classifyAndUpdateState
(非推奨) 学習済み再帰型ニューラル ネットワークを使用したデータの分類とネットワーク状態の更新
classifyAndUpdateState は推奨されません。代わりに、関数 predict を使用し、状態出力を使用してニューラル ネットワークの State プロパティを更新してください。分類スコアをラベルに変換するには、関数 scores2label を使用します。詳細については、バージョン履歴を参照してください。
構文
説明
1 つの CPU または 1 つの GPU で学習済みの深層学習ネットワークを使用して予測を実行できます。GPU を使用するには Parallel Computing Toolbox™ ライセンスとサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。名前と値の引数 ExecutionEnvironment を使用して、ハードウェア要件を指定します。
[ は、学習済み再帰型ニューラル ネットワーク updatedNet,Y] = classifyAndUpdateState(recNet,sequences)recNet を使用して sequences のデータを分類し、ネットワーク状態を更新します。
この関数は、再帰型ニューラル ネットワークのみをサポートします。入力 recNet には、LSTM 層などの再帰層、または状態パラメーターをもつカスタム層が 1 つ以上含まれていなければなりません。
[ は、多入力ネットワーク updatedNet,Y] = classifyAndUpdateState(recNet,X1,...,XN)recNet に対する数値配列または cell 配列 X1, …, XN のデータのクラス ラベルを予測します。入力 Xi は、ネットワーク入力 recNet.InputNames(i) に対応します。
[ は、混合するデータ型のデータから成る多入力ネットワーク updatedNet,Y] = classifyAndUpdateState(recNet,mixed)recNet のクラス ラベルを予測します。
[ は、前述の構文のいずれかを使用して、クラス ラベルに対応する分類スコアも返します。updatedNet,Y,scores] = classifyAndUpdateState(___)
___ = classifyAndUpdateState(___, は、前述の構文のいずれかを使用して、1 つ以上の名前と値の引数によって指定された追加オプションを使用してクラス ラベルを予測します。たとえば、Name=Value)MiniBatchSize=27 は、サイズ 27 のミニバッチを使用してデータを分類します。
ヒント
長さが異なるシーケンスで予測を行うと、ミニバッチのサイズが、入力データに追加されるパディングの量に影響し、予測値が変わることがあります。さまざまな値を使用して、ネットワークに最適なものを確認してください。ミニバッチのサイズとパディングのオプションを指定するには、MiniBatchSize オプションと SequenceLength オプションをそれぞれ使用します。
例
再帰型ニューラル ネットワークを使用して、データを分類し、ネットワークの状態を更新します。
[1] および [2] で説明されているように Japanese Vowels データ セットで学習させた長短期記憶 (LSTM) ネットワーク net があるとします。このネットワークは、ミニバッチのサイズ 27 を使用して、シーケンス長で並べ替えられたシーケンスで学習させたとします。
ネットワーク アーキテクチャを表示します。
net.Layers
ans =
5x1 Layer array with layers:
1 'sequenceinput' Sequence Input Sequence input with 12 dimensions
2 'lstm' LSTM LSTM with 100 hidden units
3 'fc' Fully Connected 9 fully connected layer
4 'softmax' Softmax softmax
5 'classoutput' Classification Output crossentropyex with '1' and 8 other classes
テスト データ セット XTest があるとします。ここで、XTest は可変長シーケンスの cell 配列です。各シーケンスには 12 個の特徴があります。
いずれかのシーケンス内のタイム ステップ全体にわたってループ処理します。各タイム ステップを分類し、ネットワーク状態を更新します。
X = XTest{94};
numTimeSteps = size(X,2);
for i = 1:numTimeSteps
v = X(:,i);
[net,label,score] = classifyAndUpdateState(net,v);
labels(i) = label;
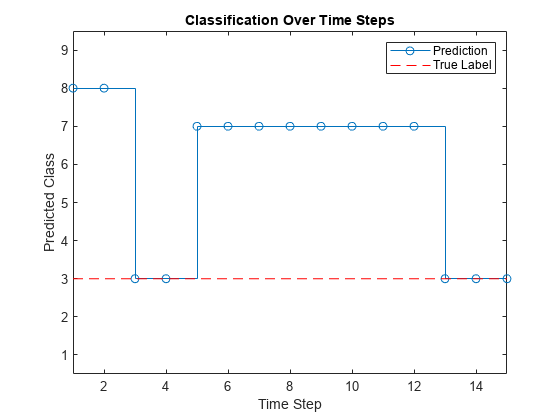
end予測されたラベルを階段状プロットにプロットします。このプロットには、タイムス ステップ間の予測の変化が示されます。
figure stairs(labels,"-o") xlim([1 numTimeSteps]) xlabel("Time Step") ylabel("Predicted Class") title("Classification Over Time Steps")
予測と真のラベルを比較します。
trueLabel = TTest(94)
trueLabel = categorical
3
観測値の真のラベルを示す水平のラインをプロットします。
hold on line([1 numTimeSteps],[trueLabel trueLabel], ... Color="red", ... LineStyle="--") legend(["Prediction" "True Label"])
入力引数
名前と値の引数
出力引数
アルゴリズム
代替方法
複数の出力層を持つ再帰型ニューラル ネットワークを使用してデータを分類し、ネットワーク状態を更新するには、関数 predictAndUpdateState を使用し、ReturnCategorical オプションを 1 (true) に設定します。
予測分類スコアを計算し、再帰型ニューラル ネットワークのネットワーク状態を更新するために、関数 predictAndUpdateState を使用することもできます。
ネットワーク層の活性化を計算するには、関数 activations を使用します。関数 activations は、ネットワークの状態を更新しません。
参照
[1] M. Kudo, J. Toyama, and M. Shimbo. "Multidimensional Curve Classification Using Passing-Through Regions." Pattern Recognition Letters. Vol. 20, No. 11–13, pages 1103–1111.
[2] UCI Machine Learning Repository: Japanese Vowels Dataset. https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels