イメージとビデオのグラウンド トゥルースのラベル付け
イメージ ラベラー アプリとビデオ ラベラー アプリを使用して、イメージのコレクション、ビデオ、またはイメージのシーケンスに対話形式でラベルを付け、深層学習用の学習データを作成します。四角形の関心領域 (ROI) またはポリライン、セマンティック セグメンテーション用のピクセル、インスタンス セグメンテーション用の多角形、およびイメージ分類用のシーンにラベルを付けることができます。アプリには、検出アルゴリズムや追跡アルゴリズムと一緒に使用する、グラウンド トゥルース データへのラベル付けを自動化するコンピューター ビジョン アルゴリズムも含まれています。また、グラウンド トゥルース データへのラベル付けを自動化するための独自アルゴリズムのインポートを可能にする API とワークフローも用意されています。
イメージ ラベラー アプリは、複数ユーザーのチームにより共同でラベル付けを行うワークフローのためのインターフェイスも提供します。ラベル付け用のイメージはチーム メンバー間で配布することができます。また、ラベル付きイメージをレビューし、フィードバックを提供し、すべてのラベル付けタスクとレビュー タスクの進行状況を追跡することもできます。

カテゴリ
- イメージとビデオのラベル付け
イメージとビデオのラベル付け
- 自動ラベリング
グラウンド トゥルース ラベル付けのためのオートメーション アルゴリズムの使用
- チームベースのイメージ ラベル付けプロジェクトの作成
イメージ ラベラー アプリを使用した、分散チーム向けの共同作業によるイメージ ラベル付けワークフロー
- グラウンド トゥルース データの使用
深層学習用に学習データを選択し、マージし、読み込む
- グラウンド トゥルース データの用途
ラベル付きおよび学習済みのイメージとビデオのグラウンド トゥルース データの用途
注目の例

Automatically Label Ground Truth Using Segment Anything Model
Produce pixel labels for semantic segmentation using the Segment Anything Model (SAM) in the イメージ ラベラー app. The SAM is an automatic segmentation technique that you can use to segment object regions to label with just a few clicks, or automatically segment the entire image and instantaneously create labels for selected regions. In this example, you interactively label pixels for semantic segmentation in two ways.

カスタム JSON ファイルおよび COCO JSON ファイルへのグラウンド トゥルース オブジェクトのエクスポート
グラウンド トゥルース オブジェクトをカスタム データ形式の JavaScript Object Notation (JSON) ファイルと COCO データ形式の JSON ファイルにエクスポートする。
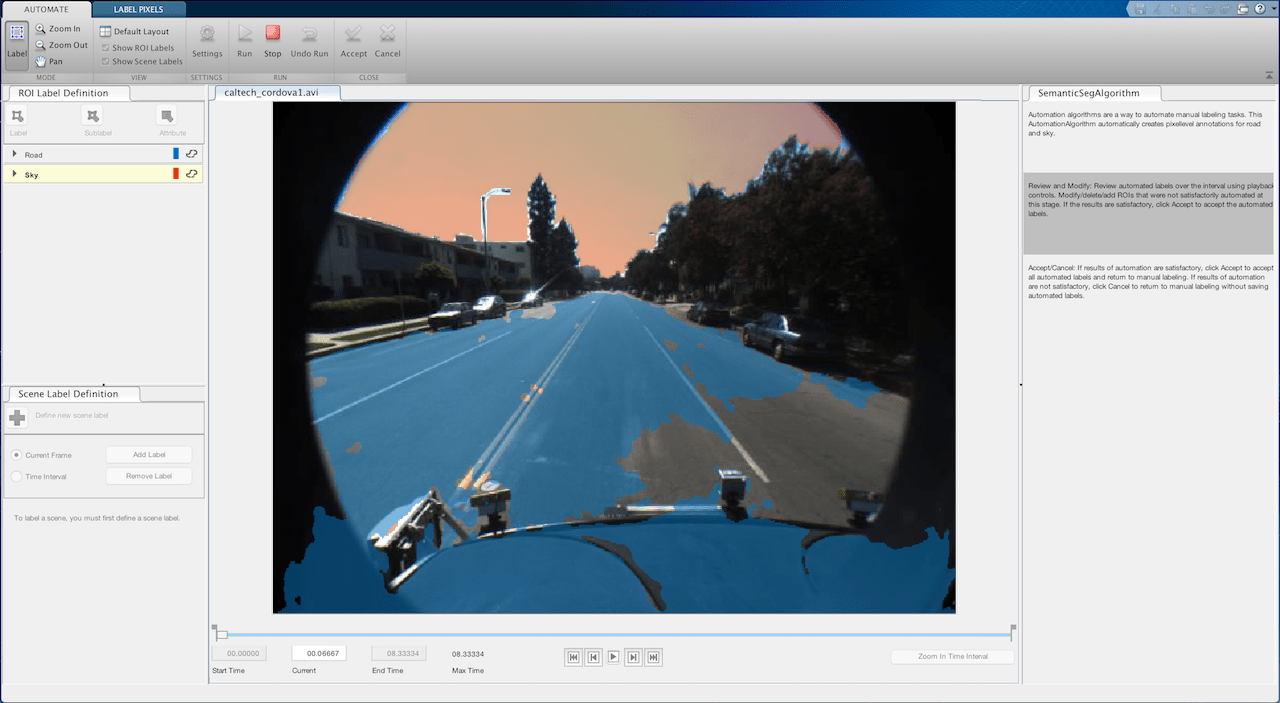
セマンティック セグメンテーションのためのグラウンド トゥルースのラベル付けの自動化
事前学習済みのセマンティック セグメンテーション アルゴリズムを使用して、イメージ内の空と道路をセグメント化する。

Convert Image Labeler Polygons to Labeled Blocked Image for Semantic Segmentation
Convert polygon labels stored in a groundTruth object into a labeled blocked image for semantic segmentation workflows.

Automate Labeling of Objects in Video Using RAFT Optical Flow
Use a pretrained RAFT optical flow estimation network to propagate a predefined object mask from one frame to the next in a video sequence.

Automate Ground Truth Labeling for Object Detection
Create an automation algorithm to automatically label data for object detection using a pretrained object detector.

Automate Ground Truth Labeling for OCR
Automate the labeling of text for OCR training and evaluation.