gscatter
グループ別の散布図
構文
説明
例
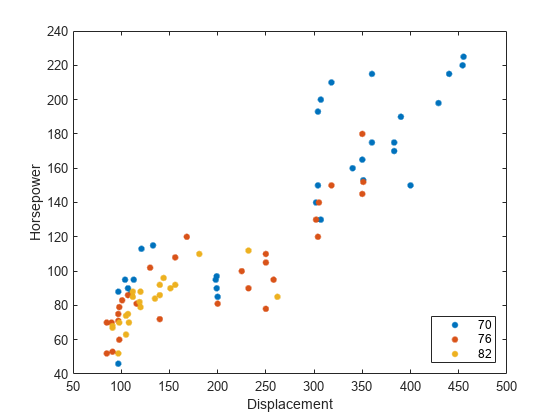
carsmall データ セットを読み込みます。
load carsmallDisplacement の値を x 軸に、Horsepower の値を y 軸にプロットします。gscatter は、座標軸の既定ラベルとして変数名を使用します。Model_Year によってデータ点をグループ化します。
gscatter(Displacement,Horsepower,Model_Year)
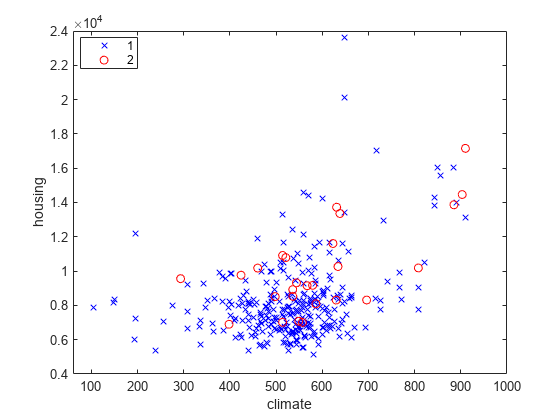
discrim データ セットを読み込みます。
load discrimデータ セットには、9 種類の要素 (気候、住宅、教育、健康など) に基づく都市の評価が含まれています。行列 ratings には評価の情報が含まれています。
気候 (1 列目) と住宅 (2 列目) の評価について、行列 group 内の都市の規模別にグループ化して関係性をプロットします。グループごとに異なる色とプロットのシンボルを選択します。
gscatter(ratings(:,1),ratings(:,2),group,'br','xo') xlabel('climate') ylabel('housing')
hospital データ セットを読み込みます。
load hospital入院患者の年齢と体重をプロットします。性別および喫煙者の現状によって患者をグループ化します。o 記号を使用して非喫煙者を表し、* 記号を使用して喫煙者を表します。
x = hospital.Age;
y = hospital.Weight;
g = {hospital.Sex,hospital.Smoker};
gscatter(x,y,g,'rkgb','o*',8,'on','Age','Weight')
legend('Location','northeastoutside')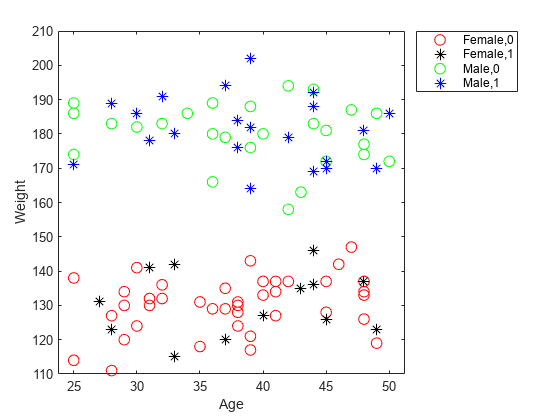
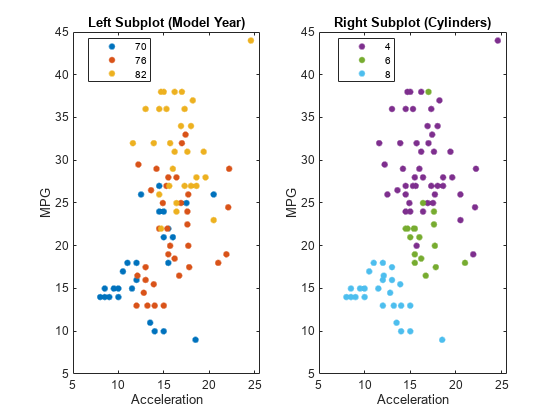
carsmall データ セットを読み込みます。2 つのサブプロットを使用して Figure を作成し、ax1 および ax2 として axes オブジェクトを返します。対応する Axes オブジェクトを参照し、各座標軸のセットで散布図を作成します。左のサブプロットでは、変数 Model_Year を使用してデータをグループ化します。右のサブプロットでは、変数 Cylinders を使用してデータをグループ化します。対応する Axes オブジェクトを関数 title に渡すことによって、各プロットにタイトルを追加します。
load carsmall color = lines(6); % Generate color values ax1 = subplot(1,2,1); % Left subplot gscatter(ax1,Acceleration,MPG,Model_Year,color(1:3,:)) title(ax1,'Left Subplot (Model Year)') ax2 = subplot(1,2,2); % Right subplot gscatter(ax2,Acceleration,MPG,Cylinders,color(4:6,:)) title(ax2,'Right Subplot (Cylinders)')
関数hsvによって決定されるカラーマップを使用してマーカーの色を指定します。
自動車の周囲にある物体の座標を含む 3 次元の点の集合として格納された LIDAR スキャン データ セットを読み込みます。
load('lidar_subset.mat')
loc = lidar_subset;自動車の周囲の環境を強調するため、道路表面の上部の領域で自動車の左右 20 メートルおよび前後 20 メートルにわたるように関心領域を設定します。
xBound = 20; % in meters yBound = 20; % in meters zLowerBound = 0; % in meters
指定した領域内の点のみが含まれるようにデータをトリミングします。
indices = loc(:,1) <= xBound & loc(:,1) >= -xBound ... & loc(:,2) <= yBound & loc(:,2) >= -yBound ... & loc(:,3) > zLowerBound; loc = loc(indices,:);
ペアワイズ距離で dbscan を使用して、データをクラスター化します。
D = pdist2(loc,loc); idx = dbscan(D,2,50,'Distance','precomputed');
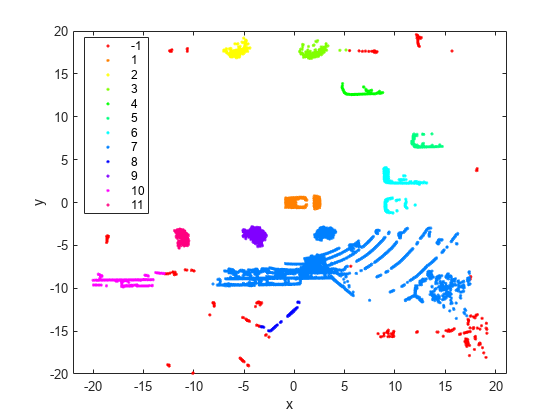
関数 gscatter を使用して、結果のクラスターを 2 次元グループ散布図として可視化します。既定では、gscatter は MATLAB の既定の 7 色を使用します。一意のクラスターの数が 7 を超えると、この関数は必要に応じて既定の色を繰り返して使います。クラスター数を求め、関数 hsv を使用して対応する数の色を生成します。マーカーの色を指定して、クラスターごとに一意の色を使用します。
numGroups = length(unique(idx)); clr = hsv(numGroups); gscatter(loc(:,1),loc(:,2),idx,clr) xlabel('x') ylabel('y')
carbig データ セットを読み込みます。
load carbigAcceleration と MPG を比較する散布図を作成します。Origin に基づいてデータ点をグループ化します。
h = gscatter(Acceleration,MPG,Origin)
h = 7×1 Line array: Line (USA) Line (France) Line (Japan) Line (Germany) Line (Sweden) Line (Italy) Line (England)
(Japan) というラベルのグループに対応する Line オブジェクトを表示します。
jgroup = h(3)
jgroup =
Line (Japan) with properties:
Color: [0.9294 0.6941 0.1255]
LineStyle: 'none'
LineWidth: 0.5000
Marker: '.'
MarkerSize: 12
MarkerFaceColor: 'none'
XData: [15 14.5000 14.5000 14 19 18 15.5000 13.5000 17 14.5000 16.5000 19 16.5000 13.5000 13.5000 19 21 16.5000 19 15 15.5000 16 13.5000 17 17.5000 17.4000 17 16.4000 15.5000 18.5000 16.8000 18.2000 16.4000 14.5000 13.5000 … ] (1×79 double)
YData: [24 27 27 25 31 35 24 19 28 23 27 20 22 18 20 31 32 31 32 24 26 29 24 24 33 33 32 28 19 31.5000 33.5000 26 30 22 21.5000 32.8000 39.4000 36.1000 27.5000 27.2000 21.1000 23.9000 29.5000 34.1000 31.8000 38.1000 37.2000 … ] (1×79 double)
Show all properties
Japan グループのマーカーの色を黒に変更します。
jgroup.Color = 'k';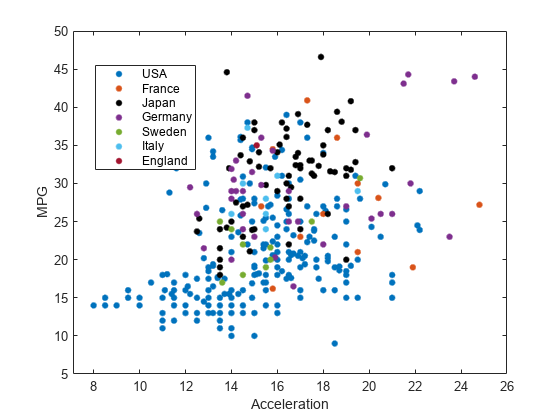
入力引数
x 軸の値。数値ベクトルを指定します。x のサイズは y と同じでなければなりません。
データ型: single | double
y 軸の値。数値ベクトルを指定します。y のサイズは x と同じでなければなりません。
データ型: single | double
グループ化変数。categorical ベクトル、logical ベクトル、数値ベクトル、文字配列、string 配列、または文字ベクトルの cell 配列を指定します。g は、いくつかのグループ化変数 ({g1 g2 g3} など) を含む cell 配列となることもあります。この場合、グループ化変数のすべてについて共通の値をもつ場合、観測は同じグループに属します。同じグループの点は、同じマーカーの色、記号およびサイズで散布図に表示されます。
g の行数と x の長さは等しくなければなりません。
例: species
例: {Cylinders,Origin}
データ型: categorical | logical | single | double | char | string | cell
マーカーの色。文字ベクトルまたは string スカラーによる色の省略名、または RGB 3 成分の行列を指定します。
カスタム色の場合は、RGB 3 成分の行列を指定します。RGB 3 成分は、色の赤、緑、青成分の強度を指定する 3 要素の行ベクトルです。強度は範囲 [0,1] に含まれていなければなりません。たとえば [0.4 0.6 0.7] のようになります。
あるいは、一部の一般的な色を名前で指定できます。次の表は、名前が付いた色のオプションおよび等価な RGB 3 成分の一覧です。
| 省略名 | RGB 3 成分 | 外観 |
|---|---|---|
'r' | [1 0 0] |
|
'g' | [0 1 0] |
|
'b' | [0 0 1] |
|
'c' | [0 1 1] |
|
'm' | [1 0 1] |
|
'y' | [1 1 0] |
|
'k' | [0 0 0] |
|
'w' | [1 1 1] |
|








以下は、MATLAB が多くのタイプのプロットで使用する既定の色に対する RGB 3 成分のカラー コードです。
| RGB 3 成分 | 外観 |
|---|---|
[0 0.4470 0.7410] |
|
[0.8500 0.3250 0.0980] |
|
[0.9290 0.6940 0.1250] |
|
[0.4940 0.1840 0.5560] |
|
[0.4660 0.6740 0.1880] |
|
[0.3010 0.7450 0.9330] |
|
[0.6350 0.0780 0.1840] |
|
![Sample of RGB triplet [0 0.4470 0.7410], which appears as dark blue](colororder1.png)
![Sample of RGB triplet [0.8500 0.3250 0.0980], which appears as dark orange](colororder2.png)
![Sample of RGB triplet [0.9290 0.6940 0.1250], which appears as dark yellow](colororder3.png)
![Sample of RGB triplet [0.4940 0.1840 0.5560], which appears as dark purple](colororder4.png)
![Sample of RGB triplet [0.4660 0.6740 0.1880], which appears as medium green](colororder5.png)
![Sample of RGB triplet [0.3010 0.7450 0.9330], which appears as light blue](colororder6.png)
![Sample of RGB triplet [0.6350 0.0780 0.1840], which appears as dark red](colororder7.png)
clr の既定値は、MATLAB の既定の色を含む RGB 3 成分の行列です。
g の一意のグループすべてに対して十分な色が指定されていない場合、gscatter は clr で指定された値を繰り返して使います。一意のグループの数が既定の色の数 (7) を超える場合に既定値を使用すると、gscatter は必要に応じて既定値を繰り返して使います。
例: 'rgb'
例: [0 0 1; 0 0 0]
データ型: char | string | single | double
マーカーの記号。関数 plot が認識する記号の文字ベクトルまたは string スカラーを指定します。次の表は、使用できるマーカーの記号の一覧です。
| 値 | 説明 |
|---|---|
'o' | 円 |
'+' | プラス記号 |
'*' | アスタリスク |
'.' | 点 |
'x' | 十字 |
's' | 正方形 |
'd' | 菱形 |
'^' | 上向き三角形 |
'v' | 下向き三角形 |
'>' | 右向き三角形 |
'<' | 左向き三角形 |
'p' | 星形五角形 |
'h' | 星形六角形 |
'n' | マーカーなし |
十分な値が指定されていないグループがある場合、必要に応じて gscatter は指定された値を繰り返します。
例: 'o+*v'
データ型: char | string
マーカーのサイズ。ポイント単位の正の数値ベクトルを指定します。既定値は、観測値の個数によって決定されます。十分な値が指定されていないグループがある場合、必要に応じて gscatter は指定された値を繰り返します。
例: [6 12]
データ型: single | double
凡例を含めるオプション。'on' または 'off' のいずれかを指定します。既定では、凡例がグラフに表示されます。
x 軸のラベル。文字ベクトルまたは string スカラーを指定します。
データ型: char | string
y 軸のラベル。文字ベクトルまたは string スカラーを指定します。
データ型: char | string
マーカーの内側を塗りつぶすオプション。"filled" として指定します。このオプションは、"o" や "s" などの内側があるマーカーに使用します。gscatter は、"." や "+" などの内側がないマーカーについては "filled" を無視します。
データ型: string