incrementalClassificationLinear
インクリメンタル学習用のバイナリ分類線形モデル
説明
incrementalClassificationLinear は incrementalClassificationLinear モデル オブジェクトを作成します。これは、インクリメンタル学習用のバイナリ分類線形モデルを表します。サポートされる学習器には、サポート ベクター マシン (SVM) とロジスティック回帰が含まれます。
他の Statistics and Machine Learning Toolbox™ モデル オブジェクトとは異なり、incrementalClassificationLinear は直接呼び出すことができます。また、モデルをデータに当てはめる前に、パフォーマンス メトリクス構成、パラメーター値、および目的ソルバーなどの学習オプションを指定できます。incrementalClassificationLinear オブジェクトを作成すると、インクリメンタル学習用に準備されます。
incrementalClassificationLinear は、インクリメンタル学習に最適です。バイナリ分類用の SVM または線形モデルに学習させるための従来のアプローチ (データへの当てはめによるモデルの作成、交差検証の実行、ハイパーパラメーターの調整など) については、fitcsvm または fitclinear を参照してください。マルチクラスのインクリメンタル学習については、incrementalClassificationECOC および incrementalClassificationNaiveBayes を参照してください。
作成
incrementalClassificationLinear モデル オブジェクトは、次のいくつかの方法で作成できます。
関数の直接呼び出し — インクリメンタル学習オプションを構成するか、
incrementalClassificationLinearを直接呼び出して、線形モデル パラメーターとハイパーパラメーターの初期値を指定します。このアプローチは、データがまだない場合やインクリメンタル学習をすぐに開始したい場合に最適です。従来式の学習済みモデルの変換 — 学習済みモデル オブジェクトのモデル係数およびハイパーパラメーターを使用して、インクリメンタル学習用のバイナリ分類線形モデルを初期化するには、従来式の学習済みモデルを関数
incrementalLearnerに渡してincrementalClassificationLinearモデル オブジェクトに変換できます。この表には、適切なリファレンス ページへのリンクが含まれています。変換可能なモデル オブジェクト 変換関数 ClassificationSVMまたはCompactClassificationSVMincrementalLearnerClassificationLinearincrementalLearnerテンプレート オブジェクトの変換 — テンプレート オブジェクトを関数
incrementalLearnerに渡してincrementalClassificationLinearモデル オブジェクトに変換できます。この表には、適切なリファレンス ページへのリンクが含まれています。変換可能なテンプレート オブジェクト 変換関数 templateSVMincrementalLearnertemplateLinearincrementalLearnerインクリメンタル学習関数の呼び出し —
fit、updateMetrics、およびupdateMetricsAndFitは、構成済みのincrementalClassificationLinearモデル オブジェクトおよびデータを入力として受け入れ、入力モデルとデータから学習した情報で更新されたincrementalClassificationLinearモデル オブジェクトを返します。
説明
Mdl = incrementalClassificationLinear()Mdl を返します。既定のモデルのプロパティには、未知のモデル パラメーター用のプレースホルダーが含まれています。既定のモデルは、パフォーマンスを追跡したり、予測を生成したりする前に学習させなければなりません。
Mdl = incrementalClassificationLinear(Name=Value)incrementalClassificationLinear(Beta=[0.1 0.3],Bias=1,MetricsWarmupPeriod=100) は、線形モデル係数 β のベクトルを [0.1 0.3] に、バイアス β0 を 1 に、およびメトリクスのウォームアップ期間を 100 に設定します。
名前と値の引数
プロパティ
オブジェクト関数
fit | インクリメンタル学習用の線形モデルの学習 |
updateMetricsAndFit | 線形インクリメンタル学習モデルの新しいデータに基づくパフォーマンス メトリクスの更新とモデルの学習 |
updateMetrics | 線形インクリメンタル学習モデルの新しいデータに基づくパフォーマンス メトリクスの更新 |
loss | データのバッチでの線形インクリメンタル学習モデルの損失 |
predict | 線形インクリメンタル学習モデルからの新しい観測の応答予測 |
perObservationLoss | インクリメンタル学習用モデルの観測値ごとの分類誤差 |
reset | インクリメンタル分類モデルのリセット |
例
バイナリ分類用の既定のインクリメンタル線形 SVM モデルを作成します。
Mdl = incrementalClassificationLinear()
Mdl =
incrementalClassificationLinear
IsWarm: 0
Metrics: [1×2 table]
ClassNames: [1×0 double]
ScoreTransform: 'none'
Beta: [0×1 double]
Bias: 0
Learner: 'svm'
Properties, Methods
Mdl は incrementalClassificationLinear モデル オブジェクトです。そのプロパティはすべて読み取り専用です。
Mdl は、他の演算の実行に使用する前に、データに当てはめなければなりません。
人の行動のデータ セットを読み込みます。データをランダムにシャッフルします。
load humanactivity n = numel(actid); rng(1) % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
データ セットの詳細については、コマンド ラインで Description を入力してください。
応答は、次の 5 つのクラスのいずれかになります。座る、立つ、歩く、走る、または踊る。被験者が移動しているかどうか (actid > 2) を基準に、応答を二分します。
Y = Y > 2;
関数 updateMetricsAndFit を使用して、インクリメンタル モデルを学習データに当てはめます。50 個の観測値のチャンクを一度に処理して、データ ストリームをシミュレートします。各反復で次を行います。
50 個の観測値を処理します。
前のインクリメンタル モデルを、入力観測値に当てはめた新しいモデルで上書きします。
、累積メトリクス、およびウィンドウ メトリクスを保存し、インクリメンタル学習中にそれらがどのように進化するかを確認。
% Preallocation numObsPerChunk = 50; nchunk = floor(n/numObsPerChunk); ce = array2table(zeros(nchunk,2),'VariableNames',["Cumulative" "Window"]); beta1 = zeros(nchunk+1,1); % Incremental learning for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = updateMetricsAndFit(Mdl,X(idx,:),Y(idx)); ce{j,:} = Mdl.Metrics{"ClassificationError",:}; beta1(j + 1) = Mdl.Beta(1); end
IncrementalMdl は、ストリーム内のすべてのデータで学習させた incrementalClassificationLinear モデル オブジェクトです。インクリメンタル学習中およびモデルがウォームアップされた後、updateMetricsAndFit は入力観測値でモデルの性能をチェックし、モデルをその観測値に当てはめます。
パフォーマンス メトリクスと が学習中にどのように進化するかを確認するには、それらを別々のタイルにプロットします。
t = tiledlayout(2,1); nexttile plot(beta1) ylabel('\beta_1') xlim([0 nchunk]) nexttile h = plot(ce.Variables); xlim([0 nchunk]) ylabel('Classification Error') xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,'g-.') legend(h,ce.Properties.VariableNames) xlabel(t,'Iteration')
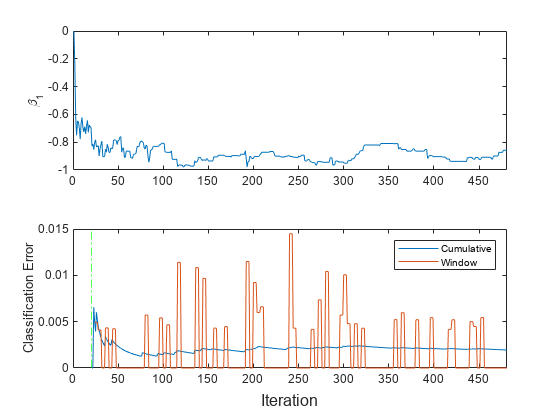
プロットは、updateMetricsAndFit が次を行うことを示しています。
をインクリメンタル学習のすべての反復で当てはめます。
パフォーマンス メトリクスをメトリクスのウォームアップ期間後にのみ計算します。
累積メトリクスを各反復中に計算します。
ウィンドウ メトリクスを 200 個の観測値 (4 回の反復) の処理後に計算します。
メトリクスのウォームアップ期間を指定して、インクリメンタル バイナリ SVM 学習器を準備します。その間、関数 updateMetricsAndFit はモデルの当てはめのみを行います。メトリクス ウィンドウ サイズを観測値 500 個に指定します。SGD を使用してモデルに学習させ、SGD バッチ サイズ、学習率、および正則化パラメーターを調整します。
人の行動のデータ セットを読み込みます。データをランダムにシャッフルします。
load humanactivity n = numel(actid); rng("default") % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
データ セットの詳細については、コマンド ラインで Description を入力してください。
応答は、次の 5 つのクラスのいずれかになります。座る、立つ、歩く、走る、または踊る。被験者が移動しているかどうか (actid > 2) を基準に、応答を二分します。
Y = Y > 2;
バイナリ分類用のインクリメンタル線形モデルを作成します。次のようにモデルを構成します。
インクリメンタル近似関数で生の (標準化されていない) 予測子データを処理するように指定します。
SGD ソルバーを指定します。
リッジ正則化パラメーター値 0.001、SGD バッチ サイズ 20、および学習率 0.002 で、問題に対して十分に機能すると仮定します。
メトリクスのウォームアップ期間を観測値 5000 個に指定します。
メトリクス ウィンドウ サイズを観測値 500 個に指定します。
分類およびヒンジ エラー メトリクスを追跡して、モデルの性能を測定します。
Mdl = incrementalClassificationLinear('Standardize',false, ... 'Solver','sgd','Lambda',0.001,'BatchSize',20,'LearnRate',0.002, ... 'MetricsWarmupPeriod',5000,'MetricsWindowSize',500, ... 'Metrics',{'classiferror' 'hinge'})
Mdl =
incrementalClassificationLinear
IsWarm: 0
Metrics: [2×2 table]
ClassNames: [1×0 double]
ScoreTransform: 'none'
Beta: [0×1 double]
Bias: 0
Learner: 'svm'
Properties, Methods
Mdl はインクリメンタル学習用に構成された incrementalClassificationLinear モデル オブジェクトです。
関数 updateMetricsAndFit を使用して、インクリメンタル モデルを残りのデータに当てはめます。各反復で次を行います。
50 個の観測値のチャンクを処理して、データ ストリームをシミュレートします。チャンクのサイズと SGD バッチ サイズは異なることに注意してください。
前のインクリメンタル モデルを、入力観測値に当てはめた新しいモデルで上書きします。
推定係数 、累積メトリクス、およびウィンドウ メトリクスを保存し、インクリメンタル学習中にそれらがどのように進化するかを確認します。
% Preallocation numObsPerChunk = 50; nchunk = floor(n/numObsPerChunk); ce = array2table(zeros(nchunk,2),'VariableNames',["Cumulative" "Window"]); hinge = array2table(zeros(nchunk,2),'VariableNames',["Cumulative" "Window"]); beta10 = zeros(nchunk+1,1); % Incremental fitting for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = updateMetricsAndFit(Mdl,X(idx,:),Y(idx)); ce{j,:} = Mdl.Metrics{"ClassificationError",:}; hinge{j,:} = Mdl.Metrics{"HingeLoss",:}; beta10(j + 1) = Mdl.Beta(10); end
Mdl は、ストリーム内のすべてのデータで学習させた incrementalClassificationLinear モデル オブジェクトです。インクリメンタル学習中およびモデルがウォームアップされた後、updateMetricsAndFit は入力観測値でモデルの性能をチェックし、モデルをその観測値に当てはめます。
パフォーマンス メトリクスと が学習中にどのように進化するかを確認するには、それらを別々のタイルにプロットします。
tiledlayout(2,2) nexttile plot(beta10) ylabel('\beta_{10}') xlim([0 nchunk]); xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,'g-.') xlabel('Iteration') nexttile h = plot(ce.Variables); xlim([0 nchunk]); ylabel('Classification Error') xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,'g-.') legend(h,ce.Properties.VariableNames) xlabel('Iteration') nexttile h = plot(hinge.Variables); xlim([0 nchunk]); ylabel('Hinge Loss') xline(Mdl.MetricsWarmupPeriod/numObsPerChunk,'g-.') legend(h,hinge.Properties.VariableNames) xlabel('Iteration')
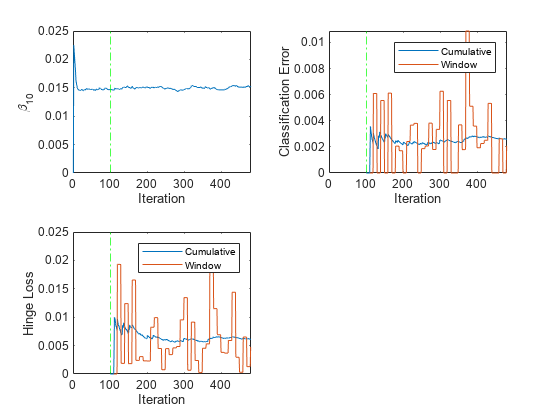
プロットは、updateMetricsAndFit が次を行うことを示しています。
をインクリメンタル学習のすべての反復で当てはめます。
パフォーマンス メトリクスをメトリクスのウォームアップ期間後にのみ計算します。
累積メトリクスを各反復中に計算します。
ウィンドウ メトリクスを 500 個の観測値 (10 回の反復) の処理後に計算します。
fitclinear を使用してバイナリ分類用の線形モデルに学習させ、それをインクリメンタル学習器に変換し、その性能を追跡し、ストリーミング データに当てはめます。学習オプションを従来式からインクリメンタル学習に引き継ぎます。
データの読み込みと前処理
人の行動のデータ セットを読み込みます。データをランダムにシャッフルします。予測子データの観測値を列に配置します。
load humanactivity rng(1); % For reproducibility n = numel(actid); idx = randsample(n,n); X = feat(idx,:)'; Y = actid(idx);
データ セットの詳細については、コマンド ラインで Description を入力してください。
応答は、次の 5 つのクラスのいずれかになります。座る、立つ、歩く、走る、または踊る。被験者が移動しているかどうか (actid > 2) を基準に、応答を二分します。
Y = Y > 2;
被験者がアイドル (Y = false) だったときの収集データが、被験者が移動していたときのデータの倍の品質であると仮定します。アイドルの被験者から収集した観測値に 2 を割り当て、移動している被験者から収集した観測値に 1 を割り当てる重み変数を作成します。
W = ones(n,1) + ~Y;
バイナリ分類用の線形モデルの学習
バイナリ分類用の線形モデルを、データの半分から取った無作為標本に当てはめます。
idxtt = randsample([true false],n,true); TTMdl = fitclinear(X(:,idxtt),Y(idxtt),'ObservationsIn','columns', ... 'Weights',W(idxtt))
TTMdl =
ClassificationLinear
ResponseName: 'Y'
ClassNames: [0 1]
ScoreTransform: 'none'
Beta: [60×1 double]
Bias: -0.1107
Lambda: 8.2967e-05
Learner: 'svm'
Properties, Methods
TTMdl は、バイナリ分類用の従来式の学習済み線形モデルを表す ClassificationLinear モデル オブジェクトです。
学習済みモデルの変換
従来式の学習済み分類モデルを、インクリメンタル学習用のバイナリ分類線形モデルに変換します。
IncrementalMdl = incrementalLearner(TTMdl)
IncrementalMdl =
incrementalClassificationLinear
IsWarm: 1
Metrics: [1×2 table]
ClassNames: [0 1]
ScoreTransform: 'none'
Beta: [60×1 double]
Bias: -0.1107
Learner: 'svm'
Properties, Methods
パフォーマンス メトリクスの追跡とモデルの当てはめの個別の実行
関数 updateMetrics および fit を使用して、残りのデータに対してインクリメンタル学習を実行します。50 個の観測値を一度に処理して、データ ストリームをシミュレートします。各反復で次を行います。
updateMetricsを呼び出し、観測値の入力チャンクを所与として、モデルの分類誤差の累積とウィンドウを更新します。前のインクリメンタル モデルを上書きして、Metricsプロパティ内の損失を更新します。関数がモデルをデータ チャンクに当てはめないことに注意してください。チャンクはモデルに対して "新しい" データです。観測値の向きを列方向に指定し、観測値の重みを指定します。fitを呼び出して、観測値の入力チャンクにモデルを当てはめます。前のインクリメンタル モデルを上書きして、モデル パラメーターを更新します。観測値の向きを列方向に指定し、観測値の重みを指定します。分類誤差と推定された最初の係数 を保存します。
% Preallocation idxil = ~idxtt; nil = sum(idxil); numObsPerChunk = 50; nchunk = floor(nil/numObsPerChunk); ce = array2table(zeros(nchunk,2),'VariableNames',["Cumulative" "Window"]); beta1 = [IncrementalMdl.Beta(1); zeros(nchunk,1)]; Xil = X(:,idxil); Yil = Y(idxil); Wil = W(idxil); % Incremental fitting for j = 1:nchunk ibegin = min(nil,numObsPerChunk*(j-1) + 1); iend = min(nil,numObsPerChunk*j); idx = ibegin:iend; IncrementalMdl = updateMetrics(IncrementalMdl,Xil(:,idx),Yil(idx), ... 'ObservationsIn','columns','Weights',Wil(idx)); ce{j,:} = IncrementalMdl.Metrics{"ClassificationError",:}; IncrementalMdl = fit(IncrementalMdl,Xil(:,idx),Yil(idx), ... 'ObservationsIn','columns','Weights',Wil(idx)); beta1(j + 1) = IncrementalMdl.Beta(end); end
IncrementalMdl は、ストリーム内のすべてのデータで学習させた incrementalClassificationLinear モデル オブジェクトです。
あるいは、updateMetricsAndFit を使用して、新しいデータ チャンクに対するモデルのパフォーマンス メトリクスを更新し、モデルをデータに当てはめることもできます。
パフォーマンス メトリクスと推定された係数 のトレース プロットをプロットします。
t = tiledlayout(2,1); nexttile h = plot(ce.Variables); xlim([0 nchunk]) ylabel('Classification Error') legend(h,ce.Properties.VariableNames) nexttile plot(beta1) ylabel('\beta_1') xlim([0 nchunk]) xlabel(t,'Iteration')
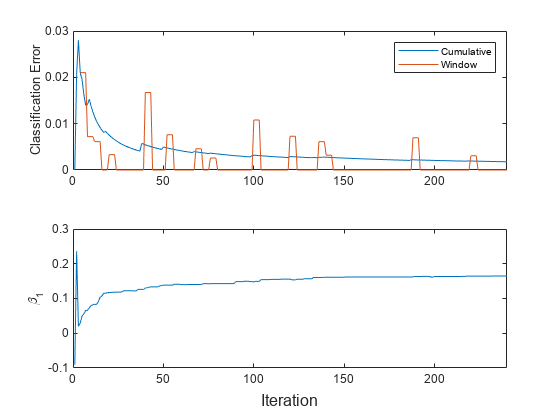
累積の損失は安定しており徐々に減少しますが、ウィンドウの損失には急な変動があります。
はまず急激に変動した後、fit がより多くのチャンクを処理するにつれて徐々に平坦になります。
詳細
ヒント
モデルを作成した後で、データ ストリームについてインクリメンタル学習を実行する C/C++ コードを生成できます。C/C++ コードの生成には MATLAB Coder™ が必要です。詳細については、統計と機械学習の関数のコード生成の紹介を参照してください。
アルゴリズム
参照
拡張機能
バージョン履歴
R2020b で導入