spectralMatch
スペクトル ライブラリを使用した未知の領域または物質の識別
構文
説明
Add-On Required: この機能にはが必要です。
score = spectralMatch(libData,reflectance,wavelength)reflectance および wavelength として指定された分光反射率値を ECOSTRESS スペクトル ライブラリ libData で入手できる値と照合し、領域または物質を識別します。
score = spectralMatch(___,Name=Value)
メモ
Hyperspectral Imaging Library for Image Processing Toolbox™ は、MATLAB® Online™ および MATLAB Mobile™ によってサポートされないため、デスクトップの MATLAB が必要です。
例
スペクトル マッチング法では、ハイパースペクトル データ キューブ内にある各ピクセルのスペクトル シグネチャを、ECOSTRESS スペクトル ファイルの植生の基準スペクトル シグネチャと比較します。
ECOSTRESS スペクトル ライブラリから植生のスペクトル シグネチャを読み取ります。
filename = "vegetation.tree.tsuga.canadensis.vswir.tsca-1-47.ucsb.asd.spectrum.txt";
libData = readEcostressSig(filename);ハイパースペクトル データをワークスペースに読み取ります。
hcube = imhypercube("paviaU.hdr");基準スペクトルに対する、ハイパースペクトル データ ピクセルのスペクトルの距離スコアを計算します。
score = spectralMatch(libData,hcube);
距離スコアを表示します。距離スコアの小さいピクセルは基準スペクトルと強く一致するため、植生領域に属している可能性が高くなります。
imagesc(score) colorbar
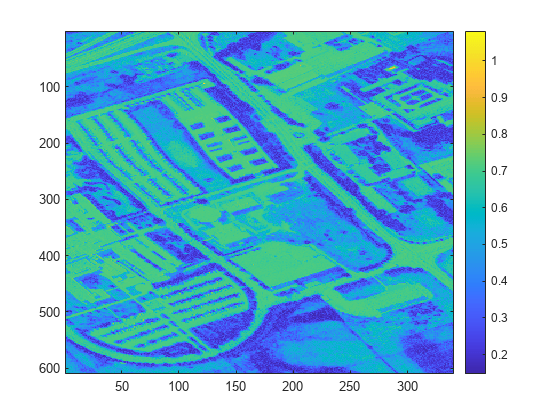
植生領域に対応する距離スコアを検出するためのしきい値を定義します。
threshold = 0.3;
しきい値を適用してバイナリ イメージを作成します。値が 1 のバイナリ イメージ内の領域は、距離スコアがしきい値未満のデータ キューブ内の植生領域に対応します。その他のすべてのピクセルは値が 0 になります。
bw = score < threshold;
バイナリ イメージ内の最大強度の領域のインデックスを使用して、ハイパースペクトル データ キューブの植生領域をセグメント化します。
datacube = gather(hcube); T = reshape(datacube,[size(datacube,1)*size(datacube,2) size(datacube,3)]); Ts = zeros(size(T)); Ts(bw == 1,:) = T( bw==1 ,:); Ts = reshape(Ts,[size(datacube,1) size(datacube,2) size(datacube,3)]);
セグメント化された植生領域のみを含む新しい hypercube オブジェクトを作成します。
segmentedDataCube = imhypercube(Ts,hcube.Wavelength);
colorize 関数を使用して、元のデータ キューブとセグメント化されたデータ キューブの RGB カラー イメージを推定します。
rgbImg = colorize(hcube,Method="rgb",ContrastStretching=true); segmentedImg = colorize(segmentedDataCube,Method="rgb",ContrastStretching=true);
関数 imoverlay を使用して、元のデータ キューブの RGB バージョンにバイナリ イメージを重ね合わせます。
B = imoverlay(rgbImg,bw,"Yellow");元のデータ キューブとセグメント化されたデータ キューブの RGB カラー イメージ、および重ね合わせたイメージを表示します。セグメント化されたイメージには、元のデータ キューブからセグメント化された植生領域のみが含まれています。
figure
montage({rgbImg,segmentedImg,B},Size=[1 3])
title("Original Image | Segmented Image | Overlaid Image")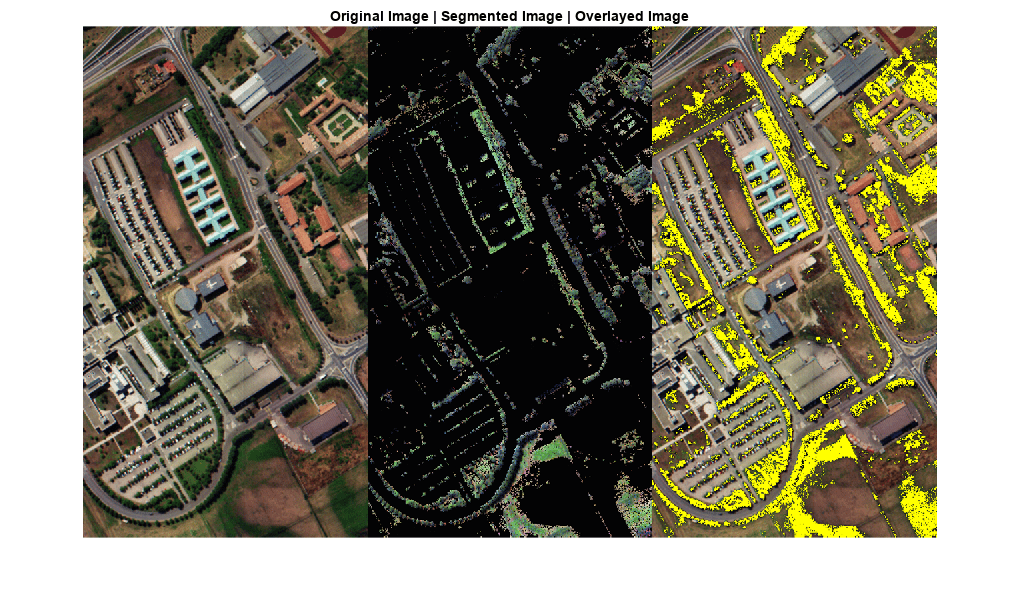
ECOSTRESS スペクトル ライブラリから基準スペクトル シグネチャを読み取ります。このライブラリは、人工物質、土壌、水、植生に属する 15 のスペクトル シグネチャで構成されています。出力は、ECOSTRESS ライブラリ ファイルから読み取ったスペクトル データを格納する構造体配列です。
dirname = fullfile(matlabroot,"toolbox","images","supportpackages","hyperspectral","hyperdata","ECOSTRESSSpectraFiles"); libData = readEcostressSig(dirname);
未知の物質の反射率と波長値を含む .mat ファイルをワークスペースに読み込みます。反射率値と波長値を合わせてテスト スペクトルが構成されます。
load spectralData.mat reflectance wavelength
スペクトル情報発散 (SID) 法を使用して、基準スペクトルとテスト スペクトルの間のスペクトルの一致を計算します。関数は、帯域幅がテスト スペクトルと重なり合う基準スペクトルのみの距離スコアを計算します。その他のスペクトルにはすべて警告メッセージが表示されます。警告メッセージはオフにできます。
warning off score = spectralMatch(libData,reflectance,wavelength,Method="SID");
テスト スペクトルの距離スコアを表示します。距離スコアの小さいピクセルは基準スペクトルと強く一致します。距離スコア値 NaN は、対応する基準スペクトルとテスト スペクトルが、帯域幅の重複部分のしきい値を満たしていないことを示します。
score
score = 1×15
297.8016 122.5567 203.5864 103.3351 288.7747 275.5321 294.2341 NaN NaN 290.4887 NaN 299.5762 171.6919 46.2072 176.6637
最小の距離スコアと対応するインデックスを求めます。返されたインデックス値は、テスト スペクトルに最も厳密に一致する基準スペクトルを含む構造体配列 libData の行を示します。
[value,ind] = min(score);
最小距離スコアのインデックスを使用して一致する基準スペクトルを求め、ECOSTRESS ライブラリ内の一致するスペクトル データの詳細を表示します。結果から、テスト スペクトルが海水のスペクトル シグネチャに最も厳密に一致することが分かります。
matchingSpectra = libData(ind)
matchingSpectra = struct with fields:
Name: "Sea Foam"
Type: "Water"
Class: "Sea Water"
SubClass: "none"
ParticleSize: "Liquid"
Genus: [0×0 string]
Species: [0×0 string]
SampleNo: "seafoam"
Owner: "Dept. of Earth and Planetary Science, John Hopkins University"
WavelengthRange: "TIR"
Origin: "JHU IR Spectroscopy Lab."
CollectionDate: "N/A"
Description: "Sea foam water. Original filename FOAM Original ASTER Spectral Library name was jhu.becknic.water.sea.none.liquid.seafoam.spectrum.txt"
Measurement: "Directional (10 Degree) Hemispherical Reflectance"
FirstColumn: "X"
SecondColumn: "Y"
WavelengthUnit: "micrometer"
DataUnit: "Reflectance (percent)"
FirstXValue: "14.0112"
LastXValue: "2.0795"
NumberOfXValues: "2110"
AdditionalInformation: "none"
Wavelength: [2110×1 double]
Reflectance: [2110×1 double]
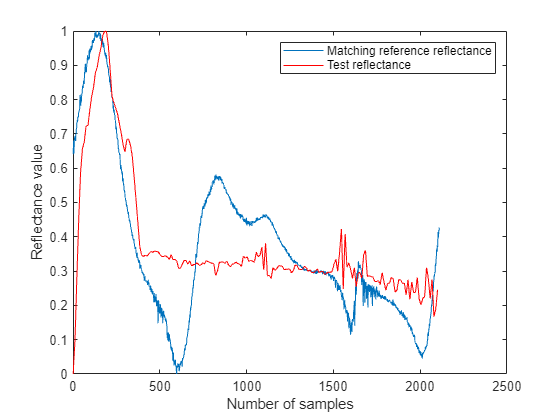
テスト スペクトルの反射率値および対応する基準スペクトルの反射率値をプロットします。反射率曲線の形状をプロットして可視化するため、反射率の値を範囲 [0, 1] に再スケーリングし、基準反射率値の合計に一致するようにテスト反射率値を内挿します。
figure testReflectance = rescale(reflectance,0,1); refReflectance = rescale(matchingSpectra.Reflectance,0,1); testLength = length(testReflectance); newLength = length(testReflectance)/length(refReflectance); testReflectance = interp1(1:testLength,testReflectance,1:newLength:testLength); plot(refReflectance) hold on plot(testReflectance,"r") hold off legend("Matching reference reflectance","Test reflectance") xlabel("Number of samples") ylabel("Reflectance value")
入力引数
名前と値の引数
出力引数
制限
Method を "sam"、"sid"、"jmsam"、または "ns3" として指定した場合、この関数は、パフォーマンスが既に最適化されているため、parfor ループをサポートしません。 (R2023a 以降)
アルゴリズム
バージョン履歴
R2020a で導入