このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
grouptransform
グループごとの変換
構文
説明
テーブル データ
G = grouptransform(T,groupvars,method)T の非グループ化変数の代わりに変換後のデータを返します。method のグループ単位の計算がそれぞれの非グループ化変数に適用されます。グループは、同じ一意の値の組み合わせをもつ groupvars の変数の行により定義されます。たとえば、G = grouptransform(T,"HealthStatus","norm") は 2 ノルムを使用して、T のデータを健康状態を基準として正規化します。
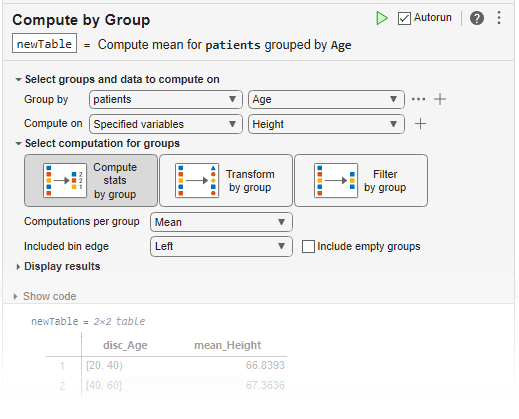
grouptransform の機能を対話的に使用するには、ライブ スクリプトに [グループ別に計算] タスクを追加します。
G = grouptransform(___,Name,Value)G = grouptransform(T,"Temp","linearfill","ReplaceValues",false) は、非グループ化変数を置き換えず、埋め込みデータを T の追加変数として追加します。
配列データ
B = grouptransform(A,groupvars,method)A の列ベクトルの代わりに変換後のデータを返します。method のグループ単位の計算が A のすべての列ベクトルに適用されます。グループは、同じ一意の値の組み合わせをもつ groupvars の列ベクトルの行により定義されます。
grouptransform の機能を対話的に使用するには、ライブ スクリプトに [グループ別に計算] タスクを追加します。
B = grouptransform(___,Name,Value)
例
入力引数
名前と値の引数
出力引数
ヒント
grouptransformを何度も呼び出す場合、可能であればパフォーマンス向上のためグループ変数をcategorical型またはlogical型に変換することを検討してください。たとえば、string 配列のグループ化変数 (要素が"Poor"、"Fair"、"Good"、"Excellent"であるHealthStatusなど) がある場合、categorical(HealthStatus)コマンドを使用してこれを categorical 変数に変換することができます。
代替機能
拡張機能
バージョン履歴
R2018b で導入参考
関数
groupsummary|groupfilter|groupcounts|findgroups|splitapply|discretize|varfun|rowfun