predict
線形インクリメンタル学習モデルからの新しい観測の応答予測
構文
説明
例
人の行動のデータ セットを読み込みます。
load humanactivityデータ セットの詳細については、コマンド ラインで Description を入力してください。
応答は、次の 5 つのクラスのいずれかになります。座る、立つ、歩く、走る、または踊る。被験者が移動しているかどうか (actid > 2) を基準に、応答を二分します。
Y = actid > 2;
線形分類モデルをデータ セット全体に当てはめます。
TTMdl = fitclinear(feat,Y)
TTMdl =
ClassificationLinear
ResponseName: 'Y'
ClassNames: [0 1]
ScoreTransform: 'none'
Beta: [60×1 double]
Bias: -0.2005
Lambda: 4.1537e-05
Learner: 'svm'
Properties, Methods
TTMdl は従来式の学習済み線形分類モデルを表す ClassificationLinear モデル オブジェクトです。
従来式の学習済み線形分類モデルを、インクリメンタル学習用のバイナリ分類線形モデルに変換します。
IncrementalMdl = incrementalLearner(TTMdl)
IncrementalMdl =
incrementalClassificationLinear
IsWarm: 1
Metrics: [1×2 table]
ClassNames: [0 1]
ScoreTransform: 'none'
Beta: [60×1 double]
Bias: -0.2005
Learner: 'svm'
Properties, Methods
IncrementalMdl は、SVM を使用するインクリメンタル学習用に準備された incrementalClassificationLinear モデル オブジェクトです。
関数
incrementalLearnerは、学習した係数を、TTMdlが学習データから学習した他の情報と共に渡して、インクリメンタル学習器を初期化します。IncrementalMdlはウォーム (IsWarmが1) です。これは、インクリメンタル学習関数がパフォーマンス メトリクスの追跡を開始できることを意味します。fitclinearが BFGS ソルバーを使用してTTMdlに学習させるのに対し、incrementalLearnerは適応型スケール不変ソルバーを使用してモデルに学習させるように構成します。
従来式の学習済みモデルから変換して作成したインクリメンタル学習器は、追加の処理なしで予測を生成できます。
両方のモデルを使用して、すべての観測値のクラス ラベルを予測します。
ttlabels = predict(TTMdl,feat); illables = predict(IncrementalMdl,feat); sameLabels = sum(ttlabels ~= illables) == 0
sameLabels = logical
1
各観測値についての予測ラベルが両方のモデルで同じになります。
予測子データ行列の列に沿って観測値を配置すると、インクリメンタル学習時の効率が向上する可能性があります。
2015 年のニューヨーク市住宅データ セットを読み込み、シャッフルします。このデータの詳細については、NYC Open Data を参照してください。
load NYCHousing2015 rng(1) % For reproducibility n = size(NYCHousing2015,1); shuffidx = randsample(n,n); NYCHousing2015 = NYCHousing2015(shuffidx,:);
table から応答変数 SALEPRICE を抽出します。対数変換を SALEPRICE に適用します。
Y = log(NYCHousing2015.SALEPRICE + 1); % Add 1 to avoid log of 0
NYCHousing2015.SALEPRICE = [];カテゴリカル予測子からダミー変数メトリクスを作成します。
catvars = ["BOROUGH" "BUILDINGCLASSCATEGORY" "NEIGHBORHOOD"]; dumvarstbl = varfun(@(x)dummyvar(categorical(x)),NYCHousing2015,... 'InputVariables',catvars); dumvarmat = table2array(dumvarstbl); NYCHousing2015(:,catvars) = [];
table 内の他のすべての数値変数を売価の線形予測子として扱います。ダミー変数の行列を残りの予測子データに連結し、データを転置して計算を高速化します。
idxnum = varfun(@isnumeric,NYCHousing2015,'OutputFormat','uniform'); X = [dumvarmat NYCHousing2015{:,idxnum}]';
インクリメンタル学習用の線形回帰モデルを推定期間なしで構成します。
Mdl = incrementalRegressionLinear('Learner','leastsquares','EstimationPeriod',0);
Mdl は incrementalRegressionLinear モデル オブジェクトです。
各反復で次の手順に従って、インクリメンタル学習と予測を実行します。
100 個の観測値のチャンクを一度に処理することで、データ ストリームのシミュレーションを実行します。
モデルをデータの入力チャンクに当てはめます。観測値がデータの列に沿うように指定します。前のインクリメンタル モデルを新しいモデルで上書きします。
当てはめたモデルとデータの入力チャンクを使用して、応答を予測します。観測値がデータの列に沿うように指定します。
% Preallocation numObsPerChunk = 100; n = numel(Y); nchunk = floor(n/numObsPerChunk); r = nan(n,1); figure h = plot(r); h.YDataSource = 'r'; ylabel('Residuals') xlabel('Iteration') % Incremental fitting for j = 2:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = fit(Mdl,X(:,idx),Y(idx),'ObservationsIn','columns'); yhat = predict(Mdl,X(:,idx),'ObservationsIn','columns'); r(idx) = Y(idx) - yhat; refreshdata drawnow end
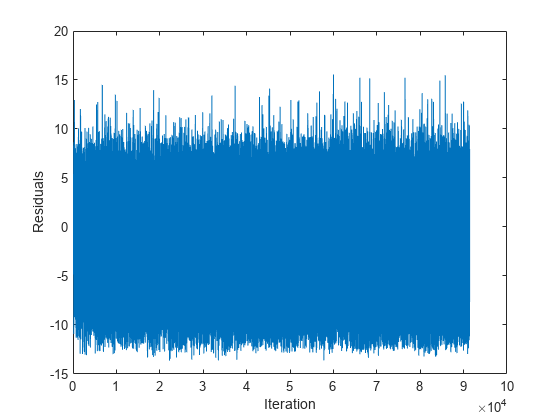
Mdl は、ストリーム内のすべてのデータで学習させた incrementalRegressionLinear モデル オブジェクトです。
残差は、インクリメンタル学習の全体で 0 を中心に対称的に広がっています。
事後クラス確率を計算するには、ロジスティック回帰インクリメンタル学習器を指定します。
人の行動のデータ セットを読み込みます。データをランダムにシャッフルします。
load humanactivity n = numel(actid); rng(10); % For reproducibility idx = randsample(n,n); X = feat(idx,:); Y = actid(idx);
データ セットの詳細については、コマンド ラインで Description を入力してください。
応答は、次の 5 つのクラスのいずれかになります。座る、立つ、歩く、走る、または踊る。被験者が移動しているかどうか (actid > 2) を基準に、応答を二分します。
Y = Y > 2;
バイナリ分類用のインクリメンタル ロジスティック回帰モデルを作成します。クラス名、任意の係数、およびバイアス値を指定して predict の準備をします。
p = size(X,2); Beta = randn(p,1); Bias = randn(1); Mdl = incrementalClassificationLinear('Learner','logistic','Beta',Beta,... 'Bias',Bias,'ClassNames',unique(Y));
Mdl は incrementalClassificationLinear モデルです。そのプロパティはすべて読み取り専用です。任意の値を指定する代わりに、次のいずれかのアクションを実行してモデルを準備できます。
データのサブセット (利用可能な場合) で
fitclinearを使用して、バイナリ分類用のロジスティック回帰モデルに学習させます。次に、incrementalLearnerを使用して、モデルをインクリメンタル学習器に変換します。fitを使用して、Mdlをデータに漸増的に当てはめます。
データ ストリームのシミュレーションを実行し、50 個の観測値の入力チャンクごとに次のアクションを実行します。
predictを呼び出して、データの入力チャンクの観測値における分類スコアを予測します。分類スコアは、ロジスティック回帰学習器の事後クラス確率です。rocmetricsを呼び出して、データの入力チャンクを使って ROC 曲線 (AUC) 内の範囲を計算し、結果を保存します。fitを呼び出して、モデルを入力チャンクに当てはめます。前のインクリメンタル モデルを、入力観測値に当てはめた新しいモデルで上書きします。
numObsPerChunk = 50; nchunk = floor(n/numObsPerChunk); auc = zeros(nchunk,1); % Incremental learning for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; [~,posteriorProb] = predict(Mdl,X(idx,:)); rocObj = rocmetrics(Y(idx),posteriorProb,Mdl.ClassNames); auc(j) = rocObj.AUC(1); Mdl = fit(Mdl,X(idx,:),Y(idx)); end
Mdl は、ストリーム内のすべてのデータで学習させた incrementalClassificationLinear モデル オブジェクトです。
データの入力チャンクに AUC をプロットします。
plot(auc) ylabel('AUC') xlabel('Iteration')
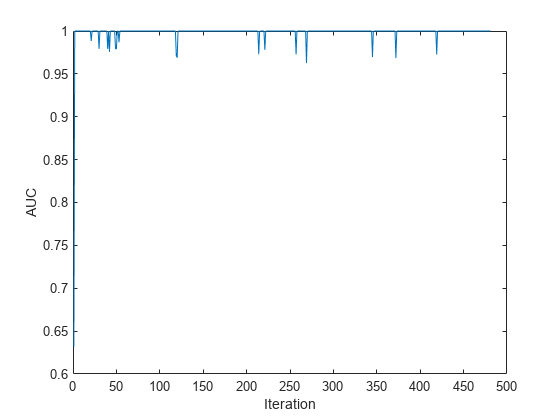
プロットは、分類器がインクリメンタル学習において移動している被験者を正しく予測していることを示しています。
入力引数
出力引数
詳細
拡張機能
バージョン履歴
R2020b で導入