rmoutliers
データ内の外れ値の検出と削除
構文
説明
B = rmoutliers(A)A 内のデータの外れ値を検出し、削除します。
Aが行列の場合、rmoutliersはAの各列の外れ値を個別に検出し、その行全体を削除します。Aが table または timetable の場合、rmoutliersはAの各変数の外れ値を個別に検出し、その行全体を削除します。
既定での外れ値とは、中央値からの距離が中央絶対偏差 (MAD) の 3 倍を超えている値です。
rmoutliers の機能を対話的に使用するには、ライブ スクリプトに [外れ値データの削除] タスクを追加します。
B = rmoutliers(___,Name=Value)rmoutliers(A,SamplePoints=t) は時間ベクトル t の対応する要素を基準として A の外れ値を検出します。
例
2 つの外れ値を含むベクトルを作成し、外れ値を削除します。
A = [57 59 60 100 59 58 57 58 300 61 62 60 62 58 57]; B = rmoutliers(A)
B = 1×13
57 59 60 59 58 57 58 61 62 60 62 58 57
平均検出メソッドを使用してデータの timetable にある潜在的な外れ値を特定し、外れ値をすべて削除してからクリーニング済みのデータを可視化します。
データの timetable を作成し、データを可視化して潜在的な外れ値を特定します。
T = hours(1:15); V = [57 59 60 100 59 58 57 58 300 61 62 60 62 58 57]; A = timetable(T',V'); plot(A.Time,A.Var1)

データの外れ値を削除します。ここで、外れ値は平均値から標準偏差の 3 倍を超えた位置にある点として定義されています。
B = rmoutliers(A,"mean")B=14×1 timetable
Time Var1
_____ ____
1 hr 57
2 hr 59
3 hr 60
4 hr 100
5 hr 59
6 hr 58
7 hr 57
8 hr 58
10 hr 61
11 hr 62
12 hr 60
13 hr 62
14 hr 58
15 hr 57
同じグラフに、元のデータと、外れ値が削除されたデータをプロットします。
hold on plot(B.Time,B.Var1,"o-") legend("Original Data","Cleaned Data")

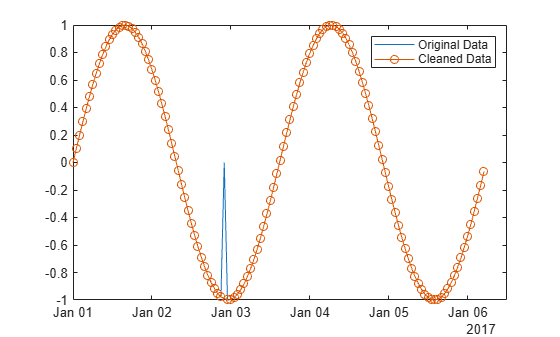
移動中央値を使用して、時間ベクトルに対応する正弦波内の局所外れ値を検出し、削除します。
局所外れ値を含むデータのベクトルを作成します。
x = -2*pi:0.1:2*pi; A = sin(x); A(47) = 0;
A のデータに対応する時間ベクトルを作成します。
t = datetime(2017,1,1,0,0,0) + hours(0:length(x)-1);
外れ値を、スライディング ウィンドウ内の局所中央値から、スケーリングされた局所 MAD の 3 倍を超えた位置にある点として定義します。ウィンドウ サイズを 5 時間に設定し、t の点を基準として A の外れ値の位置を検出し、外れ値を削除します。
[B,TFrm] = rmoutliers(A,"movmedian",hours(5),SamplePoints=t);元のデータと、外れ値が削除されたデータをプロットします。
plot(t,A) hold on plot(t(~TFrm),B,"o-") legend("Original Data","Cleaned Data")
2 つの外れ値を含む行列を作成し、外れ値を削除します。削除された A の行を示す logical の出力ベクトル TFrm が返され、また A の外れ値の位置を示す logical の出力配列 TFoutlier が返されます。
A = [2 290 1 2; 1 0 323 1; 0 2 3 2; 1 1 2 3]
A = 4×4
2 290 1 2
1 0 323 1
0 2 3 2
1 1 2 3
[B,TFrm,TFoutlier] = rmoutliers(A)
B = 2×4
0 2 3 2
1 1 2 3
TFrm = 4×1 logical array
1
1
0
0
TFoutlier = 4×4 logical array
0 1 0 0
0 0 1 0
0 0 0 0
0 0 0 0
A の削除された行の値を調べます。
rmCol = A(TFrm,:)
rmCol = 2×4
2 290 1 2
1 0 323 1
A の外れ値の値を調べます。
rmVal = A(TFoutlier)
rmVal = 2×1
290
323
データの行列から外れ値を削除し、削除された列と外れ値を調べます。
2 つの外れ値を含む行列を作成します。
A = [1 1 1; 1 100 1; 1 100 1; 1 1 100; 1 1 1]
A = 5×3
1 1 1
1 100 1
1 100 1
1 1 100
1 1 1
rmoutliers を使用して、A の各列に沿って外れ値を検出し、少なくとも 1 つの外れ値を含む行をすべて削除します。
B = rmoutliers(A)
B = 2×3
1 1 1
1 1 1
rmoutliers を使用して、A の各列に沿って外れ値を検出し、少なくとも 1 つの外れ値を含む列をすべて削除します。dim を 2 に指定すると、2 番目の次元のデータのサイズが小さくなります。
B = rmoutliers(A,2)
B = 5×1
1
1
1
1
1
2 つの外れ値を含むベクトルを作成し、外れ値の位置を検出します。
A = [57 59 60 100 59 58 57 58 300 61 62 60 62 58 57]; detect = isoutlier(A)
detect = 1×15 logical array
0 0 0 1 0 0 0 0 1 0 0 0 0 0 0
外れ値を削除します。検出メソッドを使用する代わりに、isoutlier によって検出された外れ値の位置を指定します。
B = rmoutliers(A,OutlierLocations=detect)
B = 1×13
57 59 60 59 58 57 58 61 62 60 62 58 57
データのベクトルから外れ値を削除して、クリーニング済みのデータを可視化します。
外れ値を含むデータのベクトルを作成します。
A = [60 59 49 49 58 100 61 57 48 58];
既定の検出メソッド "median" を使用して、外れ値を削除します。
[B,TFrm,TFoutlier,L,U,C] = rmoutliers(A);
元のデータ、外れ値を削除した後のデータ、および検出メソッドで決定されたしきい値と中心値をプロットします。中心値はデータの中央値で、上限および下限しきい値は中央値から上下に MAD の 3 倍離れた値です。
plot(A) hold on plot(find(~TFrm),B,"o-") yline([L U C],":",["Lower Threshold","Upper Threshold","Center Value"]) legend("Original Data","Cleaned Data")

R2024b 以降
table を作成し、10 より大きい値として定義されている外れ値を削除します。削除する外れ値の位置を示す logical 変数 loc の table を作成します。次に、rmoutliers で名前と値の引数 OutlierLocations を使用して、既知の外れ値の位置を指定します。
A = [1; 4; 9; 12; 3]; B = [9; 0; 6; 2; 1]; C = [14; 4; 2; 3; 8]; T = table(A,B,C)
T=5×3 table
A B C
__ _ __
1 9 14
4 0 4
9 6 2
12 2 3
3 1 8
loc = T>10
loc=5×3 table
A B C
_____ _____ _____
false false true
false false false
false false false
true false false
false false false
T = rmoutliers(T,OutlierLocations=loc)
T=3×3 table
A B C
_ _ _
4 0 4
9 6 2
3 1 8
入力引数
名前と値の引数
出力引数
詳細
次の表では、既定の等間隔のサンプル点ベクトル [1 2 3 4 5 6 7] におけるウィンドウ位置を示します。
説明 | ウィンドウ サイズと位置 | ウィンドウ内のサンプル点 | 図 |
|---|---|---|---|
スカラー ウィンドウ サイズの場合、ウィンドウの先頭のエッジは含まれず、ウィンドウの後方のエッジは含まれます。 |
現在のサンプル点 = 4 | 3、4、5 |
|
現在のサンプル点 = 4 | 2、3、4、5 |
| |
ベクトル ウィンドウ サイズの場合、先頭のエッジおよび後方のエッジは含まれます。 |
現在のサンプル点 = 4 | 2、3、4、5、6 |
|
入力データの端点に近いサンプル点について、最初のサンプル点から開始するか最後のサンプル点で終了するように |
現在のサンプル点 = 2 | 1、2、3、4 |
|


![Given elements 1 to 7, if the current sample point is 4, then the corresponding window spans the range [2, 6].](movwindow_vector.png)
![Given elements 1 to 7, if the current sample point is 2, then the corresponding window spans the range [1, 4].](movwindow_edgetruncate.png)
