このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
groupcounts
グループの要素数
構文
説明
テーブル データ
G = groupcounts(T,groupvars)T に対応する一意のグループ化変数の組み合わせ、各グループのメンバー数、各グループが表すデータのパーセンテージ ([0, 100] の範囲) を返します。グループは、同じ一意の値の組み合わせをもつ groupvars の変数の行により定義されます。出力 table の各行は 1 つのグループに対応しています。たとえば、G = groupcounts(T,"HealthStatus") は、変数 HealthStatus の各グループの数とパーセンテージを含む table を返します。
詳細については、グループ カウントの計算を参照してください。
G = groupcounts(___,Name,Value)G = groupcounts(T,"Category1","IncludeMissingGroups",false) は、Category1 の <undefined> で示される categorical 型の欠損データからなるグループを除外します。
配列データ
B = groupcounts(___,Name,Value)
例
入力引数
名前と値の引数
出力引数
詳細
この表はグループ カウントの計算を示します。
サンプル表 T | 構文の例 | 結果の表 |
|---|---|---|
|
| groupcounts(T,"VarA") |
|
groupcounts(T,["VarA" "VarB"],{"none",[-Inf 0 Inf]}) |
|

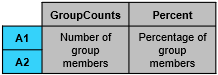
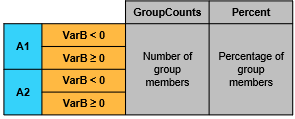
ヒント
groupcountsを何度も呼び出す場合、可能であればパフォーマンス向上のためグループ変数をcategorical型またはlogical型に変換することを検討してください。たとえば、string 配列のグループ化変数 (要素が"Poor"、"Fair"、"Good"、"Excellent"であるHealthStatusなど) がある場合、categorical(HealthStatus)コマンドを使用してこれを categorical 変数に変換することができます。
拡張機能
バージョン履歴
R2019a で導入参考
関数
pivot|grouptransform|groupsummary|groupfilter|findgroups|splitapply|discretize|varfun|rowfun