数値的等価性テスト
GPU による高速化シミュレーションとプロセッサインザループ (PIL) シミュレーションを使用して、モデル コンポーネントと、これらのコンポーネントから生成する量産コードの数値的等価性をテストします。
GPU による高速化シミュレーションでは、開発用コンピューターでソース コードをテストします。PIL シミュレーションでは、実際のターゲット ハードウェアのオブジェクト コードを実行して、ターゲット ハードウェアに展開する予定のコンパイル済みオブジェクト コードをテストします。モデル コンポーネントと生成コードが数値的に等価かどうかを調べるには、GPU による高速化の結果と PIL の結果を、ノーマル モードの結果と比較します。
PIL のターゲット接続性設定
PIL シミュレーションを実行する前に、ターゲット接続性を構成する必要があります。ターゲット接続性設定により、PIL シミュレーションで以下の操作が可能になります。
ターゲット アプリケーションのビルド。
ターゲットでのアプリケーションのダウンロード、開始、および停止。
Simulink® とターゲットの間の通信のサポート。
NVIDIA DRIVE® および Jetson™ などのハードウェア プラットフォームのターゲット接続性の構成を生成するには、MATLAB® Coder™ Support Package for NVIDIA® Jetson and NVIDIA DRIVE Platforms をインストールします。
ターゲット ボード要件
NVIDIA DRIVE または Jetson 組み込みプラットフォーム。
ターゲット ボードとホスト PC を接続するイーサネット クロスオーバー ケーブル (ターゲット ボードをローカル ネットワークに接続できない場合)。
ボードにインストールされている NVIDIA CUDA® Toolkit。
コンパイラおよびライブラリ用のターゲット上の環境変数。サポートされているコンパイラおよびライブラリのバージョンおよびその設定の詳細については、Prerequisites for Generating Code for NVIDIA Boardsを参照してください。
ライブ ハードウェア接続オブジェクトの作成
サポート パッケージ ソフトウェアは、生成された CUDA コードを DRIVE プラットフォームまたは Jetson プラットフォームでビルドして実行している間、TCP/IP 経由の SSH 接続を使用してコマンドを実行します。ターゲット プラットフォームをホスト コンピューターと同じネットワークに接続するか、イーサネット クロス ケーブルを使用してボードをホスト コンピューターに直接接続します。ボードを設定して構成する方法については、NVIDIA のドキュメントを参照してください。
NVIDIA ハードウェアと通信するには、関数 jetson または関数 drive を使用してライブ ハードウェア接続オブジェクトを作成します。関数を使用してライブ ハードウェア接続オブジェクトを作成するには、ターゲット ボードのホスト名または IP アドレス、ユーザー名、およびパスワードを提供します。たとえば、次のようにして Jetson ハードウェアのライブ オブジェクトを作成します。
hwobj = jetson('192.168.1.15','ubuntu','ubuntu');
ハードウェア、コンパイラ ツール、ライブラリ、IO サーバーのインストールをチェックし、ターゲットの周辺装置情報を収集します。この情報はコマンド ウィンドウに表示されます。
Checking for CUDA availability on the Target... Checking for NVCC in the target system path... Checking for CUDNN library availability on the Target... Checking for TensorRT library availability on the Target... Checking for Prerequisite libraries is now complete. Fetching hardware details... Fetching hardware details is now complete. Displaying details. Board name : NVIDIA Jetson TX2 CUDA Version : 9.0 cuDNN Version : 7.0 TensorRT Version : 3.0 Available Webcams : UVC Camera (046d:0809) Available GPUs : NVIDIA Tegra X2
または、次のようにして DRIVE ハードウェアのライブ オブジェクトを作成します。
hwobj = drive('92.168.1.16','nvidia','nvidia');
メモ
接続に失敗した場合、MATLAB コマンド ウィンドウで診断エラー メッセージが報告されます。接続が失敗した場合に最も可能性が高い原因は、IP アドレスまたはホスト名が誤っていることです。
例:マンデルブロ集合
説明
マンデルブロ集合とは、下記の方程式で定義された軌跡が k→∞ のときに有限の範囲内にとどまる値 z0 で構成された複素平面の領域です。
マンデルブロ集合の全体的な幾何形状を図に示しています。この図には、集合の境界の外側周辺における詳しい構造を十分に示すための解像度がありません。拡大率を上げていくと、マンデルブロ集合の詳細な境界が示され、そこでは徐々に細かくなりながら細部が繰り返されていることがわかります。
アルゴリズム
このチュートリアルでは、メインのカージオイドとその左側にある p/q 球状部との谷間にある、マンデルブロ集合の大きく拡大された部分を指定する一連の範囲を選択します。これらの 2 つの範囲間に、実数部 (x) と虚数部 (y) の 1000 x 1000 のグリッドを作成します。次に、マンデルブロ アルゴリズムを各グリッド位置で反復します。500 回の反復回数で、完全な解像度のイメージがレンダリングされます。
maxIterations = 500; gridSize = 1000; xlim = [-0.748766713922161,-0.748766707771757]; ylim = [0.123640844894862,0.123640851045266];
このチュートリアルでは、CPU で実行される標準の MATLAB コマンドを使ったマンデルブロ集合の実装を使用します。この計算はすべての場所が同時に更新されるようにベクトル化されています。
最上位モデルでの GPU による高速化または PIL シミュレーション
最上位モデル PIL シミュレーションを実行して、生成されたモデル コードをテストします。この方法には以下が含まれます。
スタンドアロン コード インターフェイスを使用する最上位モデルから生成されたコードをテスト。
MATLAB ワークスペースからテスト ベクトルまたはスティミュラス入力を読み込むようにモデルを構成。
ノーマル モード、GPU による高速化モード、および PIL シミュレーション モードの間で最上位モデルを容易に切り替え可能。
マンデルブロ最上位モデルの作成
Simulink モデルを作成し、User-Defined Functions ライブラリから MATLAB Function ブロックを挿入します。
MATLAB Function ブロックをダブルクリックします。既定の関数シグネチャが MATLAB Function ブロック エディターに表示されます。
マンデルブロ アルゴリズムを実装する関数
mandelbrot_countを定義します。関数ヘッダーは、maxIterations、xGrid、およびyGridを関数mandelbrot_countの引数として宣言し、またcountを戻り値として宣言します。function count = mandelbrot_count(maxIterations, xGrid, yGrid) % mandelbrot computation z0 = complex(xGrid,yGrid); count = ones(size(z0)); % Map computation to GPU coder.gpu.kernelfun; z = z0; for n = 0:maxIterations z = z.*z + z0; inside = abs(z)<=2; count = count + inside; end count = log(count);
MATLAB Function ブロックのブロック パラメーターを開きます。[コード生成] タブで、[関数のパッケージ化] パラメーターについて
[再利用可能な関数]を選択します。[関数のパッケージ化] パラメーターが他の値に設定されている場合、CUDA カーネルが生成されない可能性があります。
Sources および Sinks ライブラリから Inport (Simulink) ブロックと Outport (Simulink) ブロックを追加します。
これらのブロックを、次の図に示すように接続します。モデルを
mandelbrot_top.slxとして保存します。
GPU による高速化のためのモデルの構成
数値的等価性テストに取り組むため、次の機能をオフにします。
モデル カバレッジ
コード カバレッジ
実行時間プロファイリング
model = 'mandelbrot_top'; close_system(model,0); open_system(model) set_param(gcs, 'RecordCoverage','off'); coverageSettings = get_param(model, 'CodeCoverageSettings'); coverageSettings.CoverageTool='None'; set_param(model, 'CodeCoverageSettings',coverageSettings); set_param(model, 'CodeExecutionProfiling','off');
入力スティミュラス データを構成します。次のコード行は、xlim と ylim で指定した範囲の間に実数部 (x) と虚数部 (y) の 1000 x 1000 のグリッドを生成します。
gridSize = 1000; xlim = [-0.748766713922161, -0.748766707771757]; ylim = [ 0.123640844894862, 0.123640851045266]; x = linspace( xlim(1), xlim(2), gridSize ); y = linspace( ylim(1), ylim(2), gridSize ); [xG, yG] = meshgrid( x, y ); maxIterations = timeseries(500,0); xGrid = timeseries(xG,0); yGrid = timeseries(yG,0);
モデルのログ オプションを構成します。
set_param(model, 'LoadExternalInput','on'); set_param(model, 'ExternalInput','maxIterations, xGrid, yGrid'); set_param(model, 'SignalLogging', 'on'); set_param(model, 'SignalLoggingName', 'logsOut'); set_param(model, 'SaveOutput','on')
ノーマル シミュレーションと PIL シミュレーションの実行
ノーマル モード シミュレーションを実行します。
set_param(model,'SimulationMode','normal') set_param(model,'GPUAcceleration','on'); sim_output = sim(model,10); count_normal = sim_output.yout{1}.Values.Data(:,:,1);
最上位モデルの PIL シミュレーションを実行する前に、ハードウェア ボード上で実行するようにモデルを構成します。次のコードは、NVIDIA Jetson ボード上で PIL を実行するようにモデルを構成します。
set_param(model,"HardwareBoard","NVIDIA Jetson"); set_param(model,"SimulationMode","Processor-in-the-Loop (PIL)") sim_output = sim(model,10); count_pil = sim_output.yout{1}.Values.Data(:,:,1);
### Unable to find Simulink cache file "mandelbrot_top.slxc". ### Searching for referenced models in model 'mandelbrot_top'. ### Total of 1 models to build. ### Starting build procedure for: mandelbrot_top ### Generating code and artifacts to 'Model specific' folder structure ### Generating code into build folder: C:\Users\user\folder\mandelbrot_top_ert_rtw ### Invoking Target Language Compiler on mandelbrot_top.rtw ### Using System Target File: ert.tlc ### Loading TLC function libraries ....... ### Initial pass through model to cache user defined code . ### Caching model source code ............................................... ### Writing header file mandelbrot_top_types.h ### Writing source file mandelbrot_top.c ### Writing header file mandelbrot_top_private.h ### Writing header file mandelbrot_top.h ### Writing header file rtwtypes.h . ### Writing header file rtGetNaN.h ### Writing source file rtGetNaN.c ### Writing header file rt_nonfinite.h ### Writing source file rt_nonfinite.c . ### Writing header file rtGetInf.h ### Writing source file rtGetInf.c ### Writing header file rtmodel.h ### Writing source file ert_main.c ### TLC code generation complete (took 4.882s). ### Saving binary information cache. ### Using toolchain: GNU GCC for NVIDIA Embedded Processors ### Creating 'C:\Users\user\folder\mandelbrot_top_ert_rtw\mandelbrot_top.mk' ... ### Building 'mandelbrot_top': make -f mandelbrot_top.mk -j4 buildobj ### Successful completion of build procedure for: mandelbrot_top ### Simulink cache artifacts for 'mandelbrot_top' were created in 'C:\Users\user\folder\mandelbrot_top.slxc'. Build Summary Top model targets: Model Build Reason Status Build Duration ================================================================================================================= mandelbrot_top Information cache folder or artifacts were missing. Code generated and compiled. 0h 0m 13.966s 1 of 1 models built (0 models already up to date) Build duration: 0h 0m 14.111s ### Connectivity configuration for component "mandelbrot_top": NVIDIA Jetson ### PIL execution is using Port 17725. PIL execution is using 30 Sec(s) for receive time-out. ### Preparing to start PIL simulation ... Building with 'Microsoft Visual C++ 2022 (C)'. MEX completed successfully. ### Using toolchain: GNU GCC for NVIDIA Embedded Processors ### Creating 'C:\Users\user\folder\mandelbrot_top_ert_rtw\coderassumptions\lib\mandelbrot_top_ca.mk' ... ### Building 'mandelbrot_top_ca': make -f mandelbrot_top_ca.mk -j4 all ### Using toolchain: GNU GCC for NVIDIA Embedded Processors ### Creating 'C:\Users\user\folder\mandelbrot_top_ert_rtw\pil\mandelbrot_top.mk' ... ### Building 'mandelbrot_top': make -f mandelbrot_top.mk -j4 all ### Starting application: 'mandelbrot_top_ert_rtw\pil\mandelbrot_top.elf' ### Launching application mandelbrot_top.elf...
このモデルの最新コードが存在しない場合は、Simulink は PIL シミュレーション用のコードを生成します。生成されたコードは、コンピューター上で個別のプロセスとして実行されます。
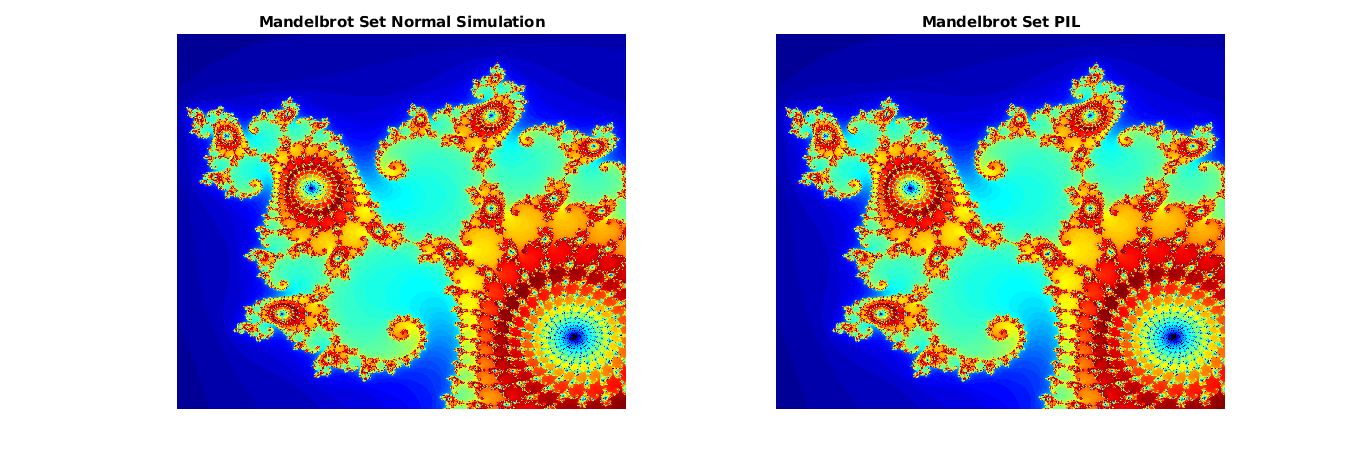
ノーマル シミュレーションと PIL シミュレーションの結果をプロットし、比較します。結果が一致することを確認します。
figure(); subplot(1,2,1) imagesc(x, y, count_normal); colormap([jet();flipud( jet() );0 0 0]); title('Mandelbrot Set Normal Simulation'); axis off; subplot(1,2,2) imagesc(x, y, count_pil); colormap([jet();flipud( jet() );0 0 0]); title('Mandelbrot Set PIL'); axis off;
クリーンアップします。
close_system(model,0); if ishandle(fig1), close(fig1), end clear fig1 simResults = {'count_sil','count_normal','model'}; save([model '_results'],simResults{:}); clear(simResults{:},'simResults')
制限
MAT ファイルのログ記録は、GPU Coder™ を使用したプロセッサインザループ (PIL) シミュレーションではサポートされていません。
参考
関数
open_system(Simulink) |load_system(Simulink) |save_system(Simulink) |close_system(Simulink) |bdclose(Simulink) |get_param(Simulink) |set_param(Simulink) |sim(Simulink) |slbuild(Simulink)