長短期記憶ニューラル ネットワーク
このトピックでは、長短期記憶 (LSTM) ニューラル ネットワークを使用して、分類タスクと回帰タスク用のシーケンス データおよび時系列データを扱う方法を説明します。LSTM ニューラル ネットワークを使用してシーケンス データを分類する方法を示す例については、深層学習を使用したシーケンスの分類を参照してください。
LSTM ニューラル ネットワークは、再帰型ニューラル ネットワーク (RNN) の一種で、シーケンス データのタイム ステップ間の長期的な依存関係を学習できます。
LSTM ニューラル ネットワーク アーキテクチャ
LSTM ニューラル ネットワークの中核コンポーネントはシーケンス入力層と LSTM 層です。"シーケンス入力層" は、ニューラル ネットワークにシーケンス データまたは時系列データを入力します。"LSTM 層" は、シーケンス データのタイム ステップ間の長期的な依存関係を学習します。
次の図は、分類用のシンプルな LSTM ニューラル ネットワークのアーキテクチャを示しています。このニューラル ネットワークはシーケンス入力層で始まり、その後に LSTM 層が続きます。クラス ラベルを予測するために、このニューラル ネットワークは全結合層とソフトマックス層で終わります。

次の図は、回帰用のシンプルな LSTM ニューラル ネットワークのアーキテクチャを示しています。このニューラル ネットワークはシーケンス入力層で始まり、その後に LSTM 層が続きます。このニューラル ネットワークは全結合層で終わります。

分類用の LSTM ネットワーク
sequence-to-label 分類用の LSTM ネットワークを作成するには、シーケンス入力層、LSTM 層、全結合層、およびソフトマックス層を含む層配列を作成します。
シーケンス入力層のサイズを入力データの特徴の数に設定します。全結合層のサイズをクラスの数に設定します。シーケンス長を指定する必要はありません。
LSTM 層では、隠れユニットの数と出力モード "last" を指定します。
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer];
sequence-to-label 分類について LSTM ネットワークに学習をさせ、新しいデータを分類する方法の例については、深層学習を使用したシーケンスの分類を参照してください。
sequence-to-sequence 分類用の LSTM ネットワークを作成するには、sequence-to-label 分類の場合と同じアーキテクチャを使用しますが、LSTM 層の出力モードを "sequence" に設定します。
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="sequence") fullyConnectedLayer(numClasses) softmaxLayer];
回帰用の LSTM ネットワーク
sequence-to-one 回帰用の LSTM ネットワークを作成するには、シーケンス入力層、LSTM 層、および全結合層を含む層配列を作成します。
シーケンス入力層のサイズを入力データの特徴の数に設定します。全結合層のサイズを応答の数に設定します。シーケンス長を指定する必要はありません。
ニューラル ネットワークに学習させるときに、NormalizeTargets 学習オプション (R2026a で導入) を使用して、学習ターゲットを自動的に正規化できます。正規化されたターゲットを使用することで、学習が安定し、正規化されたターゲットにほぼ一致する学習予測が得られます。予測時にのみ、正規化されていない値の空間でニューラル ネットワークの出力予測を行うには、逆正規化層 (R2026a で導入) を含めます。R2026a より前: 学習を安定させるために、ニューラル ネットワークに学習させる前にターゲットを手動で正規化します。
LSTM 層では、隠れユニットの数と出力モード "last" を指定します。
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numResponses) inverseNormalizationLayer];
sequence-to-sequence 回帰用の LSTM ネットワークを作成するには、sequence-to-one 回帰の場合と同じアーキテクチャを使用しますが、LSTM 層の出力モードを "sequence" に設定します。
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="sequence") fullyConnectedLayer(numResponses) inverseNormalizationLayer];
sequence-to-sequence 回帰について LSTM ネットワークに学習をさせて、新しいデータを予測する方法の例については、深層学習を使用した sequence-to-sequence 回帰を参照してください。
ビデオ分類ネットワーク
ビデオ データや医用画像などのイメージのシーケンスを含むデータ用の深層学習ネットワークを作成するには、シーケンス入力層を使用してイメージ シーケンス入力を指定します。
層を指定して、dlnetwork オブジェクトを作成します。
inputSize = [64 64 3];
filterSize = 5;
numFilters = 20;
numHiddenUnits = 200;
numClasses = 10;
layers = [
sequenceInputLayer(inputSize)
convolution2dLayer(filterSize,numFilters)
batchNormalizationLayer
reluLayer
lstmLayer(numHiddenUnits,OutputMode="last")
fullyConnectedLayer(numClasses)
softmaxLayer];
net = dlnetwork(layers);ビデオの分類用の深層学習ネットワークに学習させる方法を示す例については、深層学習を使用したビデオの分類を参照してください。
深い LSTM ネットワーク
出力モードが "sequence" の追加の LSTM 層を LSTM 層の前に挿入すると、LSTM ネットワークを深くできます。過適合を防止するために、LSTM 層の後にドロップアウト層を挿入できます。
sequence-to-label 分類ネットワークでは、最後の LSTM 層の出力モードは "last" でなければなりません。
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,OutputMode="sequence") dropoutLayer(0.2) lstmLayer(numHiddenUnits2,OutputMode="last") dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer];
sequence-to-sequence 分類ネットワークでは、最後の LSTM 層の出力モードは "sequence" でなければなりません。
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,OutputMode="sequence") dropoutLayer(0.2) lstmLayer(numHiddenUnits2,OutputMode="sequence") dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer];
層
| アイコン | 層 | 説明 |
|---|---|---|
| シーケンス入力層は、シーケンス データをニューラル ネットワークに入力し、データ正規化を適用します。 | |
| 埋め込み層は、数値インデックスを数値ベクトルに変換します。ここで、インデックスは離散データに対応します。 | |
| LSTM 層は、時系列データおよびシーケンス データのタイム ステップ間の長期的な依存関係を学習する RNN 層です。 | ||
| LSTM 投影層は、投影された学習可能なパラメーターの重みを使用して、時系列データおよびシーケンス データのタイム ステップ間の長期的な依存関係を学習する RNN 層です。 | ||
| 双方向 LSTM (BiLSTM) 層は、時系列データまたはシーケンス データのタイム ステップ間の双方向の長期的な依存関係を学習する RNN 層です。これらの依存関係は、各タイム ステップで時系列全体から RNN に学習させる場合に役立ちます。 | ||
| GRU 層は、時系列データおよびシーケンス データのタイム ステップ間の依存関係を学習する RNN 層です。 | ||
| GRU 投影層は、投影された学習可能なパラメーターの重みを使用して、時系列データおよびシーケンス データのタイム ステップ間の依存関係を学習する RNN 層です。 | ||
| 1 次元畳み込み層は、1 次元入力にスライディング畳み込みフィルターを適用します。 | ||
| 1 次元転置畳み込み層では 1 次元の特徴マップがアップサンプリングされます。 | ||
| 1 次元最大プーリング層は、入力を 1 次元のプーリング領域に分割し、各領域の最大値を計算することによって、ダウンサンプリングを実行します。 | ||
| 1 次元平均プーリング層は、入力を 1 次元のプーリング領域に分割し、各領域の平均値を計算することによって、ダウンサンプリングを実行します。 | ||
| 1 次元グローバル最大プーリング層は、入力の時間次元または空間次元の最大値を出力することによって、ダウンサンプリングを実行します。 | ||
| フラット化層は、入力の空間次元を折りたたんでチャネルの次元にします。 | ||
| 単語埋め込み層は、単語インデックスをベクトルにマッピングします。 | |
| Peephole LSTM 層は LSTM 層のバリアントであり、ゲート計算で層のセル状態が使用されるようにするためのものです。 |

分類、予測および予想
新しいデータに対して予測を行うには、関数 minibatchpredict を使用します。予測された分類スコアをラベルに変換するには、scores2label を使用します。
LSTM ニューラル ネットワークは予測間のニューラル ネットワークの状態を記憶できます。RNN の状態は、時系列全体が事前に存在しない場合や長い時系列について複数の予測が必要な場合に役に立ちます。
時系列の一部について予測して分類し、RNN の状態を更新するには、関数 predict を使用し、ニューラル ネットワークの状態を返して更新します。予測間の RNN の状態をリセットするには、resetState を使用します。
シーケンスの将来のタイム ステップを予測する方法を示す例については、深層学習を使用した時系列予測を参照してください。
シーケンスのパディングと切り捨て
LSTM ニューラル ネットワークは、シーケンス長が異なる入力データをサポートしています。ニューラル ネットワークにデータが渡されるとき、各ミニバッチのすべてのシーケンスが指定された長さになるように、パディングまたは切り捨てが行われます。シーケンス長とシーケンスのパディングに使用する値は、SequenceLength と SequencePaddingValue の学習オプションを使用して指定できます。
ニューラル ネットワークの学習後、関数 minibatchpredict の使用時に同じミニバッチ サイズとパディング オプションを使用できます。
長さでのシーケンスの並べ替え
シーケンスのパディングまたは切り捨ての際に、パディングまたは破棄するデータの量を減らすには、シーケンス長でデータを並べ替えてみてください。最初の次元がタイム ステップに対応するシーケンスの場合、シーケンス長でデータを並べ替えるには、まず cellfun を使用してすべてのシーケンスに size(X,1) を適用することによって各シーケンスの列数を取得します。次に、sort を使用してシーケンス長を並べ替え、2 番目の出力を使用して元のシーケンスを並べ替えます。
sequenceLengths = cellfun(@(X) size(X,1), XTrain); [sequenceLengthsSorted,idx] = sort(sequenceLengths); XTrain = XTrain(idx);

シーケンスのパディング
SequenceLength 学習オプションまたは予測オプションが "longest" の場合、ソフトウェアは、ミニバッチのすべてのシーケンスがそのミニバッチにある最長のシーケンスと同じ長さになるようにシーケンスをパディングします。このオプションは既定値です。

シーケンスの切り捨て
SequenceLength 学習オプションまたは予測オプションが "shortest" の場合、ソフトウェアは、ミニバッチのすべてのシーケンスがそのミニバッチにある最短のシーケンスと同じ長さになるようにシーケンスを切り捨てます。シーケンスの残りのデータは破棄されます。

パディングの方向の指定
パディングと切り捨ての位置は、学習、分類、および予測の精度に影響する可能性があります。SequencePaddingDirection 学習オプションを "left" または "right" に設定してみて、どちらがデータに適しているかを確認します。
再帰層は 1 タイム ステップずつシーケンス データを処理するため、再帰層の OutputMode プロパティが "last" の場合、最後のタイム ステップでパディングを行うと層の出力に悪影響を与える可能性があります。シーケンス データの左側に対してパディングまたは切り捨てを行うには、名前と値の引数 SequencePaddingDirection を "left" に設定します。
sequence-to-sequence ニューラル ネットワークの場合 (各再帰層について OutputMode プロパティが "sequence" である場合)、最初のタイム ステップでパディングを行うと、それ以前のタイム ステップの予測に悪影響を与える可能性があります。シーケンス データの右側に対してパディングまたは切り捨てを行うには、名前と値の引数 SequencePaddingDirection を "right" に設定します。


シーケンス データの正規化
ゼロ中心正規化を使用して学習時に学習データを自動的に再センタリングするには、sequenceInputLayer の Normalization オプションを "zerocenter" に設定します。または、まず、すべてのシーケンスについて特徴あたりの平均値と標準偏差を計算することによって、シーケンス データを正規化できます。次に、各学習観測値について、平均値を減算し、標準偏差で除算します。
mu = mean([XTrain{:}],1);
sigma = std([XTrain{:}],0,1);
XTrain = cellfun(@(X) (X-mu)./sigma,XTrain,UniformOutput=false);メモリ外のデータ
データが大きすぎてメモリに収まらない場合や、データのバッチを読み取る際に特定の演算を実行する場合、シーケンス データ、時系列データ、および信号データについてデータストアを使用します。
詳細は、メモリ外のシーケンス データを使用したネットワークの学習および深層学習を使用したメモリ外のテキスト データの分類を参照してください。
可視化
関数 minibatchpredict を使用し、引数 Outputs を設定して活性化を抽出することによって、シーケンス データと時系列データから LSTM ニューラル ネットワークによって学習された特徴を調べて可視化します。詳細については、LSTM ネットワークの活性化の可視化を参照してください。
LSTM 層アーキテクチャ
次の図は、入力 と出力 をもつ LSTM 層を T 個のタイム ステップで通過するデータの流れを示したものです。この図で、 は、出力 ("隠れ状態" とも呼ばれる) を表し、 はタイム ステップ t での "セル状態" を表しています。
層がシーケンス全体を出力する場合、層は , …, を出力します。これは、, …, と等価です。層が最後のタイム ステップのみを出力する場合、層は を出力します。これは、 と等価です。出力内のチャネル数は、LSTM 層の隠れユニット数と一致します。
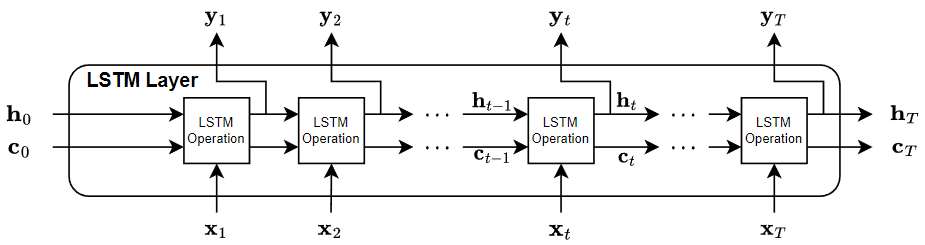
最初の LSTM 演算では、RNN の初期状態とシーケンスの最初のタイム ステップを使用して、最初の出力と更新後のセル状態を計算します。タイム ステップ t での演算では、RNN の現在の状態 とシーケンスの次のタイム ステップを使用して、出力と更新後のセル状態 を計算します。
層の状態は、"隠れ状態" ("出力状態" とも呼ばれる) および "セル状態" で構成されています。タイム ステップ t の隠れ状態には、このタイム ステップの LSTM 層の出力が含まれています。セル状態には、前のタイム ステップで学習した情報が含まれています。各タイム ステップで、層では情報をセル状態に追加したり、セル状態から削除したりします。その際、層では "ゲート" を使用して、これらの更新を制御します。
以下のコンポーネントは、層のセル状態および隠れ状態を制御します。
| コンポーネント | 目的 |
|---|---|
| 入力ゲート (i) | セル状態の更新レベルを制御 |
| 忘却ゲート (f) | セル状態のリセット (忘却) レベルを制御 |
| セル候補 (g) | セル状態に情報を追加 |
| 出力ゲート (o) | 隠れ状態に追加されるセル状態のレベルを制御 |
次の図は、タイム ステップ t でのデータのフローを示しています。この図は、ゲートがセル状態や隠れ状態をどのように忘却、更新、および出力するかを示しています。

LSTM 層の学習可能なパラメーターの重みは、入力の重み W (InputWeights)、再帰重み R (RecurrentWeights)、およびバイアス b (Bias) です。行列 W、R、および b はそれぞれ、各コンポーネントの入力の重み、再帰重み、およびバイアスの連結です。この層は、次の方程式に従って行列を連結します。
ここで、i、f、g、および o はそれぞれ、入力ゲート、忘却ゲート、セル候補、および出力ゲートを表します。
タイム ステップ t でのセル状態は次で与えられます。
ここで、 はアダマール積 (ベクトルの要素単位の乗算) を表します。
タイム ステップ t での隠れ状態は次で与えられます。
ここで、 は状態活性化関数を表します。既定では、関数 lstmLayer は双曲線正接関数 (tanh) を使用して状態活性化関数を計算します。
次の式は、タイム ステップ t におけるコンポーネントを表しています。
| コンポーネント | 式 |
|---|---|
| 入力ゲート | |
| 忘却ゲート | |
| セル候補 | |
| 出力ゲート |
これらの計算では、 はゲート活性化関数を表します。既定では、関数 lstmLayer は で与えられるシグモイド関数を使用して、ゲート活性化関数を計算します。
参照
[1] Hochreiter, S., and J. Schmidhuber. "Long short-term memory." Neural computation. Vol. 9, Number 8, 1997, pp.1735–1780.
参考
sequenceInputLayer | lstmLayer | bilstmLayer | gruLayer | dlnetwork | minibatchpredict | predict | scores2label | flattenLayer | wordEmbeddingLayer (Text Analytics Toolbox)