このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
ischange
データの急激な変化の検出
構文
説明
TF = ischange(___,Name,Value)ischange(A,'MaxNumChanges',m) は m 個以下の変化点を検出します。
例
ノイズを含むデータのベクトルを作成し、データの平均値の急激な変化を計算します。
A = [ones(1,5) 25*ones(1,5) 50*ones(1,5)] + rand(1,15); TF = ischange(A)
TF = 1×15 logical array
0 0 0 0 0 1 0 0 0 0 1 0 0 0 0
変化点間のデータの平均値を計算するには、2 番目の出力引数を指定します。
[TF,S1] = ischange(A); plot(A,'*') hold on stairs(S1) legend('Data','Segment Mean','Location','NW')

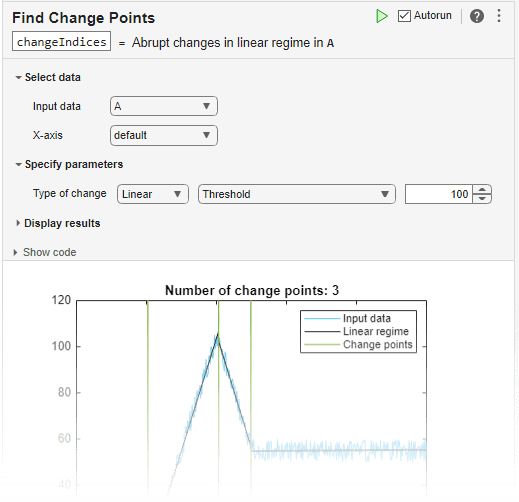
ノイズを含むデータのベクトルを作成し、データの傾きと切片の急激な変化を計算します。検出しきい値を大きく設定すると、ノイズが原因で検出される変化点の数が少なくなります。
A = [zeros(1,100) 1:100 99:-1:50 50*ones(1,250)] + 10*rand(1,500); [TF,S1,S2] = ischange(A,'linear','Threshold',200); segline = S1.*(1:500) + S2; plot(1:500,A,1:500,segline) legend('Data','Linear Regime')

しきい値を指定する代わりに、検出する変化点の最大数を指定することもできます。
[TF,S1,S2] = ischange(A,'linear','MaxNumChanges',3);
行列の各行について、平均値の急激な変化を計算します。
A = diag(25*ones(5,1)) + rand(5,5)
A = 5×5
25.8147 0.0975 0.1576 0.1419 0.6557
0.9058 25.2785 0.9706 0.4218 0.0357
0.1270 0.5469 25.9572 0.9157 0.8491
0.9134 0.9575 0.4854 25.7922 0.9340
0.6324 0.9649 0.8003 0.9595 25.6787
TF = ischange(A,2)
TF = 5×5 logical array
0 1 0 0 0
0 1 1 0 0
0 0 1 1 0
0 0 0 1 1
0 0 0 0 1
入力引数
入力データ。ベクトル、行列、多次元配列、table または timetable として指定します。
データ型: single | double | table | timetable
変化検出メソッド。次の値のいずれかとして指定します。
'mean'— データの平均値の急激な変化を検出。'variance'— データの分散の急激な変化を検出。'linear'— データの傾きと切片の急激な変化を検出。
操作次元。正の整数スカラーとして指定します。値を指定しない場合、既定値は、サイズが 1 ではない最初の配列の次元です。
m 行 n 列の入力行列 A を考えます。
ischange(A,1)は、Aの各列のデータに基づいて変化点を検出し、m行n列の行列を返します。
ischange(A,2)は、Aの各行のデータに基づいて変化点を検出し、m行n列の行列を返します。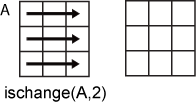
入力データが table または timetable の場合、dim はサポートされず、演算は各 table 変数または timetable 変数に沿って個別に行われます。
名前と値の引数
出力引数
アルゴリズム
データのベクトル A を、次の式を満たすように A1 と A2 の 2 つのセグメントに分割できる場合、このベクトルには変化点が含まれています。
は Threshold パラメーターで指定されたしきい値で、C はコスト関数を表します。
たとえば、平均値の急激な変化を検出するコスト関数は です。ここで、N はベクトル x の要素数です。コスト関数は、セグメントが平均値によりどの程度近似されているかを測定します。
ischange はコスト関数の合計を繰り返し最小化し、次の式を満たす変化点の数 k とその場所を判定します。
代替機能
参照
[1] Killick R., P. Fearnhead, and I.A. Eckley. "Optimal detection of changepoints with a linear computational cost." Journal of the American Statistical Association. Vol. 107, Number 500, 2012, pp.1590-1598.