pcdownsample
3 次元点群のダウンサンプリング
構文
説明
ptCloudOut = pcdownsample(ptCloudIn,"random",percentage)percentage 入力は、出力に返される入力の一部を指定します。
ptCloudOut = pcdownsample(ptCloudIn,"gridAverage",gridStep)gridStep 入力では、3 次元ボックスのサイズを指定します。
ptCloudOut = pcdownsample(ptCloudIn,"gridNearest",gridStep)gridStep 入力では、3 次元ボックスのサイズを指定します。
ptCloudOut = pcdownsample(ptCloudIn,"nonuniformGridSample",maxNumPoints)maxNumPoints を 6 以上に設定しなければなりません。
[ は、ダウンサンプリングされた点群に含まれる点の線形インデックスを返します。この構文は、ptCloudOut,indices] = pcdownsample(___)"random"、"gridNearest"、または "nonuniformGridSample" のダウンサンプリング法を使用する場合にのみ適用されます。
___ = pcdownsample(___, は、前の構文にある引数の任意の組み合わせに加えて、名前と値の引数を 1 つ以上使用してオプションを指定します。たとえば、Name=Value)pcdownsample(PtCloud,"random",percentage,PreserveStructure=true) は、点群のオーガナイズド構造を保持します。
例
点群を読み取ります。
ptCloud = pcread("teapot.ply");3 次元の解像度を (0.1 x 0.1 x 0.1) に設定します。
gridStep = 0.1;
ptCloudA = pcdownsample(ptCloud,'gridAverage',gridStep);ダウンサンプリング後のデータを可視化します。
figure pcshow(ptCloudA);
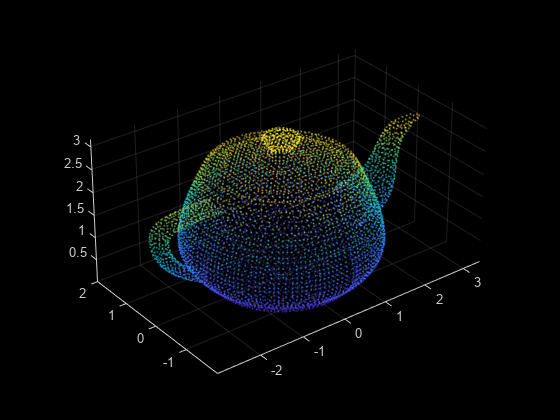
点群を、固定ステップ サイズを使用してダウンサンプリングしたデータと比較します。
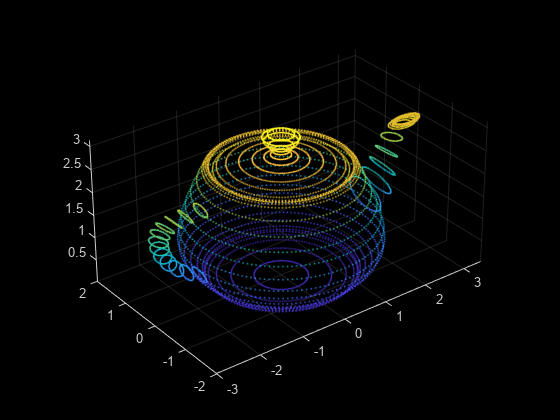
stepSize = floor(ptCloud.Count/ptCloudA.Count); indices = 1:stepSize:ptCloud.Count; ptCloudB = select(ptCloud,indices);
ダウンサンプリングされた点群を可視化します。
figure pcshow(ptCloudB);
同じ座標を共有しているすべての点を含む点群を作成します。
ptCloud = pointCloud(ones(100,3));
3 次元の分解能を小さい値に設定します。
gridStep = 0.01;
出力には 1 つの一意の点のみ含まれます。
ptCloudOut = pcdownsample(ptCloud,'gridAverage',gridStep)ptCloudOut =
pointCloud with properties:
Location: [1 1 1]
Count: 1
XLimits: [1 1]
YLimits: [1 1]
ZLimits: [1 1]
Color: [0×3 uint8]
Normal: [0×3 double]
Intensity: [0×1 double]
保存された MAT ファイルからオーガナイズド点群を読み込みます。
ld = load('drivingLidarPoints.mat');
orgPtCloud = ld.ptCloud;点群をダウンサンプリングします。出力点群はオーガナイズド構造を保持します。その位置プロパティのサイズは M×N×3 です。
gridStep = 2;
orgPtCloudOut = pcdownsample(orgPtCloud,'gridNearest',gridStep,PreserveStructure=true)orgPtCloudOut =
pointCloud with properties:
Location: [32×1083×3 double]
Count: 34656
XLimits: [-86.7523 90.5514]
YLimits: [-85.8353 70.7870]
ZLimits: [-8.2440 13.9009]
Color: []
Normal: []
Intensity: [32×1083 double]
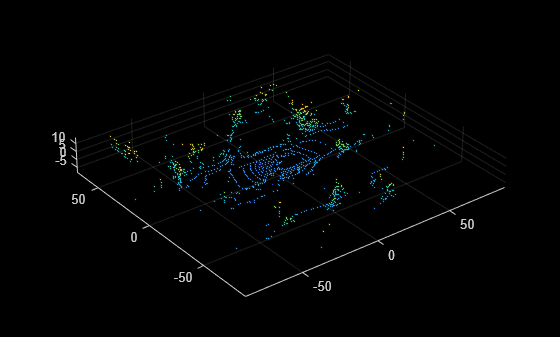
ダウンサンプリングされた点群を可視化します。
figure pcshow(orgPtCloudOut)
入力引数
名前と値の引数
出力引数
参照
[1] Pomerleau, F., F. Colas, R. Siegwart, and S. Magnenat. “Comparing ICP variants on real-world data sets.” Autonomous Robots. Vol. 34, Issue 3, April 2013, pp. 133–148.
拡張機能
バージョン履歴
R2015a で導入参考
関数
pcdenoise|pcplayer|pcshow|pcwrite|pcread|pcfitplane|pcmerge|pctransform|pcregistericp|pcregisterndt