isanomaly
構文
説明
tf = isanomaly(forest,Tbl)IsolationForest オブジェクト forest を使用して table Tbl 内の異常を検出し、Tbl の対応する行で異常が検出された場合に要素が true になる logical 配列 tf を返します。関数 iforest に table を渡して forest を作成した場合、この構文を使用する必要があります。
tf = isanomaly(___,Name=Value)ScoreThreshold=0.5
例
関数 iforest を使用して、汚染されていない学習観測値用の IsolationForest オブジェクトを作成します。次に、オブジェクトおよび新規データをオブジェクト関数 isanomaly に渡して、新規性 (新規データ中の異常) を検出します。
census1994.mat に保存されている 1994 年の国勢調査データを読み込みます。このデータ セットは、個人の年収が $50,000 を超えるかどうかを予測するための、米国勢調査局の人口統計データから構成されます。
load census1994census1994 には学習データ セット adultdata およびテスト データ セット adulttest が含まれています。
adultdata 用に孤立森モデルに学習させます。adultdata には外れ値が含まれていないと仮定します。
rng("default") % For reproducibility [Mdl,tf,s] = iforest(adultdata);
Mdl は IsolationForest オブジェクトです。iforest は、学習データ adultdata の異常インジケーター tf および異常スコア s も返します。名前と値の引数 ContaminationFraction を 0 を超える値として指定していない場合、iforest はすべての学習観測値を正常な観測値として扱います。つまり tf の値はすべて logical 0 (false) となります。この関数によりスコアのしきい値が最大のスコア値に設定されます。しきい値を表示します。
Mdl.ScoreThreshold
ans = 0.8600
学習済み孤立森モデルを使用して、adulttest 内の異常を見つけます。
[tf_test,s_test] = isanomaly(Mdl,adulttest);
関数 isanomaly は、adulttest の異常インジケーター tf_test およびスコア s_test を返します。既定では、isanomaly はしきい値 (Mdl.ScoreThreshold) を超えるスコアをもつ観測値を異常として識別します。
異常スコア s および s_test のヒストグラムを作成します。異常スコアのしきい値に垂直線を作成します。
histogram(s,Normalization="probability") hold on histogram(s_test,Normalization="probability") xline(Mdl.ScoreThreshold,"r-",join(["Threshold" Mdl.ScoreThreshold])) legend("Training Data","Test Data",Location="northwest") hold off

テスト データ中にある異常の観測値のインデックスを表示します。
find(tf_test)
ans = 15655
テスト データの異常スコア分布は学習データの異常スコア分布と類似しているため、isanomaly は既定のしきい値でテスト データ中にある少数の異常を検出します。名前と値のペア ScoreThreshold を使用して、異なるしきい値を指定できます。例については、異常スコアのしきい値の指定を参照してください。
isanomaly の名前と値の引数 ScoreThreshold を使用して、異常スコアのしきい値を指定します。
census1994.mat に保存されている 1994 年の国勢調査データを読み込みます。このデータ セットは、個人の年収が $50,000 を超えるかどうかを予測するための、米国勢調査局の人口統計データから構成されます。
load census1994census1994 には学習データ セット adultdata およびテスト データ セット adulttest が含まれています。
adultdata 用に孤立森モデルに学習させます。
rng("default") % For reproducibility [Mdl,tf,scores] = iforest(adultdata);
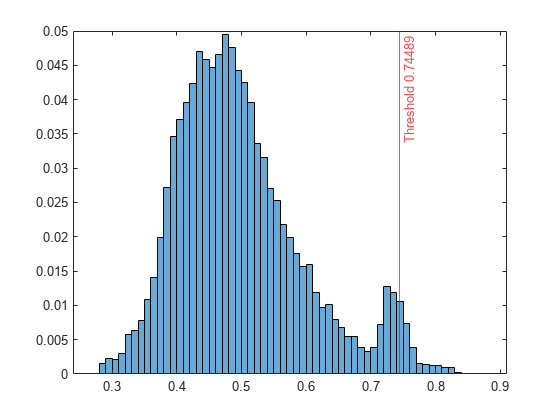
スコア値のヒストグラムをプロットします。既定のスコアのしきい値の位置に垂直線を作成します。
histogram(scores,Normalization="probability"); xline(Mdl.ScoreThreshold,"r-",join(["Threshold" Mdl.ScoreThreshold]))

学習済み孤立森モデルを使用して、テスト データ内の異常を見つけます。孤立森モデルの学習時に取得された既定のしきい値とは異なるしきい値を使用します。
まず、関数isoutlierを使用してスコアのしきい値を調べます。
[~,~,U] = isoutlier(scores)
U = 0.7449
名前と値の引数 ScoreThreshold の値を U として指定します。
[tf_test,scores_test] = isanomaly(Mdl,adulttest,ScoreThreshold=U); histogram(scores_test,Normalization="probability") xline(U,"r-",join(["Threshold" U]))
入力引数
名前と値の引数
出力引数
詳細
アルゴリズム
isanomaly は、Tbl に含まれている NaN、'' (空の文字ベクトル)、"" (空の string)、<missing>、<undefined> の値と X に含まれている NaN 値を欠損値と見なします。
isanomaly は、欠損値を含む観測値を使用して、それらの観測値が有効な値をもつ変数の分岐を特定します。それらの観測値は、葉ノードではなく枝ノードに配置されることがあります。その場合、isanomaly は、ルート ノードから枝ノードまでの距離を使用して異常スコアを計算します。すべての値が欠損値である観測値はルート ノードに配置されるため、スコア値は 1 になります。
参照
[1] Liu, F. T., K. M. Ting, and Z. Zhou. "Isolation Forest," 2008 Eighth IEEE International Conference on Data Mining. Pisa, Italy, 2008, pp. 413-422.
拡張機能
バージョン履歴
R2021b で導入