fit
インクリメンタル学習用の線形モデルの学習
説明
関数 fit は、線形回帰 (incrementalRegressionLinear オブジェクト) または線形バイナリ分類 (incrementalClassificationLinear オブジェクト) について、構成されたインクリメンタル学習モデルをストリーミング データに当てはめます。到達したデータを使用して追加的にパフォーマンス メトリクスを追跡するには、代わりに updateMetricsAndFit を使用します。
回帰モデルまたは分類モデルを一度にデータのバッチ全体に当てはめるか交差検証するには、回帰または分類の他の機械学習モデルを参照してください。
例
バイナリ分類用の既定のインクリメンタル線形 SVM モデルを作成します。推定期間を 5000 個の観測値に指定し、SGD ソルバーを指定します。
Mdl = incrementalClassificationLinear('EstimationPeriod',5000,'Solver','sgd')
Mdl =
incrementalClassificationLinear
IsWarm: 0
Metrics: [1×2 table]
ClassNames: [1×0 double]
ScoreTransform: 'none'
Beta: [0×1 double]
Bias: 0
Learner: 'svm'
Properties, Methods
Mdl は incrementalClassificationLinear モデルです。そのプロパティはすべて読み取り専用です。
Mdl は、他の演算の実行に使用する前に、データに当てはめなければなりません。
人の行動のデータ セットを読み込みます。データをランダムにシャッフルします。
load humanactivity n = numel(actid); rng(1) % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
データ セットの詳細については、コマンド ラインで Description を入力してください。
応答は、次の 5 つのクラスのいずれかになります。座る、立つ、歩く、走る、または踊る。被験者が移動しているかどうか (actid > 2) を基準に、応答を二分します。
Y = Y > 2;
関数 fit を使用してインクリメンタル モデルを学習データに当てはめます。50 個の観測値で構成されるチャンクを一度に当てはめます。各反復で次を行います。
50 個の観測値を処理して、データ ストリームのシミュレーションを実行する。
前のインクリメンタル モデルを、入力観測値に当てはめた新しいモデルで上書きします。
、観測値の学習回数、および被験者が移動した (
Y=true) かどうかの事前確率を保存して、インクリメンタル学習中にそれらがどのように進化するかを確認。
% Preallocation numObsPerChunk = 50; nchunk = floor(n/numObsPerChunk); beta1 = zeros(nchunk,1); numtrainobs = zeros(nchunk,1); priormoved = zeros(nchunk,1); % Incremental fitting for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = fit(Mdl,X(idx,:),Y(idx)); beta1(j) = Mdl.Beta(1); numtrainobs(j) = Mdl.NumTrainingObservations; priormoved(j) = Mdl.Prior(Mdl.ClassNames == true); end
Mdl は、ストリーム内のすべてのデータで学習させた incrementalClassificationLinear モデル オブジェクトです。
パラメーターがインクリメンタル学習中にどのように進化するかを確認するには、それらを別々のタイルにプロットします。
tiledlayout(2,2) nexttile plot(beta1) ylabel('\beta_1') xline(Mdl.EstimationPeriod/numObsPerChunk,'r-.') xlabel('Iteration') axis tight nexttile plot(numtrainobs) ylabel('Number of Training Observations') xline(Mdl.EstimationPeriod/numObsPerChunk,'r-.') xlabel('Iteration') axis tight nexttile plot(priormoved) ylabel('\pi(Subject Is Moving)') xline(Mdl.EstimationPeriod/numObsPerChunk,'r-.') xlabel('Iteration') axis tight
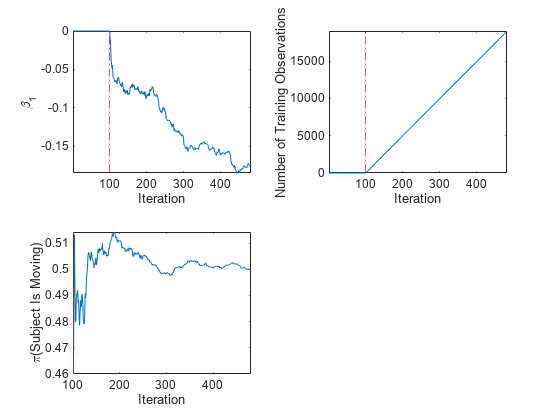
プロットは、推定期間が経過するまでは、fit がモデルをデータに当てはめることも、パラメーターを更新することもないということを示します。
fitclinear を使用してバイナリ分類用の線形モデルに学習させ、それをインクリメンタル学習器に変換し、その性能を追跡し、ストリーミング データに当てはめます。観測値を列に配置し、観測値の重みを指定します。
データの読み込みと前処理
人の行動のデータ セットを読み込みます。データをランダムにシャッフルします。予測子データの観測値を列に配置します。
load humanactivity rng(1); % For reproducibility n = numel(actid); idx = randsample(n,n); X = feat(idx,:)'; Y = actid(idx);
データ セットの詳細については、コマンド ラインで Description を入力してください。
応答は、次の 5 つのクラスのいずれかになります。座る、立つ、歩く、走る、または踊る。被験者が移動しているかどうか (actid > 2) を基準に、応答を二分します。
Y = Y > 2;
被験者が移動していない (Y = false) ときの収集データが、被験者が移動していたときのデータの倍の品質であると仮定します。静止している被験者から収集した観測値に 2 を割り当て、移動している被験者から収集した観測値に 1 を割り当てる重み変数を作成します。
W = ones(n,1) + ~Y;
バイナリ分類用の線形モデルの学習
バイナリ分類用の線形モデルを、データの半分から取った無作為標本に当てはめます。
idxtt = randsample([true false],n,true); TTMdl = fitclinear(X(:,idxtt),Y(idxtt),'ObservationsIn','columns', ... 'Weights',W(idxtt))
TTMdl =
ClassificationLinear
ResponseName: 'Y'
ClassNames: [0 1]
ScoreTransform: 'none'
Beta: [60×1 double]
Bias: -0.1107
Lambda: 8.2967e-05
Learner: 'svm'
Properties, Methods
TTMdl は、バイナリ分類用の従来式の学習済み線形モデルを表す ClassificationLinear モデル オブジェクトです。
学習済みモデルの変換
従来式の学習済み分類モデルを、インクリメンタル学習用のバイナリ分類線形モデルに変換します。
IncrementalMdl = incrementalLearner(TTMdl)
IncrementalMdl =
incrementalClassificationLinear
IsWarm: 1
Metrics: [1×2 table]
ClassNames: [0 1]
ScoreTransform: 'none'
Beta: [60×1 double]
Bias: -0.1107
Learner: 'svm'
Properties, Methods
パフォーマンス メトリクスの追跡とモデルの当てはめの個別の実行
関数 updateMetrics および fit を使用して、残りのデータに対してインクリメンタル学習を実行します。各反復で次を行います。
50 個の観測値を一度に処理して、データ ストリームのシミュレーションを実行します。
updateMetricsを呼び出し、観測値の入力チャンクを所与として、モデルの分類誤差の累積とウィンドウを更新します。前のインクリメンタル モデルを上書きして、Metricsプロパティ内の損失を更新します。関数がモデルをデータ チャンクに当てはめないことに注意してください。チャンクはモデルに対して "新しい" データです。観測値の向きを列方向に指定し、観測値の重みを指定します。fitを呼び出して、観測値の入力チャンクにモデルを当てはめます。前のインクリメンタル モデルを上書きして、モデル パラメーターを更新します。観測値の向きを列方向に指定し、観測値の重みを指定します。分類誤差と推定された最初の係数 を保存します。
% Preallocation idxil = ~idxtt; nil = sum(idxil); numObsPerChunk = 50; nchunk = floor(nil/numObsPerChunk); ce = array2table(zeros(nchunk,2),'VariableNames',["Cumulative" "Window"]); beta1 = [IncrementalMdl.Beta(1); zeros(nchunk,1)]; Xil = X(:,idxil); Yil = Y(idxil); Wil = W(idxil); % Incremental fitting for j = 1:nchunk ibegin = min(nil,numObsPerChunk*(j-1) + 1); iend = min(nil,numObsPerChunk*j); idx = ibegin:iend; IncrementalMdl = updateMetrics(IncrementalMdl,Xil(:,idx),Yil(idx), ... 'ObservationsIn','columns','Weights',Wil(idx)); ce{j,:} = IncrementalMdl.Metrics{"ClassificationError",:}; IncrementalMdl = fit(IncrementalMdl,Xil(:,idx),Yil(idx),'ObservationsIn','columns', ... 'Weights',Wil(idx)); beta1(j + 1) = IncrementalMdl.Beta(1); end
IncrementalMdl は、ストリーム内のすべてのデータで学習させた incrementalClassificationLinear モデル オブジェクトです。
あるいは、updateMetricsAndFit を使用して、新しいデータ チャンクに対するモデルのパフォーマンス メトリクスを更新し、モデルをデータに当てはめることもできます。
パフォーマンス メトリクスと推定された係数 のトレース プロットをプロットします。
t = tiledlayout(2,1); nexttile h = plot(ce.Variables); xlim([0 nchunk]) ylabel('Classification Error') legend(h,ce.Properties.VariableNames) nexttile plot(beta1) ylabel('\beta_1') xlim([0 nchunk]) xlabel(t,'Iteration')
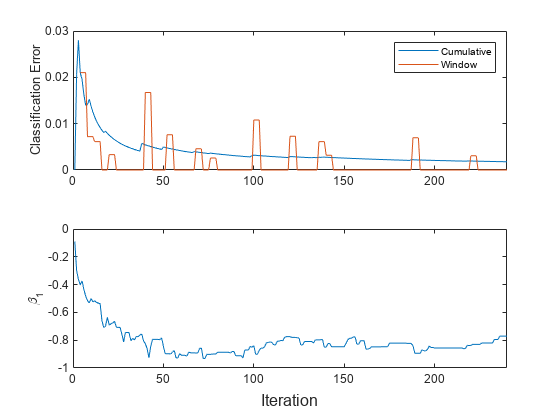
累積の損失は安定しており徐々に減少しますが、ウィンドウの損失には急な変動があります。
は徐々に変化した後、fit がより多くのチャンクを処理するにつれて平坦になります。
線形回帰モデルのパフォーマンスが低下した場合にのみ、そのモデルに対してインクリメンタル学習を行います。
2015 年のニューヨーク市住宅データ セットを読み込み、シャッフルします。このデータの詳細については、NYC Open Data を参照してください。
load NYCHousing2015 rng(1) % For reproducibility n = size(NYCHousing2015,1); shuffidx = randsample(n,n); NYCHousing2015 = NYCHousing2015(shuffidx,:);
table から応答変数 SALEPRICE を抽出します。数値安定性を得るために、SALEPRICE を 1e6 の尺度でスケールします。
Y = NYCHousing2015.SALEPRICE/1e6; NYCHousing2015.SALEPRICE = [];
カテゴリカル予測子からダミー変数メトリクスを作成します。
catvars = ["BOROUGH" "BUILDINGCLASSCATEGORY" "NEIGHBORHOOD"]; dumvarstbl = varfun(@(x)dummyvar(categorical(x)),NYCHousing2015, ... 'InputVariables',catvars); dumvarmat = table2array(dumvarstbl); NYCHousing2015(:,catvars) = [];
table 内の他のすべての数値変数を売価の線形予測子として扱います。ダミー変数の行列を予測子データの残りに連結します。
idxnum = varfun(@isnumeric,NYCHousing2015,'OutputFormat','uniform'); X = [dumvarmat NYCHousing2015{:,idxnum}];
推定期間またはメトリクスのウォームアップ期間がないように、インクリメンタル学習用の線形回帰モデルを構成します。メトリクス ウィンドウ サイズを 1000 に指定します。構成したモデルを最初の 100 個の観測値に当てはめます。
Mdl = incrementalRegressionLinear('EstimationPeriod',0, ... 'MetricsWarmupPeriod',0,'MetricsWindowSize',1000); numObsPerChunk = 100; Mdl = fit(Mdl,X(1:numObsPerChunk,:),Y(1:numObsPerChunk));
Mdl は incrementalRegressionLinear モデル オブジェクトです。
条件付きの当てはめを行い、インクリメンタル学習を実行します。各反復でこの手順に従います。
100 個の観測値のチャンクを一度に処理することで、データ ストリームのシミュレーションを実行します。
サイズが 200 の観測ウィンドウ内で、イプシロン不感応損失を計算することにより、モデル パフォーマンスを更新します。
それまでの最小損失の倍を超える損失が発生した場合にのみ、モデルをデータ チャンクに当てはめます。
パフォーマンスと当てはめを追跡するときは、前のインクリメンタル モデルを上書きします。
イプシロン不感応損失と を保存して、損失と係数が学習中にどのように進化するかを確認します。
fitがモデルに学習させるタイミングを追跡します。
% Preallocation n = numel(Y) - numObsPerChunk; nchunk = floor(n/numObsPerChunk); beta313 = zeros(nchunk,1); ei = array2table(nan(nchunk,2),'VariableNames',["Cumulative" "Window"]); trained = false(nchunk,1); % Incremental fitting for j = 2:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = updateMetrics(Mdl,X(idx,:),Y(idx)); ei{j,:} = Mdl.Metrics{"EpsilonInsensitiveLoss",:}; minei = min(ei{:,2}); pdiffloss = (ei{j,2} - minei)/minei*100; if pdiffloss > 100 Mdl = fit(Mdl,X(idx,:),Y(idx)); trained(j) = true; end beta313(j) = Mdl.Beta(end); end
Mdl は、ストリーム内のすべてのデータで学習させた incrementalRegressionLinear モデル オブジェクトです。
モデルのパフォーマンスと が学習中にどのように進化するかを確認するには、それらを別々のタイルにプロットします。
t = tiledlayout(2,1); nexttile plot(beta313) hold on plot(find(trained),beta313(trained),'r.') xlim([0 nchunk]) ylabel('\beta_{313}') xline(Mdl.EstimationPeriod/numObsPerChunk,'r-.') legend('\beta_{313}','Training occurs','Location','southeast') hold off nexttile plot(ei.Variables) xlim([0 nchunk]) ylabel('Epsilon Insensitive Loss') xline(Mdl.EstimationPeriod/numObsPerChunk,'r-.') legend(ei.Properties.VariableNames) xlabel(t,'Iteration')
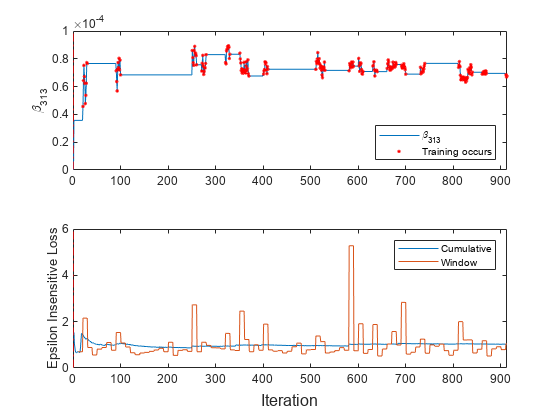
のトレース プロットは、損失がそれまでの最小損失の倍とならない定数値の期間を示します。
入力引数
名前と値の引数
出力引数
ヒント
従来式の学習とは異なり、インクリメンタル学習には個別のテスト (ホールドアウト) セットが存在しない場合もあります。そのため、データの各入力チャンクをテスト セットとして扱うには、インクリメンタル モデルと各入力チャンクを、同じデータでモデルに学習させる前に
updateMetricsに渡します。
アルゴリズム
拡張機能
バージョン履歴
R2020b で導入