grpstats
グループ別に整理された要約統計量
構文
説明
tblstats = grpstats(tbl,groupvars,whichstats)whichstats を指定します。
tblstats = grpstats(tbl,groupvars,whichstats,Name,Value)"DataVars",[2,4] は、tbl 内で 2 番目と 4 番目の変数の要約統計量を計算するよう関数に指示します。
[ は、要約統計量のタイプ stats1,...,statsN] = grpstats(X,group,whichstats)whichstats を指定し、要約統計量ごとに 1 つの配列を返します。
[ は、信頼区間と予測区間の有意水準 stats1,...,statsN] = grpstats(X,group,whichstats,"Alpha",a)a も指定します。
grpstats( は、X,group,alpha)group 内の変数でグループ化された数値行列または logical 行列 X 内のデータのグループ平均をプロットします。この関数は、各グループ平均の信頼区間 100×(1 – alpha)% もプロットします。グループ化変数の値が横軸に沿ってプロットされます。
Xが行列である場合、grpstatsはXの各列につき平均値と信頼区間をプロットします。groupがグループ化変数の cell 配列である場合、grpstatsはグループの平均値および信頼区間をプロットします。このグループは、グループ化変数の観測された一意の組み合わせで決定されます。
例
table 内にある入力データの要約統計量を計算します。1 つまたは 2 つのグループ化変数を使用して入力データをグループ化し、計算する要約統計量の 1 つまたは 2 つのタイプを指定します。
patients データ セットを読み込みます。
load patients変数 Gender、Age、Weight、Smoker を格納する table を作成します。
tbl = table(Gender,Age,Weight,Smoker);
Gender は、2 つの一意の値 Male および Female をもつ cell 配列です。Age と Weight の各変数は数値の値をとり、Smoker は論理値をとります。
Gender でグループ化された tbl 内の数値配列と logical 配列の平均を計算します。
tblstats1 = grpstats(tbl,"Gender")tblstats1=2×5 table
Gender GroupCount mean_Age mean_Weight mean_Smoker
__________ __________ ________ ___________ ___________
Male {'Male' } 47 38.915 180.53 0.44681
Female {'Female'} 53 37.717 130.47 0.24528
tblstats1 は、Gender の一意の値に対応する 2 行をもつ table です。GroupCount 列は、各グループの観測値の数を示します。列 mean_Age、mean_Weight および mean_Smoker は、Gender でグループ化された Age、Weight および Smoker の平均を示します。
Smoker の値でグループ化された Age と Weight の平均を計算します。名前と値の引数 DataVars を使用して、要約統計量の計算対象となる変数として Age と Weight を指定します。入力 tbl に cell 配列である変数 Gender が含まれており、組み込みの要約統計量 mean は数値配列と logical 配列に対してのみ有効であるため、DataVars を使用する必要があります。
tblstats2 = grpstats(tbl,"Smoker","mean","DataVars",["Age","Weight"])
tblstats2=2×4 table
Smoker GroupCount mean_Age mean_Weight
______ __________ ________ ___________
0 false 66 37.97 149.91
1 true 34 38.882 161.94
Gender と Smoker の値の組み合わせによってグループ化された、体重の最小値と最大値を計算します。
tblstats3 = grpstats(tbl,["Gender","Smoker"],["min","max"], ... "DataVars","Weight")
tblstats3=4×5 table
Gender Smoker GroupCount min_Weight max_Weight
__________ ______ __________ __________ __________
Male_0 {'Male' } false 26 158 194
Male_1 {'Male' } true 21 164 202
Female_0 {'Female'} false 40 111 147
Female_1 {'Female'} true 13 115 146
Smoker と Gender はそれぞれ 2 つの一意の値をもつため、出力 table には、次の可能な組み合わせの 4 行が含まれます。Male Nonsmoker (Male_0)、Male Smoker (Male_1)、Female Nonsmoker (Female_0) および Female Smoker (Female_1)。
名前と値の引数 VarNames を使用して、出力で列に名前を指定します。
tblstats4 = grpstats(tbl,["Gender","Smoker"],["min","max"], ... "DataVars","Weight", ... "VarNames",["Gender","Smoker","Group Count", ... "Lowest Weight","Highest Weight"])
tblstats4=4×5 table
Gender Smoker Group Count Lowest Weight Highest Weight
__________ ______ ___________ _____________ ______________
Male_0 {'Male' } false 26 158 194
Male_1 {'Male' } true 21 164 202
Female_0 {'Female'} false 40 111 147
Female_1 {'Female'} true 13 115 146
行列内にある入力データのグループ平均を計算します。1 つまたは 2 つのグループ化変数を使用して入力データをグループ化します。
100 台の自動車の測定値を含む carsmall データ セットを読み込みます。
load carsmall変数 Origin および Cylinders でグループ化された変数 Acceleration のグループ平均を計算します。変数 Acceleration は 0 ~ 60 MPH の時間 (秒単位) です。グループ化変数 Origin は各自動車の生産国 (フランス、ドイツ、イタリア、日本、スウェーデン、米国) です。グループ化変数 Cylinders には、各自動車に搭載された気筒の数を示す 3 つの一意の値 4、6 および 8 が含まれています。
生産国ごとにグループ化された平均加速度を計算します。
means = grpstats(Acceleration,Origin)
means = 6×1
14.4377
18.0500
15.8867
16.3778
16.6000
15.5000
means は 6 行 1 列の平均加速度のベクトルで、各値が生産国に対応します。
生産国と気筒の数でグループ化された平均加速度を計算します。各グループのグループ名と平均加速度を返します。
[means,grps] = grpstats(Acceleration,{Origin,Cylinders}, ...
["mean","gname"])means = 10×1
17.0818
16.5267
11.6406
18.0500
15.9143
15.5000
16.3375
16.7000
16.6000
15.5000
grps = 10×2 cell
{'USA' } {'4'}
{'USA' } {'6'}
{'USA' } {'8'}
{'France' } {'4'}
{'Japan' } {'4'}
{'Japan' } {'6'}
{'Germany'} {'4'}
{'Germany'} {'6'}
{'Sweden' } {'4'}
{'Italy' } {'4'}
2 つのグループ化変数 Origin および Cylinders では 18 種類の組み合わせが可能です。Origin には 6 つの一意の値が、Cylinders には 3 つの一意の値があるためです。この可能な組み合わせの中でデータに含まれるのは 10 個だけなので、means は実際に観測された値の組み合わせに対応して、10 行 1 列のベクトルとなります。出力 grps には、グループ化変数の値が観測された 10 個の組み合わせが含まれています。たとえば、フランスで生産された 4 気筒車の平均加速度は 18.05 です。
行列内にある入力データの複数のグループ要約統計量を計算します。
100 台の自動車の測定値を含む carsmall データ セットを読み込みます。
load carsmall変数 Origin でグループ化された変数 Acceleration のグループ要約統計量を計算します。変数 Acceleration は 0 ~ 60 MPH の時間 (秒単位) で、グループ化変数 Origin は各自動車の生産国 (フランス、ドイツ、イタリア、日本、スウェーデン、米国) です。
生産国ごとにグループ化された最小と最大の加速度を返します。
[grpMin,grpMax,grp] = grpstats(Acceleration,Origin, ... ["min","max","gname"])
grpMin = 6×1
8.0000
15.3000
13.9000
12.2000
15.7000
15.5000
grpMax = 6×1
22.2000
21.9000
18.2000
24.6000
17.5000
15.5000
grp = 6×1 cell
{'USA' }
{'France' }
{'Japan' }
{'Germany'}
{'Sweden' }
{'Italy' }
加速度が一番低い自動車は米国製、一番高い自動車はドイツ製です。
table 内にある入力データの要約統計量を計算します。グループ化変数に対して [] を渡して、grpstats でグループ化を使用せずに要約統計量が計算されるようにします。
patients データ セットを読み込みます。
load patients変数 Age、Weight、Smoker を格納する table を作成します。
tbl = table(Age,Weight,Smoker);
Age と Weight の各変数は数値の値をとり、Smoker は論理値をとります。
数値配列 Age および Weight と logical 配列 Smoker には、グループ化を行わずに平均、最小値および最大値を計算します。
tblstats = grpstats(tbl,[],["mean","min","max"])
tblstats=1×10 table
GroupCount mean_Age min_Age max_Age mean_Weight min_Weight max_Weight mean_Smoker min_Smoker max_Smoker
__________ ________ _______ _______ ___________ __________ __________ ___________ __________ __________
All 100 38.28 25 50 154 111 202 0.34 false true
観測名の All は、grpstats が要約統計量の計算に tbl 内に存在する観測をすべて使用することを示します。
行列内にある入力データの各グループの平均と予測区間を計算してプロットします。
100 台の自動車の測定値を含む carsmall データ セットを読み込みます。
load carsmall変数 Model_Year でグループ化された変数 Weight のグループ要約統計量を計算します。変数 Weight には自動車の重量値が含まれ、グループ化変数 Model_Year は 1970、1976 および 1982 のモデル年式を表す 3 つの一意の値 70、76、82 をもちます。
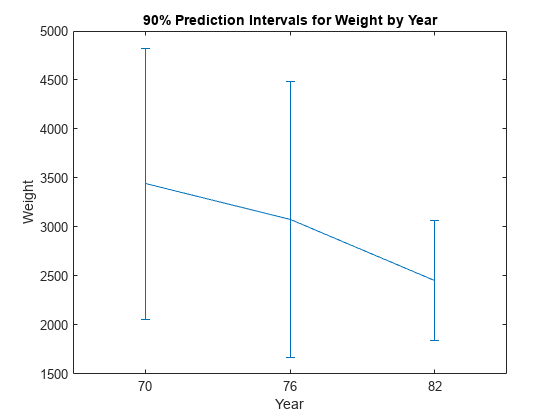
各モデル年式の平均重量と 90% の予測区間を計算します。
[means,pred,grp] = grpstats(Weight,Model_Year, ... ["mean","predci","gname"],"Alpha",0.1);
モデル年式によりグループ化された、平均重量と 90% の予測区間を示す誤差範囲をプロットします。横軸の目盛りラベルをグループ名として指定します。
f = figure; ngrps = length(grp); % Number of groups errorbar((1:ngrps)',means,pred(:,2)-means) xlim([0.5 3.5]) f.CurrentAxes.XTick = 1:ngrps; f.CurrentAxes.XTickLabel = grp; title("90% Prediction Intervals for Weight by Year") xlabel("Year") ylabel("Weight")
行列内にある入力データのグループ平均と信頼区間をプロットします。1 つまたは 2 つのグループ化変数を使用して入力データをグループ化し、要約統計量をプロットする 1 つまたは 2 つの変数を指定します。
100 台の自動車の測定値を含む carsmall データ セットを読み込みます。
load carsmall変数 Acceleration は 0 ~ 60 MPH の時間 (秒単位) です。グループ化変数 Cylinders は各自動車に搭載された気筒の数です。
気筒によりグループ化された、信頼区間 95% の平均加速度をプロットします。
grpstats(Acceleration,Cylinders,0.05);
legend("Acceleration")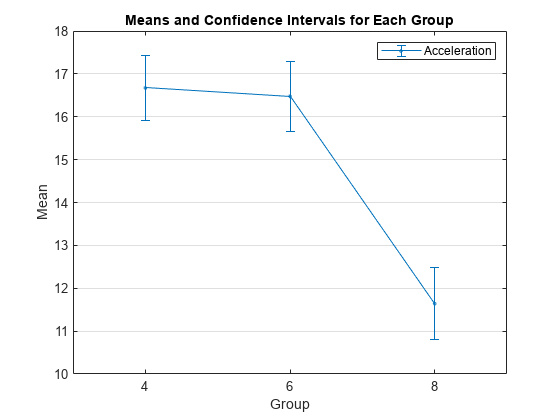
8 気筒が搭載された車の平均加速度は、4 気筒車や 6 気筒車よりも大幅に低いことがわかります。
変数 Weight は各自動車の重量値です。気筒によりグループ化された、信頼区間 95% の平均加速度と重量をプロットします。Weight と Acceleration の平均値が同じ桁で扱えるよう、Weight の値を 1000 で除算します。
grpstats([Acceleration,Weight/1000],Cylinders,0.05); legend("Acceleration","Weight/1000")

気筒の数が増えるにつれて自動車の平均重量は多くなり、平均加速度は低下します。
変数 Model_Year は 1970、1976 および 1982 のモデル年式を表す 3 つの一意の値 70、76、82 をもちます。気筒とモデル年式でグループ化された平均加速度をプロットします。信頼区間は 95% に指定します。
grpstats(Acceleration,{Cylinders,Model_Year},0.05);
legend("Acceleration")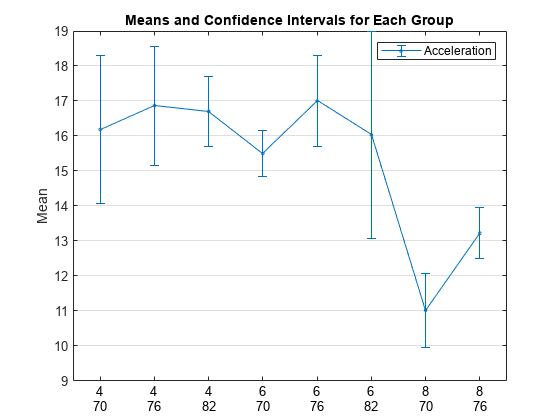
2 つのグループ化変数 Cylinders および Model_Year では 9 種類の値の組み合わせが可能です。各変数には 3 つの一意の値があるためです。プロットには 8 気筒を搭載した車の 1982 年モデルが表示されません。これはデータにそのような組み合わせが含まれていないためです。
1976 年モデルの 8 気筒車の平均加速度は、1970 年モデルの 8 気筒車よりも大幅に高いことがわかります。
カスタム要約統計量を定義するには、無名関数を使用します。grpstats に無名関数を渡して、入力データの各グループのカスタム要約統計量を計算します。
patients データ セットを読み込みます。
load patients変数 Age、Smoker、LastName を格納する table を作成します。
tbl = table(Age,Smoker,LastName);
入力行列の各列の合計を計算するカスタム関数を使用して、各年齢グループの喫煙者数を求めます。
f_sum = @(x)sum(x,1); tblstats1 = grpstats(tbl,"Age",f_sum,"DataVars","Smoker", ... "VarNames",["Age","Group Count","Number of Smokers"])
tblstats1=25×3 table
Age Group Count Number of Smokers
___ ___________ _________________
25 25 6 1
27 27 1 1
28 28 5 2
29 29 3 0
30 30 4 1
31 31 4 2
32 32 4 1
33 33 3 3
34 34 1 0
35 35 2 0
36 36 4 0
37 37 5 2
38 38 6 2
39 39 8 3
40 40 4 1
41 41 3 0
⋮
tblstats1 は、Age の一意の値に対応する 25 行をもつ table です。Group Count 列は各年齢グループの観測値の数を示し、最後の列は各グループの喫煙者数を示します。
cell 配列の要素の平均長さを計算するカスタム関数を使用して、各年齢グループの姓の平均長さを特定します。
f_length = @(x)mean(cellfun("length",x)); tblstats2 = grpstats(tbl,"Age",f_length,"DataVars","LastName", ... "VarNames",["Age","Group Count","Mean Length of Last Name"])
tblstats2=25×3 table
Age Group Count Mean Length of Last Name
___ ___________ ________________________
25 25 6 5.6667
27 27 1 6
28 28 5 5.4
29 29 3 5.6667
30 30 4 6.5
31 31 4 5.25
32 32 4 6.5
33 33 3 6.3333
34 34 1 9
35 35 2 7.5
36 36 4 6.25
37 37 5 8.2
38 38 6 5.8333
39 39 8 6.125
40 40 4 5.5
41 41 3 5.3333
⋮
入力引数
名前と値の引数
出力引数
アルゴリズム
grpstatsは、グループ化変数にある観測された一意の値または値の組み合わせごとに要約統計量値を計算します。単一のグループ化変数を指定した場合、
grpstatsの出力には、グループ化変数の観測された一意の値ごとに 1 つの行が含まれます。grpstatsは、出現順 (グループ化変数が文字ベクトルまたは string スカラーである場合)、数値の昇順 (グループ化変数が数値である場合) またはカテゴリ順 (グループ化変数が categorical である場合) にグループを並べ替えます。複数のグループ化変数を指定した場合、
grpstatsの出力には、グループ化変数にある観測された一意の値の組み合わせごとに 1 つの行が含まれます。たとえば、2 つのグループ化変数を指定して、その各変数が 2 つの値をもつ場合、出力に含まれるグループ化変数の値の可能な組み合わせは 4 つです。この関数は、可能なすべての組み合わせではなく、入力されたグループ化変数に含まれている観測された組み合わせについてのみ要約統計量を計算します。grpstatsは、最初に 1 番目のグループ化変数の値、次に 2 番目のグループ化変数の値 (以後も同様) という順序でグループを並べ替えます。
grpstatsはtbl、X、およびgroupの欠損値を無視します。欠損値はデータ型に応じて異なります。NaN(double、single、duration、およびcalendarDurationの場合)NaT(datetimeの場合)<missing>(stringの場合)<undefined>(categoricalの場合)' '(charの場合){''}(文字ベクトルのcellの場合)
代替機能
MATLAB® には関数 groupsummary が含まれます。この関数もグループ要約を返す関数であり、table を処理する際に推奨されます。groupsummary を使用すると、欠損値で構成されるグループと出力にゼロ要素があるグループを含めるかどうかを指定できます。また、この関数は、さまざまなグループ ビン化スキームや、カスタム要約統計量を得るために複数の入力引数を必要とする無名関数をサポートします。
拡張機能
バージョン履歴
R2006a より前に導入