ノンパラメトリックな経験的確率分布
概要
状況によっては、パラメトリック分布を使用するとデータ標本を正確に記述できない可能性もあります。代わりに、確率密度関数 (pdf) または累積分布関数 (cdf) をデータから推定しなければなりません。Statistics and Machine Learning Toolbox™ には、pdf または cdf を標本データから推定するためのオプションがいくつか用意されています。
カーネル分布
カーネル分布では、特定のパラメーター形式をもつ密度を選択してパラメーターを推定するのではなく、密度の推定自体をデータに合わせるノンパラメトリックな確率密度推定を行います。この分布は、カーネル密度推定量、つまり確率密度関数の生成に使用される曲線の形状を決定する平滑化関数と、生成される密度曲線の平滑さを制御する帯域幅の値によって定義されます。
ヒストグラムと同様、カーネル分布は、標本データを使って、確率分布を表す関数を構築します。ただし、値を離散的なビンに配置するヒストグラムとは異なり、カーネル分布は、各データ値に対して成分平滑化関数を加算して、平滑で連続的な確率曲線を生成します。次の図は、同じ標本データから生成されたヒストグラムとカーネル分布の視覚的な比較を示しています。
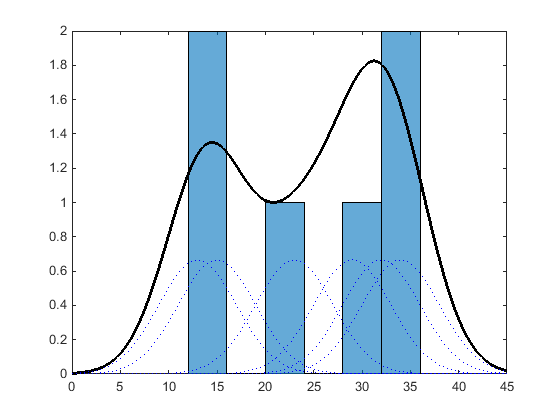
ヒストグラムは、ビンを確立して適切なビンに各データ値を配置することで、確率分布を表します。このビン カウント方式により、ヒストグラムは離散確率密度関数を生成します。これは、特定の用途 (近似分布からの乱数の生成など) に向かない場合があります。
代わりにカーネル分布では、各データ値について個別の確率密度曲線を生成し、滑らかな曲線を加算することで確率密度関数 (pdf) を生成します。この方式は特定のデータ セットに対して、1 つの平滑化された連続確率密度関数を生成します。
カーネル分布についての全般的な情報は、カーネル分布を参照してください。カーネル分布を処理する方法の詳細については、KernelDistribution および ksdensity を参照してください。
経験分布
経験分布では、与えられた観測値のみから確率密度関数 (pdf) と累積密度関数 (cdf) の値を推定します。確率変数の pdf は、標本の観測値の総数に対する変数の頻度の比です。確率変数の経験 cdf (ecdf) は、等しい確率を標本の各観測値に割り当てることによって推定します。cdf は確率変数以下の観測値の割合です。したがって、ecdf は標本データの分布と正確に一致する離散的な累積分布関数になります。
次のプロットは、標準正規分布から生成した 20 個の乱数による ecdf と標準正規分布の理論的な cdf の視覚的な比較を示しています。円は、各標本データ点で計算した ecdf の値を表します。各円を通過する破線は、ecdf を視覚的に表しています。ただし、ecdf は連続関数ではありません。実線は、標本データの乱数を抽出した標準正規分布の理論的な cdf を表しています。
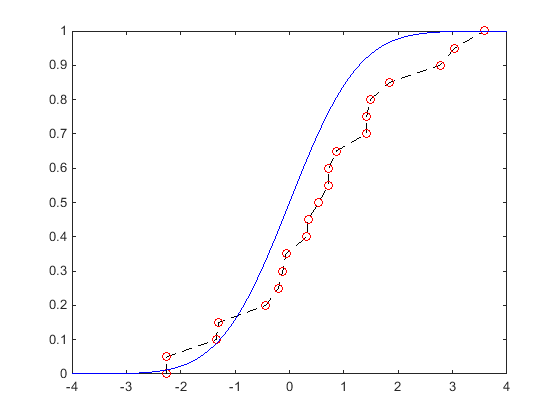
ecdf の形状は理論的な cdf に似ていますが、正確には一致していません。代わりに、ecdf は標本データと正確に一致しています。ecdf は離散的な関数なので、滑らかではありません。特に、データがまばらになる可能性がある両裾の部分で顕著です。関数 paretotails を使用すると、パレート分布の裾で分布を滑らかにすることができます。
詳細とその他の構文オプションについては、ecdf を参照してください。経験分布を処理する方法の詳細については、EmpiricalDistribution を参照してください。
区分的線形分布
区分的線形分布では、個々の点における cdf の値を計算することで標本データ全体の cdf を推定します。次に、連続的な曲線を形成するようにこれらの値を線形に結合します。
次のプロットは、入院患者の体重の測定値による標本に基づく区分的線形分布の cdf を示しています。円は、個々のデータ点 (体重の測定値) を表しています。各データ点を通過する黒の線は、標本データの区分的線形分布の cdf を表しています。

区分的線形分布では、各標本データ点で計算した cdf の値を線形に結合して連続的な曲線を形成します。一方、ecdf を使用して作成される経験累積分布関数は、離散的な cdf を生成します。たとえば、ecdf から生成した乱数の値には、元の標本データに含まれている x 値のみ指定することができます。区分的線形分布から生成した乱数には、標本データの下限と上限の間にある任意の x の値が含まれる可能性があります。
区分的線形分布の cdf は標本データに含まれている値から作成されるので、多くの場合、生成される曲線は滑らかではありません。特に、データがまばらになる可能性がある両裾の部分で顕著です。関数 paretotails を使用すると、パレート分布の裾で分布を滑らかにすることができます。
区分的線形分布を処理する方法の詳細については、PiecewiseLinearDistribution を参照してください。
パレート分布の裾
パレート分布の裾では、区分的なアプローチを使用し、分布の裾を滑らかにすることによりノンパラメトリックな cdf の当てはめを改善します。カーネル分布、経験累積分布関数またはユーザー定義の推定量を中央のデータ値に当てはめてから、一般化パレート分布曲線を裾に当てはめることができます。この手法は、標本データが裾でまばらになっている場合に特に有効です。
次のプロットは、20 個の乱数が含まれているデータ標本の経験累積分布関数 (ecdf) を示しています。実線は ecdf、破線はデータの下位 10% と上位 10% をパレート分布の裾で近似した経験累積分布関数を表しています。円は、データの下位 10% と上位 10% の境界を示しています。

標本データの下位 10% と上位 10% をパレート分布の裾で近似すると、データがまばらな裾の部分で cdf がより滑らかになります。パレート分布の裾の処理についての詳細は、paretotails を参照してください。
三角分布
三角分布では、使用できる標本データが制限されている場合に確率分布を単純化して表現します。この連続分布は、下限、ピーク位置および上限によってパラメーター表現されています。これらの点を線形に結合して、標本データの pdf を推定します。データの平均値、中央値または最頻値をピーク位置として使用できます。
次のプロットは、0 ~ 5 の整数が 10 個ある無作為標本の三角分布 pdf を示しています。下限は標本データの中で最も小さい整数、上限は最も大きい整数です。このプロットのピークは最頻値、つまり標本データで最も頻繁に発生する値にあります。
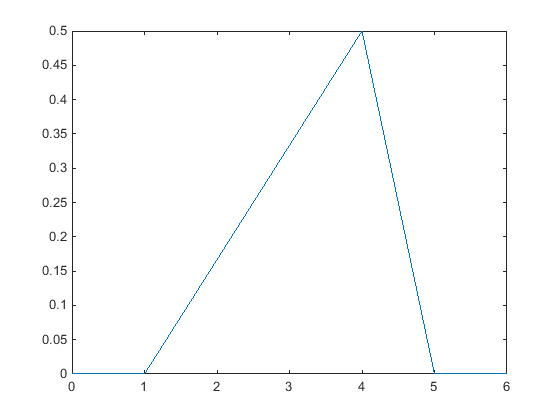
シミュレーションやプロジェクト管理などのビジネス アプリケーションでは、存在する標本データが限られている場合に三角分布を使用してモデルを作成することがあります。詳細は、三角分布を参照してください。
参考
ecdf | ksdensity | paretotails