table でのグループ別の計算の実行
table 変数内のデータ グループに対して計算を実行できます。このような計算では、1 つ以上の table 変数をデータ グループに分割し、各グループに対して計算を実行し、結果を 1 つ以上の出力変数に結合します。MATLAB® には、データをグループに分割して結果を結合する関数がいくつか用意されています。必要なのは、データが格納されている table 変数、グループを定義する変数、データ グループに適用する関数を指定することだけです。
たとえば次の図は、数値 table 変数を 2 つのデータ グループに分け、各グループの平均を計算し、その平均値を出力変数にまとめる単純なグループ化計算を示しています。
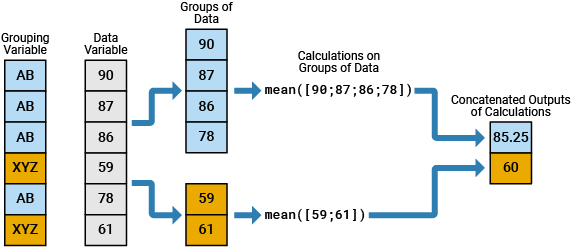
以下の一覧のメソッドのいずれかを使用して、グループ化された計算を table 変数に対して実行できます。
groupsummary、groupcounts、groupfilter、およびgrouptransformvarfunおよびrowfunfindgroupsおよびsplitapplyライブ エディターの [グループ別に計算] タスク
多くの場合、groupsummary が、グループ化された計算で推奨される関数です。これは簡単に使用でき、結果を説明するラベルを含む table を返します。ただし、リストされている他の関数でも状況によっては役立つ機能が提供されています。
このトピックでは、これらの関数のそれぞれを使用する例を示します。最後に、その動作と推奨される使用方法についてまとめています。
ファイルからの table の作成
サンプル スプレッドシート outages.csv には、米国における電力会社の停電を表すデータ値が含まれています。このファイルから table を作成するために、関数 readtable を使用します。ファイルのテキスト データを string 配列である table 変数に読み取るには、名前と値の引数 TextType を "string" として指定します。
outages = readtable("outages.csv",TextType="string")
outages=1468×6 table
Region OutageTime Loss Customers RestorationTime Cause
___________ ________________ ______ __________ ________________ _________________
"SouthWest" 2002-02-01 12:18 458.98 1.8202e+06 2002-02-07 16:50 "winter storm"
"SouthEast" 2003-01-23 00:49 530.14 2.1204e+05 NaT "winter storm"
"SouthEast" 2003-02-07 21:15 289.4 1.4294e+05 2003-02-17 08:14 "winter storm"
"West" 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 "equipment fault"
"MidWest" 2002-03-16 06:18 186.44 2.1275e+05 2002-03-18 23:23 "severe storm"
"West" 2003-06-18 02:49 0 0 2003-06-18 10:54 "attack"
"West" 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 "equipment fault"
"West" 2002-06-06 19:28 311.86 NaN 2002-06-07 00:51 "equipment fault"
"NorthEast" 2003-07-16 16:23 239.93 49434 2003-07-17 01:12 "fire"
"MidWest" 2004-09-27 11:09 286.72 66104 2004-09-27 16:37 "equipment fault"
"SouthEast" 2004-09-05 17:48 73.387 36073 2004-09-05 20:46 "equipment fault"
"West" 2004-05-21 21:45 159.99 NaN 2004-05-22 04:23 "equipment fault"
"SouthEast" 2002-09-01 18:22 95.917 36759 2002-09-01 19:12 "severe storm"
"SouthEast" 2003-09-27 07:32 NaN 3.5517e+05 2003-10-04 07:02 "severe storm"
"West" 2003-11-12 06:12 254.09 9.2429e+05 2003-11-17 02:04 "winter storm"
"NorthEast" 2004-09-18 05:54 0 0 NaT "equipment fault"
⋮
categorical グループ化変数の作成
table 変数には任意のデータ型を含めることができます。ただし、概念的には、table は 2 つの一般的な種類の変数 "データ変数" および "グループ化変数" を含むものとして考えることもできます。
データ変数により、個別のイベントまたは観測について説明できます。たとえば、
outagesでは変数OutageTime、Loss、Customers、およびRestorationTimeをデータ変数として考えることができます。グループ化変数により、共通点があるイベントまたは観測をグループ化できます。たとえば、
outagesでは変数RegionおよびCauseをグループ化変数として考えることができます。同じ地域で発生した停電や原因が同じである停電をグループ化して解析できます。
多くの場合、グループ化変数には、"カテゴリ" を指定する固定値の離散集合が含まれています。カテゴリはデータ値が属することができるグループを指定します。categorical データ型は、カテゴリを処理する際に便利な型です。
Region および Cause を categorical 変数に変換するには、関数 convertvars を使用します。
outages = convertvars(outages,["Region" "Cause"],"categorical")
outages=1468×6 table
Region OutageTime Loss Customers RestorationTime Cause
_________ ________________ ______ __________ ________________ _______________
SouthWest 2002-02-01 12:18 458.98 1.8202e+06 2002-02-07 16:50 winter storm
SouthEast 2003-01-23 00:49 530.14 2.1204e+05 NaT winter storm
SouthEast 2003-02-07 21:15 289.4 1.4294e+05 2003-02-17 08:14 winter storm
West 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 equipment fault
MidWest 2002-03-16 06:18 186.44 2.1275e+05 2002-03-18 23:23 severe storm
West 2003-06-18 02:49 0 0 2003-06-18 10:54 attack
West 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 equipment fault
West 2002-06-06 19:28 311.86 NaN 2002-06-07 00:51 equipment fault
NorthEast 2003-07-16 16:23 239.93 49434 2003-07-17 01:12 fire
MidWest 2004-09-27 11:09 286.72 66104 2004-09-27 16:37 equipment fault
SouthEast 2004-09-05 17:48 73.387 36073 2004-09-05 20:46 equipment fault
West 2004-05-21 21:45 159.99 NaN 2004-05-22 04:23 equipment fault
SouthEast 2002-09-01 18:22 95.917 36759 2002-09-01 19:12 severe storm
SouthEast 2003-09-27 07:32 NaN 3.5517e+05 2003-10-04 07:02 severe storm
West 2003-11-12 06:12 254.09 9.2429e+05 2003-11-17 02:04 winter storm
NorthEast 2004-09-18 05:54 0 0 NaT equipment fault
⋮
table でのグループ別の統計の計算
groupsummary、varfun、splitapply などの関数を使用して、table でグループ別に統計を計算できます。これらの関数では、table 内のデータ グループおよび各グループで計算を実行するメソッドを指定できます。結果は別の table または出力配列に保存できます。
たとえば、outages table で地域ごとに停電による平均電力損失および影響を受けた顧客の平均数を求めます。この計算を実行するには、関数 groupsummary を使用する方法が推奨されます。Region をグループ化変数として指定し、mean を各グループに適用するメソッドとして指定し、Loss および Customers をデータ変数として指定します。出力では、地域 (変数 Region 内)、地域ごとの停電回数 (変数 GroupCount 内)、および各地域の平均電力損失と影響を受けた顧客の平均数 (それぞれ変数 mean_Loss と変数 mean_Customers 内) のリストが示されます。
meanLossByRegion = groupsummary(outages,"Region","mean",["Loss" "Customers"])
meanLossByRegion=5×4 table
Region GroupCount mean_Loss mean_Customers
_________ __________ _________ ______________
MidWest 142 1137.7 2.4015e+05
NorthEast 557 551.65 1.4917e+05
SouthEast 389 495.35 1.6776e+05
SouthWest 26 493.88 2.6975e+05
West 354 433.37 1.5201e+05
関数 groupsummary は以下のようないくつかの理由で推奨されます。
関数ハンドルを使用することなく名前で多くの一般的なメソッド (
max、min、meanなど) を指定できる。1 回の呼び出しで複数のメソッドを指定できる。
結果の計算時にデータ変数内の
NaN、NaT、などの欠損値が自動的に "省略される"。
meanLossByRegion 出力 table で変数 mean_Loss および mean_Customers に NaN が含まれていないのは、3 番目のポイントが理由です。
groupsummary の 1 回の呼び出しで複数のメソッドを指定するには、配列でメソッドをリストします。たとえば、地域別に電力損失の最大値、平均値、および最小値を計算します。
lossStatsByRegion = groupsummary(outages,"Region",["max" "mean" "min"],"Loss")
lossStatsByRegion=5×5 table
Region GroupCount max_Loss mean_Loss min_Loss
_________ __________ ________ _________ ________
MidWest 142 23141 1137.7 0
NorthEast 557 23418 551.65 0
SouthEast 389 8767.3 495.35 0
SouthWest 26 2796 493.88 0
West 354 16659 433.37 0
すべての地域で損失の最小値はゼロになっています。損失がゼロを超えた停電のみを解析するには、outages で損失がゼロである行を除外します。まず、outages.Loss がゼロより大きい行の場合に値が logical 1 (true) になる logical インデックスのベクトルを作成します。次に、outages のインデックス付けを行い、該当する行のみが含まれる table を返します。もう一度、地域別に電力損失の最大値、平均値、および最小値を計算します。
nonZeroLossIndices = outages.Loss > 0; nonZeroLossOutages = outages(nonZeroLossIndices,:); nonZeroLossStats = groupsummary(nonZeroLossOutages,"Region",["max" "mean" "min"],"Loss")
nonZeroLossStats=5×5 table
Region GroupCount max_Loss mean_Loss min_Loss
_________ __________ ________ _________ ________
MidWest 81 23141 1264.1 8.9214
NorthEast 180 23418 827.47 0.74042
SouthEast 234 8767.3 546.16 2.3096
SouthWest 23 2796 515.35 27.882
West 175 16659 549.76 0.71847
グループ化された計算用の代替関数の使用
table でグループ化された計算を実行する代替関数があります。groupsummary が推奨されますが、代替関数も状況によっては役立ちます。
関数
varfunは変数に対して計算を実行します。groupsummaryと似ていますが、varfunはグループ化された計算とグループ化されない計算の両方を実行できます。関数
rowfunは行に沿って計算を実行します。複数の入力を受け取るメソッドまたは複数の出力を返すメソッドを指定できます。関数
findgroupsおよびsplitapplyは、変数に対して、または行に沿って計算を実行できます。複数の入力を受け取るメソッドまたは複数の出力を返すメソッドを指定できます。splitapplyの出力は table ではなく配列です。
変数に対する varfun の呼び出し
たとえば、varfun を使用して地域別に電力損失の最大値を計算します。出力 table の形式は groupsummary の出力と似ています。
maxLossByVarfun = varfun(@max, ... outages, ... InputVariables="Loss", ... GroupingVariables="Region")
maxLossByVarfun=5×3 table
Region GroupCount max_Loss
_________ __________ ________
MidWest 142 23141
NorthEast 557 23418
SouthEast 389 8767.3
SouthWest 26 2796
West 354 16659
ただし、varfun を使用する場合には以下の大きな違いがあります。
常に関数ハンドルを使用してメソッドを指定する必要があります。
指定できるメソッドは 1 つのみです。
グループ化された計算 "または" グループ化されない計算を実行できます。
結果の計算時にデータ変数内の
NaN、NaTなどの欠損値が自動的に "含まれます"。
最後のポイントが、groupsummary と varfun の動作の重要な違いです。たとえば、変数 Loss には NaN が含まれています。varfun を使用して損失の平均値を計算した場合、groupsummary の既定の結果とは異なり、既定では結果が NaN になります。
meanLossByVarfun = varfun(@mean, ... outages, ... InputVariables="Loss", ... GroupingVariables="Region")
meanLossByVarfun=5×3 table
Region GroupCount mean_Loss
_________ __________ _________
MidWest 142 NaN
NorthEast 557 NaN
SouthEast 389 NaN
SouthWest 26 NaN
West 354 NaN
varfun を使用する場合に欠損値を省略するには、無名関数でメソッドをラップして、"omitnan" オプションを指定できるようにします。
omitnanMean = @(x)(mean(x,"omitnan")); meanLossOmitNaNs = varfun(omitnanMean, ... outages, ... InputVariables="Loss", ... GroupingVariables="Region")
meanLossOmitNaNs=5×3 table
Region GroupCount Fun_Loss
_________ __________ ________
MidWest 142 1137.7
NorthEast 557 551.65
SouthEast 389 495.35
SouthWest 26 493.88
West 354 433.37
別のポイントでは、table 変数でグループ化されない計算を実行するという、異なるが関連しているユース ケースが示されています。グループ化せずにメソッドをすべての table 変数に適用するには、varfun を使用します。たとえば、table 全体で電力損失の最大値および影響を受けた顧客の最大数を計算します。
maxValuesInOutages = varfun(@max, ... outages, ... InputVariables=["Loss" "Customers"])
maxValuesInOutages=1×2 table
max_Loss max_Customers
________ _____________
23418 5.9689e+06
行に対する rowfun の呼び出し
関数 rowfun は table の行に沿ってメソッドを適用します。varfun は指定した各変数の 1 つずつにメソッドを適用しますが、rowfun は指定したすべての table 変数をメソッドの入力引数として受け取り、メソッドを一度に適用します。
たとえば、各地域の顧客ごとの損失の中央値を計算します。この計算を実行するには、まず、2 つの入力引数 (loss および customers) を受け取り、損失を顧客数で除算し、中央値を返す関数を指定します。
medianLossCustFcn = @(loss,customers)(median(loss ./ customers,"omitnan"));その後、rowfun を呼び出します。名前と値の引数 OutputVariablesNames を使用して、意味のある出力変数名を指定できます。
meanLossPerCustomer = rowfun(medianLossCustFcn, ... outages, ... InputVariables=["Loss" "Customers"], ... GroupingVariables="Region", ... OutputVariableNames="MedianLossPerCustomer")
meanLossPerCustomer=5×3 table
Region GroupCount MedianLossPerCustomer
_________ __________ _____________________
MidWest 142 0.0042139
NorthEast 557 0.0028512
SouthEast 389 0.0032057
SouthWest 26 0.0026353
West 354 0.002527
メソッドで複数の出力が返される場合にも rowfun を使用できます。たとえば、bounds を使用して rowfun の 1 回の呼び出しで地域ごとの損失の最小値と最大値を計算します。関数 bounds は 2 つの出力引数を返します。
boundsLossPerRegion = rowfun(@bounds, ... outages, ... InputVariables="Loss", ... GroupingVariables="Region", ... OutputVariableNames=["MinLoss" "MaxLoss"])
boundsLossPerRegion=5×4 table
Region GroupCount MinLoss MaxLoss
_________ __________ _______ _______
MidWest 142 0 23141
NorthEast 557 0 23418
SouthEast 389 0 8767.3
SouthWest 26 0 2796
West 354 0 16659
変数または行に対する findgroups および splitapply の呼び出し
関数 findgroups を使用してグループを定義してから、splitapply を使用してメソッドを各グループに適用できます。関数 findgroups は、データの行が属しているグループを識別するグループ番号のベクトルを返します。関数 splitapply は、グループに適用されたメソッドの出力の数値配列を返します。
たとえば、findgroups および splitapply を使用して、地域別の電力損失の最大値を計算します。
G = findgroups(outages.Region)
G = 1468×1
4
3
3
5
1
5
5
5
2
1
3
5
3
3
5
⋮
maxLossArray = splitapply(@max,outages.Loss,G)
maxLossArray = 5×1
104 ×
2.3141
2.3418
0.8767
0.2796
1.6659
rowfun と同様に、splitapply では複数の出力を返すメソッドを指定できます。bounds を使用して最小値と最大値の両方を計算します。
[minLossArray,maxLossArray] = splitapply(@bounds,outages.Loss,G)
minLossArray = 5×1
0
0
0
0
0
maxLossArray = 5×1
104 ×
2.3141
2.3418
0.8767
0.2796
1.6659
複数の入力を受け取るメソッドを指定することもできます。たとえば、関数 medianLossCustFcn を再度使用して、顧客ごとの損失の中央値を計算します。ただし、今回は各地域の顧客ごとの損失の中央値を配列として返します。
medianLossCustFcn = @(loss,customers)(median(loss ./ customers,"omitnan"));
medianLossArray = splitapply(medianLossCustFcn,outages.Loss,outages.Customers,G)medianLossArray = 5×1
0.0042
0.0029
0.0032
0.0026
0.0025
groupsummary の出力とは異なり、findgroups および splitapply の数値出力には注釈が付けられません。ただし、数値出力を返すと、次のような他の利点が得られます。
splitapplyの複数回の呼び出しでfindgroupsの出力を使用できる。大規模な table でグループ化された計算を多数実行する場合に、効率化のためにfindgroupsおよびsplitapplyを使用できます。findgroupsおよびsplitapplyの出力に基づいて作成することで、形式が異なる結果 table を作成できる。複数の出力を返すメソッドを呼び出すことができる。
splitapplyの出力を既存の table に追加できる。
既存の table への新しい計算の追加
既に結果の table がある場合、別の計算の結果をその table に追加できます。たとえば、各地域の平均停電期間 (時間単位) を計算します。平均期間を新しい変数として lossStatsByRegion table に追加します。
まず、停電時刻を復旧時刻から減算して停電期間を返します。関数 hours を使用して、これらの期間を時間数に変換します。
D = outages.RestorationTime - outages.OutageTime; H = hours(D)
H = 1468×1
105 ×
0.0015
NaN
0.0023
0.0000
0.0007
0.0001
0.0000
0.0001
0.0001
0.0001
0.0000
0.0001
0.0000
0.0017
0.0012
⋮
次に、mean を使用して平均期間を計算します。停電時刻および復旧時刻には欠損値が含まれているため、停電期間には NaN 値が含まれています。前述のように、無名関数でメソッドをラップして、"omitnan" オプションを指定します。
omitnanMean = @(x)(mean(x,"omitnan"));地域別の平均停電期間を計算します。これを新しい table 変数として lossStatsByRegion に追加します。
G = findgroups(outages.Region); lossStatsByRegion.mean_Outage = splitapply(omitnanMean,H,G)
lossStatsByRegion=5×6 table
Region GroupCount max_Loss mean_Loss min_Loss mean_Outage
_________ __________ ________ _________ ________ ___________
MidWest 142 23141 1137.7 0 819.25
NorthEast 557 23418 551.65 0 581.04
SouthEast 389 8767.3 495.35 0 40.83
SouthWest 26 2796 493.88 0 59.519
West 354 16659 433.37 0 673.45
ビンとしてのグループの指定
グループを指定する別の方法があります。グループ化変数で一意の値としてカテゴリを指定する代わりに、値が連続的に分布する変数に値をビン化できます。次に、そうしたビンを使用してグループを指定できます。
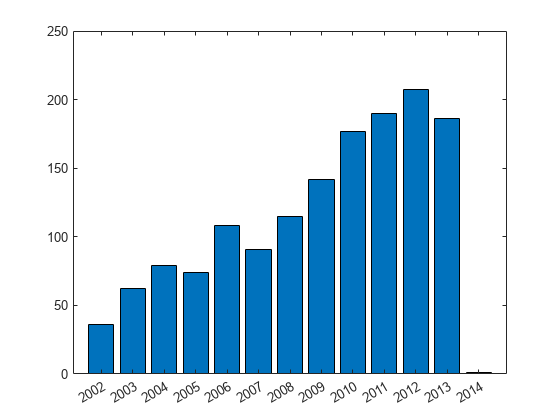
たとえば、年で停電をビン化します。年ごとに停電の回数をカウントするには、関数 groupcounts を使用します。
outagesByYear = groupcounts(outages,"OutageTime","year")
outagesByYear=13×3 table
year_OutageTime GroupCount Percent
_______________ __________ _______
2002 36 2.4523
2003 62 4.2234
2004 79 5.3815
2005 74 5.0409
2006 108 7.3569
2007 91 6.1989
2008 115 7.8338
2009 142 9.673
2010 177 12.057
2011 190 12.943
2012 207 14.101
2013 186 12.67
2014 1 0.06812
年ごとの停電回数を可視化します。このデータ セットでは、年ごとの回数は時間とともに増加しています。
bar(outagesByYear.year_OutageTime,outagesByYear.GroupCount)
ビンをグループとして groupsummary を使用できます。たとえば、年ごとに影響を受けた顧客数および電力損失の中央値を計算します。
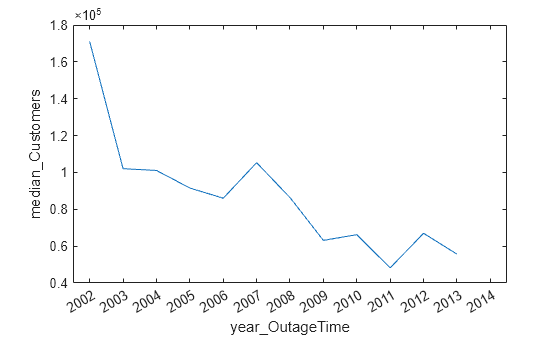
medianLossesByYear = groupsummary(outages,"OutageTime","year","median",["Customers" "Loss"])
medianLossesByYear=13×4 table
year_OutageTime GroupCount median_Customers median_Loss
_______________ __________ ________________ ___________
2002 36 1.7101e+05 277.02
2003 62 1.0204e+05 295.6
2004 79 1.0108e+05 252.44
2005 74 91536 265.16
2006 108 86020 210.08
2007 91 1.0529e+05 232.12
2008 115 86356 205.77
2009 142 63119 83.491
2010 177 66212 155.76
2011 190 48200 75.286
2012 207 66994 78.289
2013 186 55669 69.596
2014 1 NaN NaN
年ごとの停電の影響を受けた顧客数の中央値を可視化します。停電回数は時間とともに増加していましたが、影響を受けた顧客数の中央値は減少していました。
plot(medianLossesByYear,"year_OutageTime","median_Customers")
停電が 75 回より多かった年の outages の行を返します。該当する年で outages にインデックスを付けるには、関数 groupfilter を使用します。行数が 75 より多いビンを検出するために、ビン内の行の数が 75 より多い場合に logical 1 を返す無名関数を指定します。
outages75 = groupfilter(outages,"OutageTime","year",@(x) numel(x) > 75)
outages75=1295×7 table
Region OutageTime Loss Customers RestorationTime Cause year_OutageTime
_________ ________________ ______ __________ ________________ _______________ _______________
West 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 equipment fault 2004
West 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 equipment fault 2004
MidWest 2004-09-27 11:09 286.72 66104 2004-09-27 16:37 equipment fault 2004
SouthEast 2004-09-05 17:48 73.387 36073 2004-09-05 20:46 equipment fault 2004
West 2004-05-21 21:45 159.99 NaN 2004-05-22 04:23 equipment fault 2004
NorthEast 2004-09-18 05:54 0 0 NaT equipment fault 2004
NorthEast 2004-11-13 10:42 NaN 1.4227e+05 2004-11-19 02:31 winter storm 2004
SouthEast 2004-12-06 23:18 NaN 37136 2004-12-14 03:21 winter storm 2004
West 2004-12-21 18:50 112.05 7.985e+05 2004-12-29 03:46 winter storm 2004
NorthEast 2004-12-26 22:18 255.45 1.0444e+05 2004-12-27 14:11 winter storm 2004
SouthWest 2004-06-06 05:27 559.41 2.19e+05 2004-06-06 05:55 equipment fault 2004
MidWest 2004-07-02 09:16 15128 2.0104e+05 2004-07-06 14:11 thunder storm 2004
SouthWest 2004-07-18 14:40 340.35 1.4963e+05 2004-07-26 23:34 severe storm 2004
NorthEast 2004-09-16 19:42 4718 NaN NaT unknown 2004
SouthEast 2004-09-20 12:37 8767.3 2.2249e+06 2004-10-02 06:00 severe storm 2004
MidWest 2004-11-09 18:44 470.83 67587 2004-11-09 21:24 wind 2004
⋮
動作と推奨事項の概要
以下のヒントおよび推奨事項を使用して、グループ計算の実行に使用する関数を判断してください。
グループを指定するには、グループ化変数を使用するか、あるいは数値、
datetime、またはduration変数から作成されたビンを使用してください。table または timetable 内のデータに対してグループ別に計算を実行するには、推奨される関数
groupsummaryを使用してください。関連する関数groupcounts、groupfilter、およびgrouptransformも役立ちます。メソッドをデータ グループに適用する際に欠損値 (
NaNやNaTなど) を自動的に含める場合には、varfunの使用を検討してください。また、varfunはグループ化された計算とグループ化されない計算の両方を実行できます。大規模な table でグループ化された計算を連続して何度も実行する場合には、効率化のために
findgroupsおよびsplitapplyの使用を検討してください。既存の結果の table に新しい配列を追加する場合は、
findgroupsおよびsplitapplyの使用を検討してください。boundsなど、複数の出力を返すメソッドを使用して計算を実行する場合は、rowfunまたはsplitapplyのいずれかを使用してください。複数の入力引数を必要とするメソッドを使用して行に沿って計算を実行する場合は、
rowfunまたはsplitapplyのいずれかを使用してください。
参考
groupsummary | groupcounts | groupfilter | grouptransform | varfun | rowfun | findgroups | splitapply | table | categorical | datetime | duration | readtable | convertvars | bounds