対話型分散配列の取り扱い
MATLAB ソフトウェアによる配列の分散方法
配列を複数のワーカーに分散する際、MATLAB® ソフトウェアは配列をセグメントに分割し、配列のセグメントの 1 つを各ワーカーに割り当てます。2 次元の配列を横移動で分割し、元の配列の列を別々のワーカーに割り当てるか、縦移動で分割して行を割り当てることができます。N 次元の配列は N 個ある任意の次元に沿って分割できます。配列のどの次元を分割するかの選択は、配列コンストラクター コマンドで指定します。
たとえば、80 行 1000 列の配列を 4 つのワーカーに分散するには、列で分割して各ワーカーに 80 行 250 列のセグメントを割り当てるか、または行で分割して各ワーカーに 20 行 1000 列のセグメントを割り当てることができます。配列の次元がワーカー数で等分されない場合、MATLAB はそれをできるだけ均等に分割します。
次の例では、80 行 1000 列の複製された配列を作成し、これを変数 A に代入しています。その際、各ワーカーは同一の配列を自身のワークスペースに作成し、変数 A に代入します。ここで、A はそのワーカーに対しローカルです。2 番目のコマンドは A を分散し、4 つのワーカーすべてにまたがる単一の 80 行 1000 列の配列 D を作成します。ワーカー 1 は列 1 ~ 250 を保存し、ワーカー 2 は列 251 ~ 500 を保存する、といった形で分担がなされます。既定の分散は大きさが 1 ではない最後の次元によって行われ、したがって、この 2 次元配列の場合は列単位で行われます。
spmd A = zeros(80, 1000); D = codistributed(A) end
Worker 1: This worker stores D(:,1:250).
Worker 2: This worker stores D(:,251:500).
Worker 3: This worker stores D(:,501:750).
Worker 4: This worker stores D(:,751:1000).
各ワーカーは配列の全セグメントにアクセスできます。ローカル セグメントへのアクセスはリモート セグメントへのアクセスよりも高速です。リモート セグメントではワーカー間でのデータ送受信が必要になり、より長い時間がかかるためです。
MATLAB による対話型分散配列の表示方法
各ワーカーについて、MATLAB Parallel Command Window には、対話型分散配列、そのローカル部分および対話型分散に関する情報が表示されます。たとえば、4 つのワーカーに、ワーカーあたり 2 列ずつ対話型分散される 8 行 8 列の単位行列は、以下のように表示されます。
>> spmd II = eye(8,"codistributed") end
Worker 1:
This worker stores II(:,1:2).
LocalPart: [8x2 double]
Codistributor: [1x1 codistributor1d]
Worker 2:
This worker stores II(:,3:4).
LocalPart: [8x2 double]
Codistributor: [1x1 codistributor1d]
Worker 3:
This worker stores II(:,5:6).
LocalPart: [8x2 double]
Codistributor: [1x1 codistributor1d]
Worker 4:
This worker stores II(:,7:8).
LocalPart: [8x2 double]
Codistributor: [1x1 codistributor1d]配列のローカル セグメントの実際のデータを確認するには、関数 getLocalPart を使用します。
各ワーカーに分散される量
N 行からなる配列を分散する際、N がワーカー数に等分できる場合は MATLAB により各ワーカーに同数 (N/spmdSize) の行が格納されます。この数がワーカー数で割り切れない場合、MATLAB は配列をできるだけ均等に分割します。
MATLAB には Dimension と Partition という対話型分散オブジェクト プロパティがあり、配列の正確な分散の決定に使用できます。対話型分散配列でのインデックス付けの詳細については、対話型分散配列のインデックス付けを参照してください。
その他のデータ型の分散
任意の MATLAB 組み込みデータ型の配列や、複素数またはスパースの数値配列は分散できますが、関数ハンドルやオブジェクト タイプの配列は分散できません。
対話型分散配列の作成
対話型分散配列は、次のいずれかの方法で作成できます。
大きな配列の分割 — すべてのワーカー上で複製された大きな配列から始め、それを分割して各部分をワーカーに分散します。これは、最初の複製された配列を格納する十分なメモリがある場合に最も役に立ちます。
小さな配列からの作成 — 各ワーカーに格納された小さなバリアント配列または複製された配列から始め、それらを結合して、各配列を大きな対話型分散配列のセグメントにします。この方法では、小さな部分から対話型分散配列を作成できるため、メモリ要件が少なくて済みます。
MATLAB コンストラクター関数の使用 —
randやzerosなど任意の MATLAB コンストラクター関数を対話型分散オブジェクトの引数と共に使用します。これらの関数により、任意サイズの対話型分散配列をワン ステップですばやく作成できます。
大きな配列の分割
大きい配列が既にメモリに格納されており、MATLAB でより迅速に処理する場合は、それを小さなセグメントに分割し、関数 codistributed を使用してすべてのワーカーに分散することができます。これにより、各ワーカーに設定される配列のサイズが元の配列のごく一部となるため、各ワーカーのローカル データへのアクセスにかかる時間が短縮されます。
単純な例として、以下のコード行は変数 A に代入される 4 行 8 列の複製された行列を各ワーカーに作成します。
spmd, A = [11:18; 21:28; 31:38; 41:48], end
A =
11 12 13 14 15 16 17 18
21 22 23 24 25 26 27 28
31 32 33 34 35 36 37 38
41 42 43 44 45 46 47 48次の行は、関数 codistributed を使用して単一の 4 行 8 列の行列 D を作成し、配列の 2 番目の次元に沿ってこれを分散しています。
spmd D = codistributed(A); getLocalPart(D) end
1: Local Part | 2: Local Part | 3: Local Part | 4: Local Part
11 12 | 13 14 | 15 16 | 17 18
21 22 | 23 24 | 25 26 | 27 28
31 32 | 33 34 | 35 36 | 37 38
41 42 | 43 44 | 45 46 | 47 48配列 A と配列 D は同じサイズ (4 行 8 列) です。配列 A が各ワーカーにフル サイズで格納されるのに対し、配列 D は各ワーカーに 1 セグメントのみが格納されます。
spmd, size(A), size(D), end
クライアント ワークスペースの変数について検討すると、spmd ステートメント内でワーカー間に対話型分散される配列は、spmd ステートメント外のクライアントから見れば分散配列となります。spmd 内で対話型に分散されない変数は、spmd 外のクライアントでは Composite となります。
whos Name Size Bytes Class Attributes A 1x4 489 Composite D 4x8 256 distributed
構文と使用方法の詳細については、関数 codistributed のリファレンス ページを参照してください。
小さな配列からの作成
最初に配列全体を 1 つのワークスペースに作成し、それを分割してセグメントに分散する場合、データの格納に必要なメモリの量を減らすうえで関数 codistributed はあまり有用ではありません。メモリを節約するには、まず各ワーカーで小さな配列 (ローカル部分) を作成してから codistributed.build を使用して単一の配列に統合し、ワーカーに分散されるようにします。
この例では、4 つのワーカーのそれぞれに 4 行 250 列のバリアント配列 A を作成し、codistributor を使用してこれらのセグメントを 4 つのワーカーに分散して 16 行 250 列の対話型分散配列を作成します。バリアント配列 A は次のとおりです。
spmd A = [1:250; 251:500; 501:750; 751:1000] + 250 * (spmdIndex - 1); end
WORKER 1 WORKER 2 WORKER 3
1 2 ... 250 | 251 252 ... 500 | 501 502 ... 750 | etc.
251 252 ... 500 | 501 502 ... 750 | 751 752 ...1000 | etc.
501 502 ... 750 | 751 752 ...1000 | 1001 1002 ...1250 | etc.
751 752 ...1000 | 1001 1002 ...1250 | 1251 1252 ...1500 | etc.
| | |次に、これらのセグメントを 1 つの配列に結合し、最初の次元 (行) を用いて分散します。これで、配列は 16 行 250 列になり、各ワーカーに 4 行 250 列のセグメントが配置されます。
spmd D = codistributed.build(A, codistributor1d(1,[4 4 4 4],[16 250])) end
Worker 1:
This worker stores D(1:4,:).
LocalPart: [4x250 double]
Codistributor: [1x1 codistributor1d]
whos
Name Size Bytes Class Attributes
A 1x4 489 Composite
D 16x250 32000 distributed セグメントがすべて同一である対話型分散配列を最初に作成する場合も、複製された配列を同じ方法で使用できます。構文と使用方法の詳細については、関数 codistributed のリファレンス ページを参照してください。
MATLAB コンストラクター関数の使用
MATLAB には、特定の値、サイズ、クラスの対話型分散配列の作成に使用できる配列コンストラクター関数がいくつか用意されています。これらの関数は、対応する MATLAB 言語の非分散用関数と同様に動作しますが、異なる点は、指定された対話型分散オブジェクト codist を使用して結果の配列をワーカーに分散することです。
コンストラクター関数. 対話型分散コンストラクター関数を以下にリストします。codist 引数 (codistributor 関数 codist=codistributor() によって作成) を使用して、配列のどの次元で配列を分散するかを指定します。構文と使用方法の詳細については、これらの関数の個々のリファレンス ページを参照してください。
eye(___,codist)false(___,codist)Inf(___,codist)NaN(___,codist)ones(___,codist)rand(___,codist)randi(___,codist)randn(___,codist)true(___,codist)zeros(___,codist)codistributed.cell(m,n,...,codist)codistributed.colon(a,d,b) codistributed.linspace(m,n,...,codist) codistributed.logspace(m,n,...,codist)sparse(m,n,codist)codistributed.speye(m,...,codist)codistributed.sprand(m,n,density,codist)codistributed.sprandn(m,n,density,codist)
ローカル配列
各ワーカーに配置された対話型分散配列の部分は、より大きな配列の一部です。各ワーカーは共通の配列における自身のセグメントを操作するか、またはそのセグメントを自身のバリアント配列またはプライベート配列にコピーすることができます。この対話型分散配列セグメントのローカル コピーは "ローカル配列" と呼ばれます。
対話型分散配列からのローカル配列の作成
関数 getLocalPart は対話型分散配列のセグメントを独立したバリアント配列にコピーします。次の例では、対話型分散配列 D の各セグメントのローカル コピー L を作成しています。L のサイズから、各ワーカー用の D のローカル部分のみが含まれていることが分かります。配列を 4 つのワーカーに分散するとします。
spmd(4) A = [1:80; 81:160; 161:240]; D = codistributed(A); size(D) L = getLocalPart(D); size(L) end
これは各ワーカーで以下の値を返します。
3 80 3 20
各ワーカーで、対話型分散配列 D は 3 行 80 列であることが認識されます。しかし、D の 80 列が 4 つのワーカーに分散されるため、ローカル部分 L のサイズは 3 行 20 列であることに注意してください。
ローカル配列からの対話型分散配列の作成
関数 codistributed.build を使用して逆操作を行います。小さな配列からの作成で説明したこの関数は、ローカルのバリアント配列を、特定次元に沿って分散される単一の配列に結合します。
先の例を引き続き使用して、ローカルのバリアント配列 L を用い、これをセグメントとしてまとめて新しい対話型分散配列 X を作成します。
spmd codist = codistributor1d(2,[20 20 20 20],[3 80]); X = codistributed.build(L,codist); size(X) end
これは各ワーカーで以下の値を返します。
3 80
配列に関する情報の取得
MATLAB には、任意の特定配列に関する情報を提供する関数がいくつか用意されています。これらの標準関数に加えて、対話型分散配列のみに役立つ 2 つの関数もあります。
配列が対話型分散されるかどうかの判別
関数 iscodistributed は、入力配列が対話型分散されている場合は logical 値 1 (true) を、そうでない場合は logical 値 0 (false) を返します。その構文は次のとおりです。
spmd, TF = iscodistributed(D), end
ここで、D は任意の MATLAB 配列です。
分散の次元の決定
対話型分散オブジェクトは、配列の分割方法とその分散の次元を決定します。配列の対話型分散にアクセスするには、関数 getCodistributor を使用します。これは 2 つのプロパティ、Dimension と Partition を返します。
spmd, getCodistributor(X), end
Dimension: 2
Partition: [20 20 20 20]
Dimension 値 2 は配列 X が列 (次元 2) 単位で分散されることを意味し、Partition 値 [20 20 20 20] は 20 列が 4 つのワーカーにそれぞれ配置されることを意味しています。
これらのプロパティをプログラムによって取得するには、getCodistributor の出力を変数に返し、ドット表記を使用して各プロパティにアクセスします。
spmd C = getCodistributor(X); part = C.Partition dim = C.Dimension end
その他の配列関数
標準配列に関する情報を提供するその他の関数は、対話型分散配列でも機能し、同じ構文が使用されます。
分散の次元の変更
配列を作成する場合、配列の部分を配列のいずれかの次元に沿って分散します。既存の配列においてこの分散の方向を変更するには、異なる対話型分散オブジェクトで関数 redistribute を使用します。
4 つのワーカーに列単位で分散される、乱数値からなる 8 行 16 列の対話型分散配列 D を作成します。
spmd D = rand(8,16,codistributor()); size(getLocalPart(D)) end
これは各ワーカーで以下の値を返します。
8 4
列単位で分散された既存の対話型分散配列から、行単位で分散される新しい対話型分散配列を作成します。
spmd X = redistribute(D, codistributor1d(1)); size(getLocalPart(X)) end
これは各ワーカーで以下の値を返します。
2 16
配列全体の復元
関数 gather を使用して、対話型分散配列をその分散前の形式に復元できます。gather は各ワーカーに所在する配列のセグメントを用い、それらを結合して、すべてのワーカー上で複製された配列にするか、または 1 つのワーカー上で単一の配列にします。
4 行 10 列の配列を 2 番目の次元に沿って 4 つのワーカーに分散します。
spmd, A = [11:20; 21:30; 31:40; 41:50], end
A =
11 12 13 14 15 16 17 18 19 20
21 22 23 24 25 26 27 28 29 30
31 32 33 34 35 36 37 38 39 40
41 42 43 44 45 46 47 48 49 50
spmd, D = codistributed(A), end
WORKER 1 WORKER 2 WORKER 3 WORKER 4
11 12 13 | 14 15 16 | 17 18 | 19 20
21 22 23 | 24 25 26 | 27 28 | 29 30
31 32 33 | 34 35 36 | 37 38 | 39 40
41 42 43 | 44 45 46 | 47 48 | 49 50
| | |
spmd, size(getLocalPart(D)), end
Worker 1:
4 3
Worker 2:
4 3
Worker 3:
4 2
Worker 4:
4 2セグメントを収集して、セグメントの分散されていない完全な配列形式に復元します。
spmd, X = gather(D), end
X =
11 12 13 14 15 16 17 18 19 20
21 22 23 24 25 26 27 28 29 30
31 32 33 34 35 36 37 38 39 40
41 42 43 44 45 46 47 48 49 50
spmd, size(X), end
4 10対話型分散配列のインデックス付け
非分散配列のインデックス付けはかなり簡単ですが、対話型分散配列には追加の考慮が必要となります。非分散配列の各次元には、1 から最終の添字 (MATLAB では end キーワードで表現) までの範囲内でインデックスが付けられます。任意の次元の長さは関数 size または length を使用して簡単に確認できます。
対話型分散配列の場合、これらの値はそう簡単には取得できません。たとえば、配列の 2 番目のセグメント (ワーカー 2 のワークスペースに所在) には、配列の分散によって左右される開始インデックスが付けられます。既定で 4 つのワーカーに列単位で分散される 200 行 1000 列の配列の場合、ワーカー 2 の開始インデックスは 251 となります。同様に列単位で分散される 1000 行 200 列の配列の場合、同じインデックスは 51 となります。また終了インデックスは、end キーワードの使用では与えられません。この場合、end は配列全体の最後、つまり最終セグメントの最後の添字を参照しているからです。各セグメントの長さも、関数 length や size の使用では与えられません。これらの関数は配列全体の長さしか返さないからです。
MATLAB の colon 演算子と end キーワードは、非分散配列にインデックスを付けるための 2 つの基本ツールです。対話型分散配列用には、codistributed.colon という colon 演算子のバージョンが MATLAB で用意されています。これは colon のようなシンボリック演算子ではなく、実質的に関数です。
メモ
配列を使用して対話型分散配列にインデックスを付ける場合は、複製された配列または対話型分散配列のみをインデックス付けに使用できます。このツールボックスでは、インデックスが複製されたかどうかの確認は行いません。グローバルな通信が必要となるためです。このため、サポートされていないバリアント (spmdIndex など) を使用して対話型分散配列にインデックスを付けると、予期しない結果となることがあります。
例: 対話型分散配列における特定要素の検索
いくつかのワーカーに分散される 100 万の要素からなる行ベクトルがあり、要素番号 225,000 を検索するとします。つまり、この要素がどのワーカーに含まれ、そのワーカーにおけるベクトルのローカル部分のどの位置にあるのかを知りたいとします。関数 globalIndices により、対話型分散配列のローカル インデックスとグローバル インデックスの相関が示されます。
D = rand(1,1e6,"distributed"); %Distributed by columns spmd globalInd = globalIndices(D,2); pos = find(globalInd == 225e3); if ~isempty(pos) fprintf(... 'Element is in position %d on worker %d.\n', pos, spmdIndex); end end
4 つのワーカーのプールでこのコードを実行すると、次の結果が得られます。
Worker 1: Element is in position 225000 on worker 1.
5 つのワーカーのプールでこのコードを実行すると、次の結果が得られます。
Worker 2: Element is in position 25000 on worker 2.
異なるサイズのプールを使用すると、要素は異なるワーカーの異なる位置に見出されますが、要素の検索には同じコードを使用できる点に注目してください。
2 次元での分散
行列を行または列の単一次元で分散する代わりに、'2dbc'、つまり 2 次元ブロックサイクリック分散を使用して、ブロック単位で分散することができます。行列の行全体または列全体を複数個含むセグメントに代わり、対話型分散配列のセグメントは 2 次元の正方ブロックとなります。
たとえば、要素の値が昇順になっている単純な 8 行 8 列の行列について考えます。この配列は、spmd ステートメントまたは通信ジョブで作成できます。
spmd A = reshape(1:64, 8, 8) end
結果は複製された配列になります。
1 9 17 25 33 41 49 57
2 10 18 26 34 42 50 58
3 11 19 27 35 43 51 59
4 12 20 28 36 44 52 60
5 13 21 29 37 45 53 61
6 14 22 30 38 46 54 62
7 15 23 31 39 47 55 63
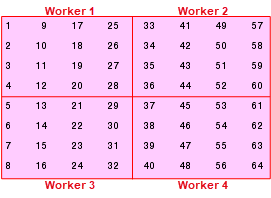
8 16 24 32 40 48 56 64この配列を 4 つのワーカーに分散し、4 行 4 列のブロックを各ワーカーのローカル部分にするとします。この場合、ワーカー グリッドはワーカーの 2 行 2 列の配置となり、ブロック サイズは 1 辺が 4 要素の正方形 (つまり、各ブロックは 4 行 4 列の正方行列) となります。この情報を用いて、対話型分散オブジェクトを定義できます。
spmd DIST = codistributor2dbc([2 2], 4); end
これで、この対話型分散オブジェクトを使用して元の行列を分散できます。
spmd AA = codistributed(A, DIST) end
これにより、配列がこのスキームに従ってワーカーに分散されます。
ワーカー グリッドが対話型分散配列の次元と完全には重ならない場合も、ブロックを順次割り当てる '2dbc' 分散を引き続き使用できます。この場合、元の行列の全要素が含まれるまで、両方の次元でワーカー グリッドを繰り返し重ねる操作が想定されます。
元の同じ 8 行 8 列の行列と 2 行 2 列のワーカー グリッドを使用して、3 行 3 列の正方ブロックがワーカーに分散されるよう、ブロックサイズを 4 でなく 3 にすることを考えてみましょう。コードは次のようになります。
spmd DIST = codistributor2dbc([2 2], 3) AA = codistributed(A, DIST) end
ワーカー グリッドの最初の "行" はワーカー 1 とワーカー 2 に分散されますが、この行には元の行列の 8 列のうち 6 列しか含まれていません。このため、次の 2 列はワーカー 1 に分散されます。この手順は、最初の行内の列がすべて分散されるまで継続されます。次に、以下の分散スキームで示すように、行列の下の行に移って同様の処理を適用します。
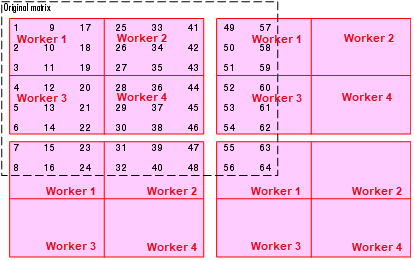
上の図に示すスキームでは、元の行列全体をカバーするためにワーカー グリッドを 4 回重ねる必要があります。次のコードは、各ワーカーで得られたデータの分散を示します。
spmd getLocalPart(AA) end
Worker 1:
ans =
1 9 17 49 57
2 10 18 50 58
3 11 19 51 59
7 15 23 55 63
8 16 24 56 64
Worker 2:
ans =
25 33 41
26 34 42
27 35 43
31 39 47
32 40 48
Worker 3:
ans =
4 12 20 52 60
5 13 21 53 61
6 14 22 54 62
Worker 4:
ans =
28 36 44
29 37 45
30 38 46以下の点に注意してください。
'2dbc'分散では、ブロック サイズが数十を超えないとパフォーマンスの改善が見られない可能性があります。既定のブロック サイズは 64 です。ワーカー グリッドはできるだけ正方形に近くしてください。
'1d'対話型分散配列で機能するよう拡張されたすべての関数が、'2dbc'対話型分散配列でも機能するわけではありません。