このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
groupfilter
グループによるフィルター処理
構文
説明
テーブル データ
G = groupfilter(T,groupvars,method)method で指定されたグループ単位のフィルター処理条件を満たす table または timetable T の行を返します。フィルター処理条件 method は、それぞれの非グループ化変数に適用される関数ハンドルです。グループは、同じ一意の値の組み合わせをもつ groupvars の変数の行により定義されます。たとえば、G = groupfilter(T,"Trial",@(x) numel(x) > 5) は、T のデータを Trial 別にグループ化し、試行数が 5 を超えるグループに属する行を保持します。
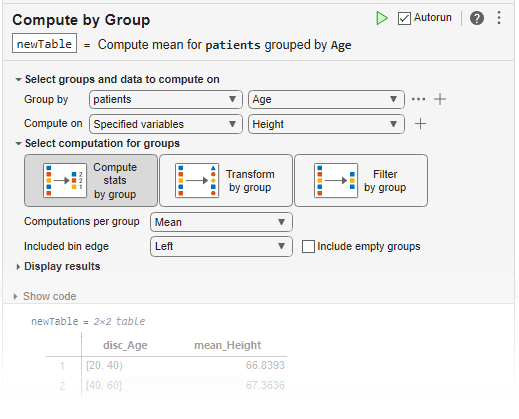
groupfilter の機能を対話的に使用するには、ライブ スクリプトに [グループ別に計算] タスクを追加します。
配列データ
B = groupfilter(A,groupvars,method)method で指定されたグループ単位のフィルター処理条件を満たすベクトルまたは行列 A の行を返します。フィルター処理条件 method は、すべての列ベクトルに適用される関数ハンドルです。グループは、同じ一意の値の組み合わせをもつ groupvars の列ベクトルの行により定義されます。
groupfilter の機能を対話的に使用するには、ライブ スクリプトに [グループ別に計算] タスクを追加します。
例
入力引数
出力引数
代替機能
拡張機能
バージョン履歴
R2019b で導入参考
関数
groupsummary|groupcounts|grouptransform|findgroups|splitapply|discretize|varfun|rowfun