国の MathWorks のサイトは、お客様の地域からのアクセスが最適化されていません。
南北アメリカ
- América Latina (Español)
- Canada (English)
- United States (English)
ヨーロッパ
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)