isoutlier
データの外れ値を検出
構文
説明
TF = isoutlier(A)A の対応する要素で外れ値を検出したときに、その要素が true となる logical 配列を返します。
Aが行列の場合、isoutlierはAの各列を個別に処理します。Aが多次元配列の場合、isoutlierは、サイズが 1 に等しくないAの最初の次元に沿って演算します。Aが table または timetable の場合、isoutlierはAの各変数で別々に動作します。
既定での外れ値とは、中央値からの距離が中央絶対偏差 (MAD) の 3 倍を超えている値です。
isoutlier の機能を対話的に使用するには、ライブ スクリプトに [外れ値データの削除] タスクを追加します。
TF = isoutlier(___,Name=Value)isoutlier(A,SamplePoints=t) は時間ベクトル t の対応する要素を基準として、配列 A の外れ値を検出します。
例
データのベクトルの外れ値を検出します。出力の logical 1 は外れ値の位置を表します。
A = [57 59 60 100 59 58 57 58 300 61 62 60 62 58 57]; TF = isoutlier(A)
TF = 1×15 logical array
0 0 0 1 0 0 0 0 1 0 0 0 0 0 0
平均値から標準偏差の 3 倍を超えて離れている点を外れ値として定義し、ベクトルの外れ値の位置を検出します。
A = [57 59 60 100 59 58 57 58 300 61 62 60 62 58 57];
TF = isoutlier(A,"mean")TF = 1×15 logical array
0 0 0 0 0 0 0 0 1 0 0 0 0 0 0
移動検出メソッドを使用して、時間ベクトルに対応する正弦波内の局所外れ値を検出します。
局所外れ値を含むデータのベクトルを作成します。
x = -2*pi:0.1:2*pi; A = sin(x); A(47) = 0;
A のデータに対応する時間ベクトルを作成します。
t = datetime(2017,1,1,0,0,0) + hours(0:length(x)-1);
外れ値を、スライディング ウィンドウ内の局所中央値から、スケーリングされた局所 MAD の 3 倍を超えた位置にある点として定義します。ウィンドウ サイズを 5 時間に設定し、t の点を基準として A の外れ値の位置を検出します。データと検出した外れ値をプロットします。
TF = isoutlier(A,"movmedian",hours(5),SamplePoints=t); plot(t,A) hold on plot(t(TF),A(TF),"x") legend("Original Data","Outlier Data")

行列の各行の外れ値を検出します。
対角上に外れ値を含むデータの行列を作成します。
A = magic(5) + diag(200*ones(1,5))
A = 5×5
217 24 1 8 15
23 205 7 14 16
4 6 213 20 22
10 12 19 221 3
11 18 25 2 209
各行のデータに基づいて外れ値の位置を検出します。
TF = isoutlier(A,2)
TF = 5×5 logical array
1 0 0 0 0
0 1 0 0 0
0 0 1 0 0
0 0 0 1 0
0 0 0 0 1
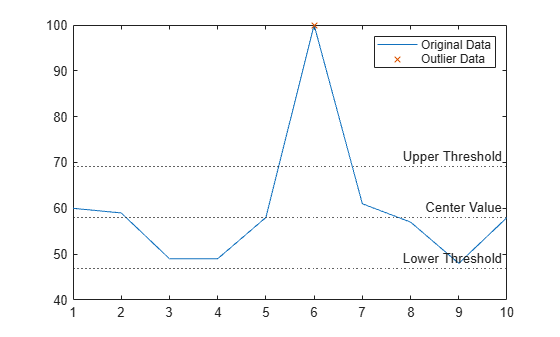
データのベクトルの外れ値を特定し、外れ値を可視化します。
局所外れ値を含むデータのベクトルを作成します。
x = 1:10; A = [60 59 49 49 58 100 61 57 48 58];
既定の検出メソッド "median" を使用して、外れ値を特定します。
[TF,L,U,C] = isoutlier(A);
元のデータ、外れ値、および検出メソッドで決定されたしきい値と中心値をプロットします。中心値はデータの中央値で、上限および下限しきい値は中央値から上下に MAD の 3 倍離れた値です。
plot(x,A) hold on plot(x(TF),A(TF),"x") yline([L U C],":",["Lower Threshold","Upper Threshold","Center Value"]) legend("Original Data","Outlier Data")
入力引数
入力データ。ベクトル、行列、多次元配列、または数値変数をもつ table か timetable として指定します。
Aが table の場合、その変数の型はdoubleまたはsingleでなければなりません。または、DataVariables引数を使用してdoubleまたはsingleの変数を明示的にリストすることもできます。doubleとsingle以外のデータ型の変数を含む table を操作する場合、変数を指定すると便利です。Aが timetable の場合、isoutlierは table 要素のみを処理します。行時間がサンプル点として使用されている場合、行時間は一意で、かつ昇順にリストされていなければなりません。
データ型: double | single | table | timetable
外れ値を検出するメソッド。次の値のいずれかとして指定します。
| メソッド | 説明 |
|---|---|
"median" | 外れ値は、スケーリングされた MAD の 3 倍を超えて中央値から離れている要素と定義されます。スケーリングされた MAD は c*median(abs(A-median(A))) と定義されます。ここで、c=-1/(sqrt(2)*erfcinv(3/2)) です。 |
"mean" | 外れ値は、標準偏差の 3 倍を超えて平均値から離れている要素と定義されます。このメソッドは "median" より高速ですが、ロバスト性は低下します。 |
"quartiles" | 外れ値は、上位四分位数 (75%) から上に、または下位四分位数 (25%) から下に、四分位範囲の 1.5 倍を超える要素と定義されます。このメソッドは、A のデータが正規分布でない場合に便利です。 |
"grubbs" | 外れ値に対するグラブス検定を使用して、外れ値を検出します。これにより、仮説検定に基づいて反復ごとに 1 つの外れ値が除去されます。このメソッドは A のデータが正規分布であることを前提としています。 |
"gesd" | 外れ値に対して一般化 ESD 検定を使用して、外れ値を検出します。この反復メソッドは "grubbs" に似ていますが、複数の外れ値が相互にマスキングしている場合により効果的に機能します。MaxNumOutliers で指定される外れ値の最大数は A の要素数に依存します。 |
入力データ内の NaN 値は、ここで説明されているメソッド名を使用すると自動的に省略されます。
指定した範囲を使用して外れ値を検出するには、isbetween 関数を使用します。
百分位数のしきい値。区間 [0, 100] 内の要素をもつ 2 要素の行ベクトルとして指定します。最初の要素は百分位数の下限しきい値を示し、2 番目の要素は百分位数の上限しきい値を示します。threshold の最初の要素は、2 番目の要素より小さくなければなりません。
たとえば、しきい値が [10 90] の場合、外れ値は 10 番目の百分位数を下回る点、および 90 番目の百分位数を超える点として定義されます。
外れ値を検出する移動メソッド。次の値のいずれかとして指定します。
| メソッド | 説明 |
|---|---|
"movmedian" | 外れ値は、window で指定されたウィンドウの長さでの局所中央値から、スケーリングされた局所 MAD の 3 倍を超えて離れている要素と定義されます。このメソッドは "Hampel フィルター" とも呼ばれます。 |
"movmean" | 外れ値は、window で指定されたウィンドウの長さでの局所平均値から、局所標準偏差の 3 倍を超えて離れている要素と定義されます。 |
移動メソッドのウィンドウの長さ。正の整数スカラー、正の整数の 2 要素ベクトル、正の duration スカラー、または正の duration の 2 要素ベクトルとして指定します。
window が正の整数スカラーである場合、ウィンドウは現在の要素を中心にして配置され、window-1 個の隣接する要素を含みます。window が偶数である場合、ウィンドウは現在の要素および直前の要素を中心にして配置されます。
window が正の整数の 2 要素ベクトル [b f] である場合、ウィンドウには現在の要素、b 個前までの要素、f 個後までの要素が含まれます。
A が timetable であるか、SamplePoints が datetime ベクトルまたは duration ベクトルとして指定されている場合、window は duration 型でなければならず、ウィンドウはサンプル点を基準に計算されます。
演算の対象の配列次元。正の整数のスカラーとして指定します。値を指定しない場合、既定値は、サイズが 1 ではない最初の配列の次元です。
m 行 n 列の入力行列 A を考えます。
isoutlier(A,1)は、Aの各列のデータに基づいて外れ値を検出し、m行n列の行列を返します。
isoutlier(A,2)は、Aの各行のデータに基づいて外れ値を検出し、m行n列の行列を返します。
入力データが table または timetable の場合、dim はサポートされず、演算は各 table 変数または timetable 変数に沿って個別に行われます。
名前と値の引数
出力引数
詳細
代替機能

参照
[1] NIST/SEMATECH e-Handbook of Statistical Methods, https://www.itl.nist.gov/div898/handbook/, 2013.
拡張機能
バージョン履歴
R2017a で導入参考
関数
rmoutliers|isbetween|ischange|islocalmax|islocalmin|filloutliers|ismissing