predict
(非推奨) 学習済み深層学習ニューラル ネットワークを使用した応答の予測
predict は推奨されません。代わりに minibatchpredict または関数 predict (dlnetwork) を使用してください。詳細については、バージョン履歴を参照してください。
構文
説明
1 つの CPU または 1 つの GPU で深層学習用の学習済みニューラル ネットワークを使用して予測を実行できます。GPU を使用するには Parallel Computing Toolbox™ ライセンスとサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。名前と値の引数 ExecutionEnvironment を使用して、ハードウェア要件を指定します。
[ は、前述の入力引数を使用して多出力ネットワークの Y1,...,YM] = predict(___)M 出力の応答を予測します。出力 Yj はネットワーク出力 net.OutputNames(j) に対応します。分類出力層のカテゴリカル出力を返すには、ReturnCategorical オプションを 1 (true) に設定します。
___ = predict(___, は、1 つ以上の名前と値の引数で指定された追加オプションを使用して、応答を予測します。Name=Value)
ヒント
関数
predictを使用し、回帰ネットワークを使用して応答を予測したり、多出力ネットワークを使用してデータを分類したりします。単出力の分類ネットワークを使用してデータを分類するには、関数classifyを使用します。長さが異なるシーケンスで予測を行うと、ミニバッチのサイズが、入力データに追加されるパディングの量に影響し、予測値が変わることがあります。さまざまな値を使用して、ネットワークに最適なものを確認してください。ミニバッチのサイズとパディングのオプションを指定するには、
MiniBatchSizeオプションとSequenceLengthオプションをそれぞれ使用します。dlnetworkオブジェクトを使用した応答の予測については、predictを参照してください。
例
学習済みの畳み込みニューラル ネットワークを使用して、数値応答を予測します。
事前学習済みの SqueezeNet ニューラル ネットワークを読み込みます。
net = squeezenet;
イメージ例を読み取って表示します。
I = imread("peppers.png");
figure
imshow(I)
イメージのサイズをネットワークの入力サイズに変更します。
sz = net.Layers(1).InputSize; I = imresize(I,sz(1:2));
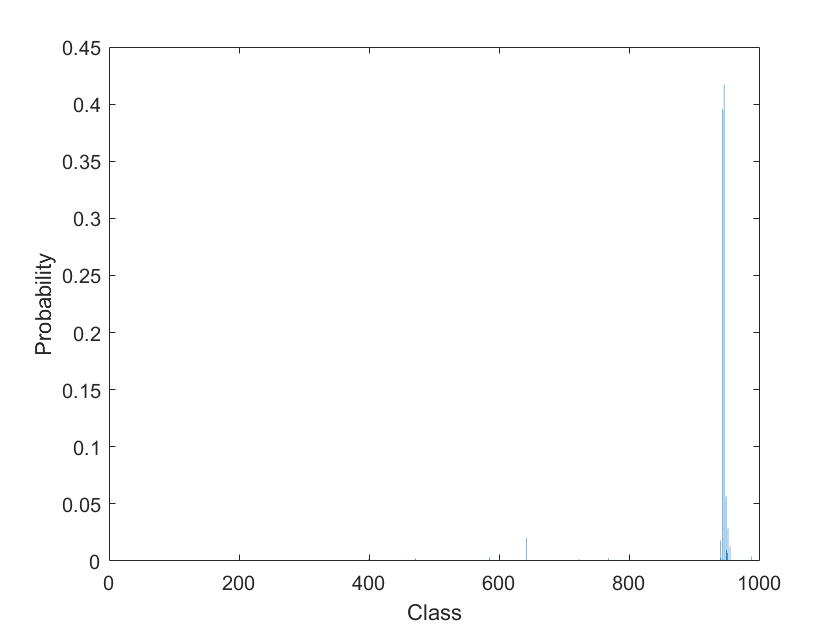
関数 predict を使用して予測を行います。このネットワークは分類ネットワークであるため、関数 predict の出力はクラスの確率になります。回帰ネットワークの場合、この関数は予測された数値応答を出力します。
Y = predict(net,I);
確率を棒グラフで表示します。
figure bar(Y) xlabel("Class") ylabel("Probability")
入力引数
学習済みネットワーク。SeriesNetwork または DAGNetwork オブジェクトとして指定します。事前学習済みのネットワークをインポートする (たとえば、関数 googlenet を使用する)、または trainNetwork を使用して独自のネットワークに学習させることによって、学習済みネットワークを取得できます。
dlnetwork オブジェクトを使用した応答の予測については、predict を参照してください。
イメージ データ。次のいずれかとして指定します。
| データ型 | 説明 | 使用例 | |
|---|---|---|---|
| データストア | ImageDatastore | ディスクに保存されたイメージのデータストア | イメージのサイズがすべて等しい場合に、ディスクに保存されているイメージを使用して予測を行います。 イメージのサイズが異なる場合は |
augmentedImageDatastore | サイズ変更、回転、反転、せん断、平行移動を含む、ランダムなアフィン幾何学的変換を適用するデータストア | イメージのサイズが異なる場合に、ディスクに保存されているイメージを使用して予測を行います。 | |
TransformedDatastore | カスタム変換関数を使用して、基になるデータストアから読み取ったデータのバッチを変換するデータストア |
| |
CombinedDatastore | 2 つ以上の基になるデータストアからデータを読み取るデータストア |
| |
| カスタム ミニバッチ データストア | データのミニバッチを返すカスタム データストア | 他のデータストアでサポートされていない形式のデータを使用して予測を行います。 詳細は、カスタム ミニバッチ データストアの開発を参照してください。 | |
| 数値配列 | 数値配列として指定されたイメージ | メモリに収まり、なおかつサイズ変更などの追加の処理を必要としないデータを使用して予測を行います。 | |
| table | table として指定されたイメージ | table に格納されたデータを使用して予測を行います。 | |
複数の入力をもつネットワークでデータストアを使用する場合、データストアは TransformedDatastore オブジェクトまたは CombinedDatastore オブジェクトでなければなりません。
ヒント
ビデオ データのようなイメージのシーケンスの場合、入力引数 sequences を使用します。
データストア
データストアは、イメージと応答のミニバッチを読み取ります。データストアは、メモリに収まらないデータがある場合や、入力データのサイズを変更したい場合に使用します。
以下のデータストアは、イメージ データ用の predict と直接互換性があります。
カスタム ミニバッチ データストア。詳細は、カスタム ミニバッチ データストアの開発を参照してください。
ヒント
イメージのサイズ変更を含む深層学習用のイメージの前処理を効率的に行うには、augmentedImageDatastore を使用します。ImageDatastore オブジェクトの ReadFcn オプションを使用しないでください。
ImageDatastore を使用すると、事前取得を使用して JPG または PNG イメージ ファイルのバッチ読み取りを行うことができます。ReadFcn オプションをカスタム関数に設定した場合、ImageDatastore は事前取得を行わないため、通常、速度が大幅に低下します。
関数 transform および combine を使用して、予測を行うための他の組み込みデータストアを使用できます。これらの関数は、データストアから読み取られたデータを、classify に必要な形式に変換できます。
データストア出力に必要な形式は、ネットワーク アーキテクチャによって異なります。
| ネットワーク アーキテクチャ | データストア出力 | 出力の例 |
|---|---|---|
| 単一入力 | table または cell 配列。最初の列は予測子を指定します。 table の要素は、スカラー、行ベクトルであるか、数値配列が格納された 1 行 1 列の cell 配列でなければなりません。 カスタム データストアは table を出力しなければなりません。 | data = read(ds) data =
4×1 table
Predictors
__________________
{224×224×3 double}
{224×224×3 double}
{224×224×3 double}
{224×224×3 double}
|
data = read(ds) data =
4×1 cell array
{224×224×3 double}
{224×224×3 double}
{224×224×3 double}
{224×224×3 double} | ||
| 複数入力 | 少なくとも 最初の 入力の順序は、ネットワークの | data = read(ds) data =
4×2 cell array
{224×224×3 double} {128×128×3 double}
{224×224×3 double} {128×128×3 double}
{224×224×3 double} {128×128×3 double}
{224×224×3 double} {128×128×3 double} |
予測子の形式は、データのタイプによって異なります。
| データ | 形式 |
|---|---|
| 2 次元イメージ | h×w×c の数値配列。ここで、h、w、および c は、それぞれイメージの高さ、幅、およびチャネル数です。 |
| 3 次元イメージ | h×w×d×c の数値配列。ここで、h、w、d、および c は、それぞれイメージの高さ、幅、深さ、およびチャネル数です。 |
詳細については、深層学習用のデータストアを参照してください。
数値配列
メモリに収まり、なおかつ拡張などの追加の処理を必要としないデータの場合、イメージのデータ セットを数値配列として指定できます。
数値配列のサイズと形状は、イメージ データのタイプによって異なります。
| データ | 形式 |
|---|---|
| 2 次元イメージ | h×w×c×N の数値配列。ここで、h、w、および c は、それぞれイメージの高さ、幅、およびチャネル数です。N はイメージの数です。 |
| 3 次元イメージ | h×w×d×c×N の数値配列。ここで、h、w、d、および c は、それぞれイメージの高さ、幅、深さ、およびチャネル数です。N はイメージの数です。 |
table
データストアまたは数値配列の代わりに、イメージを table で指定することもできます。
イメージを table で指定した場合、table の各行は観測値に対応します。
イメージ入力の場合、予測子は table の最初の列に格納し、次のいずれかとして指定しなければなりません。
イメージの絶対ファイル パスまたは相対ファイル パス。文字ベクトルとして指定します。
2 次元イメージを表す h×w×c の数値配列が格納された 1 行 1 列の cell 配列。ここで、h、w、および c は、それぞれイメージの高さ、幅、およびチャネル数に対応します。
ヒント
この引数は複素数値の予測子をサポートします。複素数値のデータを SeriesNetwork オブジェクトまたは DAGNetwork オブジェクトに入力するには、入力層の SplitComplexInputs オプションが 1 (true) でなければなりません。
シーケンス データまたは時系列データ。次のいずれかとして指定します。
| データ型 | 説明 | 使用例 | |
|---|---|---|---|
| データストア | TransformedDatastore | カスタム変換関数を使用して、基になるデータストアから読み取ったデータのバッチを変換するデータストア |
|
CombinedDatastore | 2 つ以上の基になるデータストアからデータを読み取るデータストア |
| |
| カスタム ミニバッチ データストア | データのミニバッチを返すカスタム データストア | 他のデータストアでサポートされていない形式のデータを使用して予測を行います。 詳細は、カスタム ミニバッチ データストアの開発を参照してください。 | |
| 数値配列または cell 配列 | 数値配列として指定した、単一のシーケンス。または数値配列の cell 配列として指定した、シーケンスのデータ セット | メモリに収まり、なおかつカスタム変換などの追加の処理を必要としないデータを使用して、予測を行います。 | |
データストア
データストアは、シーケンスと応答のミニバッチを読み取ります。データストアは、データがメモリに収まらない場合や、データに変換を適用したい場合に使用します。
以下のデータストアは、シーケンス データ用の predict と直接互換性があります。
カスタム ミニバッチ データストア。詳細は、カスタム ミニバッチ データストアの開発を参照してください。
関数 transform および combine を使用して、予測を行うための他の組み込みデータストアを使用できます。これらの関数は、データストアから読み取られたデータを、predict に必要な table または cell 配列形式に変換できます。たとえば、ArrayDatastore オブジェクトおよび TabularTextDatastore オブジェクトをそれぞれ使用して、インメモリ配列および CSV ファイルから読み取ったデータの変換と結合を行うことができます。
データストアは、table または cell 配列でデータを返さなければなりません。カスタム ミニバッチ データストアは、table を出力しなければなりません。
| データストア出力 | 出力の例 |
|---|---|
| table | data = read(ds) data =
4×2 table
Predictors
__________________
{12×50 double}
{12×50 double}
{12×50 double}
{12×50 double} |
| cell 配列 | data = read(ds) data =
4×2 cell array
{12×50 double}
{12×50 double}
{12×50 double}
{12×50 double} |
予測子の形式は、データのタイプによって異なります。
| データ | 予測子の形式 |
|---|---|
| ベクトル シーケンス | c 行 s 列の行列。ここで、c はシーケンスの特徴の数、s はシーケンス長です。 |
| 1 次元イメージ シーケンス | h x c x s の配列。ここで、h および c はそれぞれイメージの高さおよびチャネル数に対応します。s はシーケンス長です。 ミニバッチ内の各シーケンスは、同じシーケンス長でなければなりません。 |
| 2 次元イメージ シーケンス | h x w x c x s の配列。ここで、h、w、および c はそれぞれイメージの高さ、幅、およびチャネル数に対応します。s はシーケンス長です。 ミニバッチ内の各シーケンスは、同じシーケンス長でなければなりません。 |
| 3 次元イメージ シーケンス | h x w x d x c x s の配列。ここで、h、w、d、および c は、それぞれイメージの高さ、幅、深さ、およびチャネル数に対応します。s はシーケンス長です。 ミニバッチ内の各シーケンスは、同じシーケンス長でなければなりません。 |
予測子が table で返される場合、数値スカラーまたは数値行ベクトルが要素に含まれているか、数値配列が格納された 1 行 1 列の cell 配列が要素に含まれていなければなりません。
詳細については、深層学習用のデータストアを参照してください。
数値配列または cell 配列
メモリに収まり、なおかつカスタム変換などの追加の処理を必要としないデータの場合、単一のシーケンスを数値配列として指定するか、シーケンスのデータ セットを数値配列の cell 配列として指定することができます。
cell 配列入力の場合、cell 配列は、数値配列から成る N 行 1 列の cell 配列でなければなりません。ここで、N は観測値の数です。シーケンスを表す数値配列のサイズと形状は、シーケンス データのタイプによって異なります。
| 入力 | 説明 |
|---|---|
| ベクトル シーケンス | c 行 s 列の行列。ここで、c はシーケンスの特徴の数、s はシーケンス長です。 |
| 1 次元イメージ シーケンス | h×c×s の配列。ここで、h および c はそれぞれイメージの高さおよびチャネル数に対応します。s はシーケンス長です。 |
| 2 次元イメージ シーケンス | h×w×c×s の配列。ここで、h、w、および c は、それぞれイメージの高さ、幅、およびチャネル数に対応します。s はシーケンス長です。 |
| 3 次元イメージ シーケンス | h×w×d×c×s。ここで、h、w、d、および c は、それぞれ 3 次元イメージの高さ、幅、深さ、およびチャネル数に対応します。s はシーケンス長です。 |
ヒント
この引数は複素数値の予測子をサポートします。複素数値のデータを SeriesNetwork オブジェクトまたは DAGNetwork オブジェクトに入力するには、入力層の SplitComplexInputs オプションが 1 (true) でなければなりません。
特徴データ。次のいずれかとして指定します。
| データ型 | 説明 | 使用例 | |
|---|---|---|---|
| データストア | TransformedDatastore | カスタム変換関数を使用して、基になるデータストアから読み取ったデータのバッチを変換するデータストア |
|
CombinedDatastore | 2 つ以上の基になるデータストアからデータを読み取るデータストア |
| |
| カスタム ミニバッチ データストア | データのミニバッチを返すカスタム データストア | 他のデータストアでサポートされていない形式のデータを使用して予測を行います。 詳細は、カスタム ミニバッチ データストアの開発を参照してください。 | |
| table | table として指定された特徴データ | table に格納されたデータを使用して予測を行います。 | |
| 数値配列 | 数値配列として指定された特徴データ | メモリに収まり、なおかつカスタム変換などの追加の処理を必要としないデータを使用して、予測を行います。 | |
データストア
データストアは、特徴データと応答のミニバッチを読み取ります。データストアは、データがメモリに収まらない場合や、データに変換を適用したい場合に使用します。
以下のデータストアは、特徴データ用の predict と直接互換性があります。
カスタム ミニバッチ データストア。詳細は、カスタム ミニバッチ データストアの開発を参照してください。
関数 transform および combine を使用して、予測を行うための他の組み込みデータストアを使用できます。これらの関数は、データストアから読み取られたデータを、predict に必要な table または cell 配列形式に変換できます。詳細については、深層学習用のデータストアを参照してください。
複数の入力があるネットワークの場合、データストアは TransformedDatastore オブジェクトまたは CombinedDatastore オブジェクトでなければなりません。
データストアは、table または cell 配列でデータを返さなければなりません。カスタム ミニバッチ データストアは、table を出力しなければなりません。データストア出力の形式は、ネットワーク アーキテクチャによって異なります。
| ネットワーク アーキテクチャ | データストア出力 | 出力の例 |
|---|---|---|
| 単入力層 | 少なくとも 1 つの列をもつ table または cell 配列。最初の列は予測子を指定します。 table の要素は、スカラー、行ベクトルであるか、数値配列が格納された 1 行 1 列の cell 配列でなければなりません。 カスタム ミニバッチ データストアは、table を出力しなければなりません。 | 1 つの入力があるネットワークの table: data = read(ds) data =
4×2 table
Predictors
__________________
{24×1 double}
{24×1 double}
{24×1 double}
{24×1 double}
|
1 つの入力があるネットワークの cell 配列:
data = read(ds) data =
4×1 cell array
{24×1 double}
{24×1 double}
{24×1 double}
{24×1 double} | ||
| 多入力層 | 少なくとも 最初の 入力の順序は、ネットワークの | 2 つの入力があるネットワークの cell 配列: data = read(ds) data =
4×3 cell array
{24×1 double} {28×1 double}
{24×1 double} {28×1 double}
{24×1 double} {28×1 double}
{24×1 double} {28×1 double} |
予測子は、c 行 1 列の列ベクトルでなければなりません。ここで、c は特徴の数です。
詳細については、深層学習用のデータストアを参照してください。
table
メモリに収まり、なおかつカスタム変換などの追加の処理を必要としない特徴データの場合、特徴データと応答を table として指定できます。
table の各行は観測値に対応します。table の列での予測子の配置は、タスクのタイプによって異なります。
| タスク | 予測子 |
|---|---|
| 特徴分類 | 1 つ以上の列でスカラーとして指定された特徴。 |
数値配列
メモリに収まり、なおかつカスタム変換などの追加の処理を必要としない特徴データの場合、特徴データを数値配列として指定できます。
数値配列は、N 行 numFeatures 列の数値配列でなければなりません。ここで、N は観測値の数、numFeatures は入力データの特徴の数です。
ヒント
この引数は複素数値の予測子をサポートします。複素数値のデータを SeriesNetwork オブジェクトまたは DAGNetwork オブジェクトに入力するには、入力層の SplitComplexInputs オプションが 1 (true) でなければなりません。
複数の入力をもつネットワークの数値配列または cell 配列。
イメージ、シーケンス、および特徴の予測子入力の場合、予測子の形式は、images、sequences、または features のそれぞれの引数の説明に記載されている形式と一致しなければなりません。
複数の入力をもつネットワークに学習させる方法を説明する例については、イメージ データおよび特徴データにおけるネットワークの学習を参照してください。
複素数値のデータを DAGNetwork オブジェクトまたは SeriesNetwork オブジェクトに入力するには、入力層の SplitComplexInputs オプションが 1 (true) でなければなりません。
データ型: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | cell
複素数のサポート: あり
混在データ。次のいずれかとして指定します。
| データ型 | 説明 | 使用例 |
|---|---|---|
TransformedDatastore | カスタム変換関数を使用して、基になるデータストアから読み取ったデータのバッチを変換するデータストア |
|
CombinedDatastore | 2 つ以上の基になるデータストアからデータを読み取るデータストア |
|
| カスタム ミニバッチ データストア | データのミニバッチを返すカスタム データストア | 他のデータストアでサポートされていない形式のデータを使用して予測を行います。 詳細は、カスタム ミニバッチ データストアの開発を参照してください。 |
関数 transform および combine を使用して、予測を行うための他の組み込みデータストアを使用できます。これらの関数は、データストアから読み取られたデータを、predict に必要な table または cell 配列形式に変換できます。詳細については、深層学習用のデータストアを参照してください。
データストアは、table または cell 配列でデータを返さなければなりません。カスタム ミニバッチ データストアは、table を出力しなければなりません。データストア出力の形式は、ネットワーク アーキテクチャによって異なります。
| データストア出力 | 出力の例 |
|---|---|
入力の順序は、ネットワークの | data = read(ds) data =
4×3 cell array
{24×1 double} {28×1 double}
{24×1 double} {28×1 double}
{24×1 double} {28×1 double}
{24×1 double} {28×1 double} |
イメージ、シーケンス、および特徴の予測子入力の場合、予測子の形式は、images、sequences、または features のそれぞれの引数の説明に記載されている形式と一致しなければなりません。
複数の入力をもつネットワークに学習させる方法を説明する例については、イメージ データおよび特徴データにおけるネットワークの学習を参照してください。
ヒント
数値配列をデータストアに変換するには、arrayDatastore を使用します。
名前と値の引数
オプションの引数のペアを Name1=Value1,...,NameN=ValueN として指定します。ここで、Name は引数名で、Value は対応する値です。名前と値の引数は他の引数の後に指定しなければなりませんが、ペアの順序は重要ではありません。
R2021a より前では、コンマを使用して名前と値をそれぞれ区切り、Name を引用符で囲みます。
例: MiniBatchSize=256 はミニバッチのサイズを 256 に指定します。
予測に使用するミニバッチのサイズ。正の整数として指定します。ミニバッチのサイズが大きくなるとより多くのメモリが必要になりますが、予測時間が短縮される可能性があります。
長さが異なるシーケンスで予測を行うと、ミニバッチのサイズが、入力データに追加されるパディングの量に影響し、予測値が変わることがあります。さまざまな値を使用して、ネットワークに最適なものを確認してください。ミニバッチのサイズとパディングのオプションを指定するには、MiniBatchSize オプションと SequenceLength オプションをそれぞれ使用します。
データ型: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
パフォーマンスの最適化。次のいずれかとして指定します。
"auto"— 入力ネットワークとハードウェア リソースに適した最適化の回数を自動的に適用します。"mex"— MEX 関数をコンパイルして実行します。このオプションは GPU の使用時にのみ利用できます。GPU を使用するには Parallel Computing Toolbox ライセンスとサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。Parallel Computing Toolbox または適切な GPU が利用できない場合、エラーが返されます。"none"— すべての高速化を無効にします。
Acceleration が "auto" の場合、MATLAB® は互換性のある最適化を複数適用し、MEX 関数を生成しません。
"auto" オプションおよび "mex" オプションは、パフォーマンス上のメリットがありますが、初期実行時間が長くなります。互換性のあるパラメーターを使用した後続の呼び出しは、より高速になります。新しい入力データを使用して関数を複数回呼び出す場合は、パフォーマンスの最適化を使用してください。
"mex" オプションは、関数の呼び出しに使用されたネットワークとパラメーターに基づいて MEX 関数を生成し、実行します。複数の MEX 関数を一度に 1 つのネットワークに関連付けることができます。ネットワークの変数をクリアすると、そのネットワークに関連付けられている MEX 関数もクリアされます。
"mex" オプションは、サポートされている層 (GPU Coder)のページにリストされている層 (sequenceInputLayer オブジェクトを除く) を含むネットワークをサポートしています。
"mex" オプションは、単一の GPU の使用時に利用できます。
"mex" オプションを使用するには、C/C++ コンパイラがインストールされ、GPU Coder™ Interface for Deep Learning サポート パッケージがなければなりません。MATLAB でアドオン エクスプローラーを使用してサポート パッケージをインストールします。設定手順については、コンパイラの設定 (GPU Coder)を参照してください。GPU Coder は不要です。
量子化されたネットワークでは、"mex" オプションには、Compute Capability 6.1、6.3、またはそれ以上の CUDA® 対応 NVIDIA® GPU が必要です。
"mex" オプションを使用する場合、MATLAB Compiler™ はネットワークの展開をサポートしません。
ハードウェア リソース。次のいずれかとして指定します。
"auto"— 利用可能な場合は GPU を使用し、そうでない場合は CPU を使用します。"gpu"— GPU を使用します。GPU を使用するには Parallel Computing Toolbox ライセンスとサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。Parallel Computing Toolbox または適切な GPU が利用できない場合、エラーが返されます。"cpu"— CPU を使用します。"multi-gpu"— 既定のクラスター プロファイルに基づいてローカルの並列プールを使用して、1 つのマシンで複数の GPU を使用します。現在の並列プールがない場合、使用可能な GPU の数と等しいプール サイズの並列プールが起動されます。"parallel"— 既定のクラスター プロファイルに基づいてローカルまたはリモートの並列プールを使用します。現在の並列プールがない場合、既定のクラスター プロファイルを使用して 1 つのプールが起動されます。プールから GPU にアクセスできる場合、固有の GPU を持つワーカーのみが計算を実行します。プールに GPU がない場合、代わりに使用可能なすべての CPU ワーカーで計算が実行されます。
さまざまな実行環境をどのような場合に使用するかの詳細は、Scale Up Deep Learning in Parallel, on GPUs, and in the Cloudを参照してください。
"gpu"、"multi-gpu"、および "parallel" のオプションを使用するには、Parallel Computing Toolbox が必要です。深層学習に GPU を使用するには、サポートされている GPU デバイスもなければなりません。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。これらのいずれかのオプションの選択時に Parallel Computing Toolbox または適切な GPU を利用できない場合、エラーが返されます。
ExecutionEnvironment を "multi-gpu" または "parallel" に設定し、再帰層を含むネットワークを使用して並列に予測を行うには、SequenceLength オプションを "shortest" または "longest" に設定しなければなりません。
State パラメーターをもつカスタム層を含むネットワークは、並列の予測をサポートしていません。
カテゴリカル ラベルを返すオプション。0 (false) または 1 (true) として指定します。
ReturnCategorical が 1 (true) の場合、関数は分類出力層のカテゴリカル ラベルを返します。そうでない場合、関数は分類出力層の予測スコアを返します。
シーケンスのパディング、切り捨て、または分割を行うオプション。次のいずれかの値として指定します。
"longest"— 各ミニバッチで、最長のシーケンスと同じ長さになるようにシーケンスのパディングを行います。このオプションを使用するとデータは破棄されませんが、パディングによってニューラル ネットワークにノイズが生じることがあります。"shortest"— 各ミニバッチで、最短のシーケンスと同じ長さになるようにシーケンスの切り捨てを行います。このオプションを使用するとパディングは追加されませんが、データが破棄されます。正の整数 — 各ミニバッチについて、そのミニバッチ内で最も長いシーケンスに合わせてシーケンスをパディングした後、指定した長さのより小さいシーケンスに分割します。分割が発生すると、追加のミニバッチが作成されます。指定したシーケンス長によってデータのシーケンスを均等に分割できない場合、最後のシーケンスを含むミニバッチの長さは指定した長さより短くなります。シーケンス全体がメモリに収まらない場合は、このオプションを使用します。または、
MiniBatchSizeオプションをより小さい値に設定して、ミニバッチごとのシーケンス数を減らしてみます。
シーケンスのパディングと切り捨ての効果の詳細については、シーケンスのパディングと切り捨てを参照してください。
データ型: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | char | string
パディングまたは切り捨ての方向。次のいずれかに指定します。
"right"— シーケンスの右側に対してパディングまたは切り捨てを行います。シーケンスは同じタイム ステップで始まり、シーケンスの末尾に対して切り捨てまたはパディングの追加が行われます。"left"— シーケンスの左側に対してパディングまたは切り捨てを行います。シーケンスが同じタイム ステップで終わるように、シーケンスの先頭に対して切り捨てまたはパディングの追加が行われます。
再帰層は 1 タイム ステップずつシーケンス データを処理するため、再帰層の OutputMode プロパティが "last" の場合、最後のタイム ステップでパディングを行うと層の出力に悪影響を与える可能性があります。シーケンス データの左側に対してパディングまたは切り捨てを行うには、SequencePaddingDirection オプションを "left" に設定します。
sequence-to-sequence ニューラル ネットワークの場合 (各再帰層について OutputMode プロパティが "sequence" である場合)、最初のタイム ステップでパディングを行うと、それ以前のタイム ステップの予測に悪影響を与える可能性があります。シーケンスの右側に対してパディングまたは切り捨てを行うには、SequencePaddingDirection オプションを "right" に設定します。
シーケンスのパディングと切り捨ての効果の詳細については、シーケンスのパディングと切り捨てを参照してください。
入力シーケンスをパディングする値。スカラーとして指定します。
ニューラル ネットワーク全体にエラーが伝播される可能性があるため、NaN でシーケンスをパディングしないでください。
データ型: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
出力引数
予測応答。数値配列、categorical 配列、または cell 配列として返されます。Y の形式は、問題のタイプによって異なります。
次の表は、回帰問題の形式について説明しています。
| タスク | 形式 |
|---|---|
| 2 次元イメージ回帰 |
|
| 3 次元イメージ回帰 |
|
| sequence-to-one 回帰 | N 行 R 列の行列。ここで、N はシーケンスの数、R は応答の数です。 |
| sequence-to-sequence 回帰 | 数値シーケンスの N 行 1 列の cell 配列。ここで、N はシーケンスの数です。シーケンスは R 行の行列で、R は応答の数です。 観測値が 1 つの sequence-to-sequence 回帰タスクでは、 |
| 特徴回帰 | N 行 R 列の行列。N は観測値の数、R は応答の数です。 |
観測値が 1 つの sequence-to-sequence 回帰問題では、sequences を行列にすることができます。この場合、Y は応答の行列です。
ReturnCategorical が 0 (false) で、ネットワークの出力層が分類層である場合、Y は予測された分類スコアになります。次の表は、分類タスクのスコアの形式について説明しています。
| タスク | 形式 |
|---|---|
| イメージ分類 | N 行 K 列の行列。N は観測値の数、K はクラスの数です。 |
| sequence-to-label 分類 | |
| 特徴分類 | |
| sequence-to-sequence 分類 | 行列の N 行 1 列の cell 配列。N は観測値の数です。シーケンスは K 行の行列で、K はクラスの数です。 |
ReturnCategorical が 1 (true) であり、ネットワークの出力層が分類層である場合、Y は categorical ベクトルまたは categorical ベクトルの cell 配列になります。次の表は、分類タスクのラベルの形式について説明しています。
| タスク | 形式 |
|---|---|
| イメージ分類または特徴分類 | ラベルの N 行 1 列の categorical ベクトル。N は観測値の数です。 |
| sequence-to-label 分類 | |
| sequence-to-sequence 分類 | ラベルのカテゴリカル シーケンスの N 行 1 列の cell 配列。N は観測値の数です。 観測値が 1 つの sequence-to-sequence 分類タスクでは、 |
複数の出力をもつネットワークの予測スコアまたは予測応答。数値配列、categorical 配列、または cell 配列として返されます。
各出力 Yj は、ネットワーク出力 net.OutputNames(j) に対応し、出力引数 Y で説明されている形式になります。
アルゴリズム
関数 trainnet または trainNetwork を使用してニューラル ネットワークに学習させる場合や、DAGNetwork オブジェクトおよび SeriesNetwork オブジェクトと共に予測関数または検証関数を使用する場合、ソフトウェアは単精度浮動小数点演算を使用して、これらの計算を実行します。予測および検証のための関数には、predict、classify、および activations があります。CPU と GPU の両方を使用してニューラル ネットワークに学習させる場合、単精度演算が使用されます。
最高のパフォーマンスを提供するために、GPU を使用した MATLAB での深層学習は確定的であることを保証しません。ネットワーク アーキテクチャによっては、GPU を使用して 2 つの同一のネットワークに学習させたり、同じネットワークとデータを使用して 2 つの予測を行ったりする場合に、ある条件下で異なる結果が得られることがあります。
代替方法
単一の分類層のみをもつネットワークでは、関数 classify を使用して、学習済みのネットワークから予測クラスと予測スコアを計算できます。
ネットワーク層から活性化を計算するには、関数 activations を使用します。
LSTM ネットワークなどの再帰型ネットワークでは、classifyAndUpdateState および predictAndUpdateState を使用してネットワークの状態の予測および更新を実行できます。
参照
[1] Kudo, Mineichi, Jun Toyama, and Masaru Shimbo. “Multidimensional Curve Classification Using Passing-through Regions.” Pattern Recognition Letters 20, no. 11–13 (November 1999): 1103–11. https://doi.org/10.1016/S0167-8655(99)00077-X.
[2] UCI Machine Learning Repository: Japanese Vowels Dataset. https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels.
拡張機能
使用上の注意および制限:
C++ コード生成は、以下の構文をサポートします。
Y = predict(net,images)(ここで、imagesは数値配列)Y = predict(net,sequences)(ここで、sequencesは cell 配列)Y = predict(net,features)(ここで、featuresは数値配列)[Y1,...,YM] = predict(__)(前述の構文のいずれかを使用)__ = predict(__,Name=Value)(前述の構文のいずれかを使用)
数値入力の場合、入力のサイズは可変であってはなりません。サイズはコード生成時に固定しなければなりません。
ベクトル シーケンス入力の場合、特徴の数はコード生成時に定数でなければなりません。シーケンスの長さは可変サイズにできます。
イメージ シーケンス入力の場合、高さ、幅、およびチャネル数は、コード生成時に定数でなければなりません。
コード生成では、名前と値のペアの引数
MiniBatchSize、ReturnCategorical、SequenceLength、SequencePaddingDirection、およびSequencePaddingValueのみがサポートされています。すべての名前と値のペアはコンパイル時の定数でなければなりません。コード生成では、名前と値のペア
SequenceLengthのオプションとして"longest"と"shortest"のみがサポートされています。ReturnCategoricalが1(true) であり、GCC C/C++ コンパイラの version 8.2 以降を使用している場合、-Wstringop-overflowの警告が表示されることがあります。Intel® MKL-DNN ターゲット用のコード生成では、
SequenceLength="longest"、SequencePaddingDirection="left"、およびSequencePaddingValue=0の名前と値の引数の組み合わせがサポートされません。
深層学習ニューラル ネットワーク用のコードの生成の詳細は、MATLAB Coder を使用した深層学習コード生成のワークフロー (MATLAB Coder)を参照してください。
使用上の注意および制限:
GPU コード生成は、以下の構文をサポートします。
Y = predict(net,images)(ここで、imagesは数値配列)Y = predict(net,sequences)(ここで、sequencesは cell 配列または数値配列)Y = predict(net,features)(ここで、featuresは数値配列)[Y1,...,YM] = predict(__)(前述の構文のいずれかを使用)__ = predict(__,Name=Value)(前述の構文のいずれかを使用)
数値入力の場合、入力のサイズは可変であってはなりません。サイズはコード生成時に固定しなければなりません。
GPU コード生成では、関数
predictへのgpuArray入力はサポートされません。cuDNN ライブラリはベクトルおよび 2 次元イメージ シーケンスをサポートします。TensorRT ライブラリはベクトル入力シーケンスのみをサポートします。ARM®
Compute Libraryfor GPU は再帰型ネットワークをサポートしていません。ベクトル シーケンス入力の場合、特徴の数はコード生成時に定数でなければなりません。シーケンスの長さは可変サイズにできます。
イメージ シーケンス入力の場合、高さ、幅、およびチャネル数は、コード生成時に定数でなければなりません。
コード生成では、名前と値のペアの引数
MiniBatchSize、ReturnCategorical、SequenceLength、SequencePaddingDirection、およびSequencePaddingValueのみがサポートされています。すべての名前と値のペアはコンパイル時の定数でなければなりません。コード生成では、名前と値のペア
SequenceLengthのオプションとして"longest"と"shortest"のみがサポートされています。関数
predictの GPU コード生成では、半精度浮動小数点データ型として定義されている入力がサポートされます。詳細については、half(GPU Coder) を参照してください。ReturnCategoricalが1(true) に設定され、GCC C/C++ コンパイラの version 8.2 以降を使用している場合、-Wstringop-overflowの警告が表示されることがあります。
計算を並列実行するには、ExecutionEnvironment オプションを "multi-gpu" または "parallel" に設定します。
詳細は、Scale Up Deep Learning in Parallel, on GPUs, and in the Cloudを参照してください。
入力データが以下の場合、
ExecutionEnvironmentオプションは"auto"または"gpu"でなければなりません。gpuArraygpuArrayオブジェクトを含む cell 配列gpuArrayオブジェクトを含む tablegpuArrayオブジェクトを含む cell 配列を出力するデータストアgpuArrayオブジェクトを含む table を出力するデータストア
詳細については、GPU での MATLAB 関数の実行 (Parallel Computing Toolbox)を参照してください。
バージョン履歴
R2016a で導入R2024a 以降、DAGNetwork オブジェクトおよび SeriesNetwork オブジェクトは非推奨となりました。代わりに dlnetwork オブジェクトを使用してください。この推奨により、関数 predict も非推奨となります。代わりに関数 minibatchpredict または関数 predict (dlnetwork) を使用してください。
DAGNetwork オブジェクトおよび SeriesNetwork オブジェクトのサポートを削除する予定はありません。ただし、dlnetwork オブジェクトには次の利点があるため、代わりにこのオブジェクトを使うことを推奨します。
dlnetworkオブジェクトは、ネットワークの構築、予測、組み込み学習、可視化、圧縮、検証、およびカスタム学習ループをサポートする統合されたデータ型です。dlnetworkオブジェクトは、ユーザーが作成したり外部のプラットフォームからインポートしたりできる、さまざまなネットワーク アーキテクチャをサポートしています。関数
trainnetはdlnetworkオブジェクトをサポートしているため、損失関数を簡単に指定できます。組み込みの損失関数を選択するか、カスタム損失関数を指定できます。dlnetworkオブジェクトを使用した学習と予測は、通常、LayerGraphとtrainNetworkを使用したワークフローよりも高速です。
学習済みの DAGNetwork オブジェクトまたは SeriesNetwork オブジェクトを dlnetwork オブジェクトに変換するには、関数 dag2dlnetwork を使用します。
関数 predict の代表的な使用法と、代わりに dlnetwork オブジェクトを使用するためのコードの更新方法を、次の表に示します。
| 非推奨 | 推奨 |
|---|---|
Y = predict(net,X); | Y = minibatchpredict(net,X); |
R2022b 以降、関数 predict、classify、predictAndUpdateState、classifyAndUpdateState、および activations を使用してシーケンス データで予測を行うときに、SequenceLength オプションが整数である場合、各ミニバッチ内で最も長いシーケンスに合わせてシーケンスがパディングされた後、指定したシーケンス長でシーケンスが分割されてミニバッチが作成されます。SequenceLength によってミニバッチのシーケンスを均等に分割できない場合、最後に分割されたミニバッチの長さは SequenceLength より短くなります。この動作によって、パディング値しか含まれないタイム ステップが予測に影響するのを防ぐことができます。
以前のリリースでは、SequenceLength の倍数に最も近く、かつミニバッチ長以上の長さとなるように、シーケンスのミニバッチをパディングしてから、データが分割されていました。この動作を再現するには、ミニバッチの長さが SequenceLength の適切な倍数となるように、入力データを手動でパディングします。sequence-to-sequence のワークフローでは、さらに、パディング値に対応するタイム ステップを出力から手動で削除しなければならない場合があります。
MATLAB Command
You clicked a link that corresponds to this MATLAB command:
Run the command by entering it in the MATLAB Command Window. Web browsers do not support MATLAB commands.
Web サイトの選択
Web サイトを選択すると、翻訳されたコンテンツにアクセスし、地域のイベントやサービスを確認できます。現在の位置情報に基づき、次のサイトの選択を推奨します:
また、以下のリストから Web サイトを選択することもできます。
最適なサイトパフォーマンスの取得方法
中国のサイト (中国語または英語) を選択することで、最適なサイトパフォーマンスが得られます。その他の国の MathWorks のサイトは、お客様の地域からのアクセスが最適化されていません。
南北アメリカ
- América Latina (Español)
- Canada (English)
- United States (English)
ヨーロッパ
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)