sid
スペクトル情報発散を使用したスペクトルの類似度の評価
説明
Add-On Required: この機能にはが必要です。
score = sid(inputData,refSpectra)inputData 内の各ピクセルのスペクトルと、指定した基準スペクトル refSpectra の間のスペクトルの類似度を評価します。この構文を使用して、ハイパースペクトル データ キューブ内で異なる領域または物質を特定します。
score = sid(testSpectra,refSpectra)testSpectra と基準スペクトル refSpectra の間のスペクトルの類似度を評価します。この構文を使用して、未知の物質のスペクトル シグネチャを基準スペクトルと比較したり、2 つのスペクトル シグネチャ間のスペクトルのばらつきを計算したりします。
メモ
Hyperspectral Imaging Library for Image Processing Toolbox™ は、MATLAB® Online™ および MATLAB Mobile™ によってサポートされないため、デスクトップの MATLAB が必要です。
例
各ピクセル スペクトルとデータ キューブのエンドメンバー スペクトルのスペクトル情報発散 (SID) を計算して、ハイパースペクトル データ キューブ内の異なる領域を識別します。
ハイパースペクトル データをワークスペースに読み取ります。
hcube = imhypercube("jasperRidge2_R198.hdr");データ キューブ内の識別対象のスペクトル的に異なるバンドの数を指定します。
numEndmembers = 7;
N-FINDR アルゴリズムを使用してデータ キューブからエンドメンバーのスペクトル シグネチャを抽出します。
endmembers = nfindr(hcube,numEndmembers);
エンドメンバーのスペクトル シグネチャをプロットします。
figure plot(endmembers) xlabel("Band Number") ylabel("Data Value") legend(Location="Bestoutside")

各エンドメンバーとデータ キューブ内の各ピクセルのスペクトルの間でスペクトル情報発散を計算します。
datacube = gather(hcube); score = zeros(size(datacube,1),size(datacube,2),numEndmembers); for i= 1:numEndmembers score(:,:,i) = sid(hcube,endmembers(:,i)); end
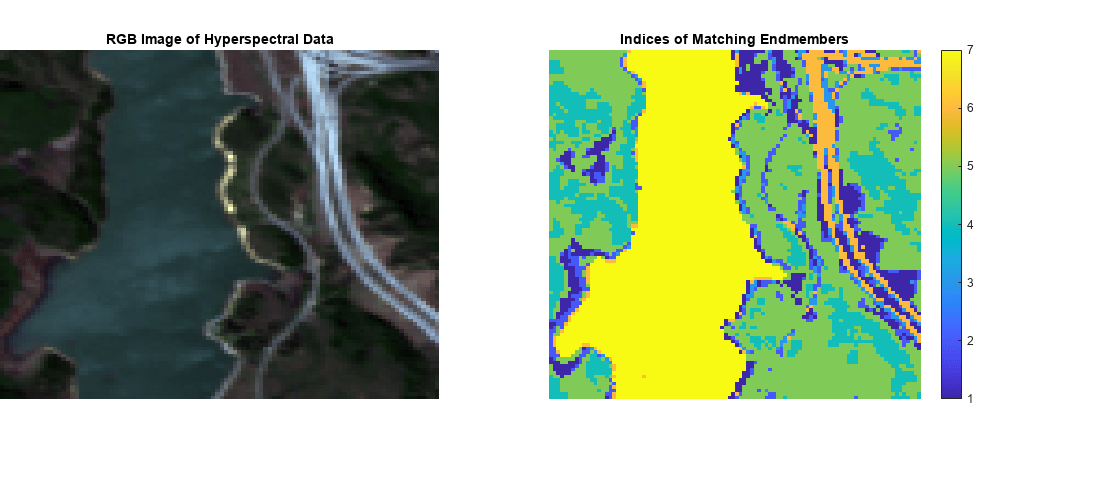
すべてのエンドメンバーについて、ピクセル スペクトルごとに取得した距離スコアから最小スコア値を計算します。それぞれの最小スコアのインデックスは、ピクセル スペクトルが最大の類似度を示すエンドメンバー スペクトルを識別します。スコア行列内の空間位置 (x, y) におけるインデックス値 n は、データ キューブ内の空間位置 (x, y) におけるピクセルのスペクトル シグネチャが、n 番目のエンドメンバーのスペクトル シグネチャに最適に一致することを示しています。
[~,matchingIndx] = min(score,[],3);
関数 colorize を使用してハイパースペクトル データ キューブの RGB イメージを推定します。RGB イメージおよび一致したインデックス値の行列の両方を表示します。
rgbImg = colorize(hcube,Method="rgb"); figure(Position=[0 0 1100 500]) subplot(Position=[0 0.2 0.4 0.7]) imagesc(rgbImg) axis off colormap default title("RGB Image of Hyperspectral Data") subplot(Position=[0.5 0.2 0.4 0.7]) imagesc(matchingIndx); axis off title("Indices of Matching Endmembers") colorbar
ハイパースペクトル データをワークスペースに読み取ります。
hcube = imhypercube("jasperRidge2_R198.hdr");N-FINDR 法を使用して、ハイパースペクトル データ キューブの 10 個の エンドメンバーを求めます。
numEndmembers = 10; endmembers = nfindr(hcube,numEndmembers);
最初のエンドメンバーを基準スペクトル、残りのエンドメンバーをテスト スペクトルと見なします。基準スペクトルと テスト スペクトル間の SID スコアを計算します。
score = zeros(1,numEndmembers-1); refSpectrum = endmembers(:,1); for i = 2:numEndmembers testSpectrum = endmembers(:,i); score(i-1) = sid(testSpectrum,refSpectrum); end
基準スペクトルに対して類似度が最大 (距離が最小) となるテスト スペクトルを求めます。次に、基準スペクトルに対して類似度が最小 (距離が最大) となるテスト スペクトルを求めます。
[minval,minidx] = min(score); maxMatch = endmembers(:,minidx); [maxval,maxidx] = max(score); minMatch = endmembers(:,maxidx);
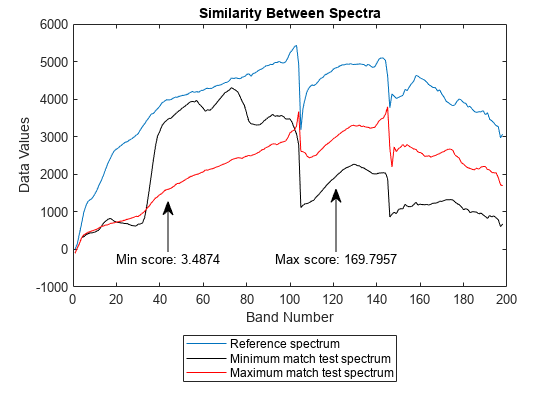
基準スペクトル、類似度が最大のテスト スペクトル、および最小のテスト スペクトルをプロットします。最小スコアを持つテスト スペクトルは、基準エンドメンバーに対する類似度が最大となります。一方、最大スコアをもつテスト スペクトルはスペクトルのばらつきが最も大きく、2 つの異なる物質のスペクトル挙動の特徴を示しています。
figure plot(refSpectrum) hold on plot(maxMatch,"k") plot(minMatch,"r") legend("Reference spectrum","Minimum match test spectrum","Maximum match test spectrum", ... Location="southoutside"); title("Similarity Between Spectra") annotation("textarrow",[0.3 0.3],[0.4 0.52],String="Min score: "+minval) annotation("textarrow",[0.6 0.6],[0.4 0.55],String="Max score: "+maxval) xlabel("Band Number") ylabel("Data Values")
入力引数
出力引数
制限
この関数は、パフォーマンスが既に最適化されているため、parfor ループをサポートしません。 (R2023a 以降)
アルゴリズム
sid 関数は、基準スペクトル refSpectra とテスト スペクトル testSpectra に対して範囲の正規化を実行し、次の式を使用して SID 値を計算します。
q および p は、それぞれ正規化された基準スペクトルとテスト スペクトルのベクトルです。qi および pi は、それぞれベクトル q および p の i 番目の要素です。C は、ベクトル q および p の長さです。
参照
[1] Chein-I Chang. “An Information-Theoretic Approach to Spectral Variability, Similarity, and Discrimination for Hyperspectral Image Analysis.” IEEE Transactions on Information Theory 46, no. 5 (August 2000): 1927–32. https://doi.org/10.1109/18.857802.
バージョン履歴
R2020a で導入
参考
spectralMatch | readEcostressSig | sam | hypercube | sidsam