comm.gpu.ConvolutionalDeinterleaver
(削除予定) GPU による一連のシフト レジスタを使用したシンボルのデインターリーブ
comm.gpu.ConvolutionalDeinterleaver は将来のリリースで削除される予定です。代わりに convdeintrlv を使用してください。 (R2026a 以降)コードの更新の詳細については、バージョン履歴を参照してください。
説明
comm.gpu.ConvolutionalDeinterleaver System object™ は、グラフィックス処理装置 (GPU) を使用して入力シーケンスのシンボルをデインターリーブします。
GPU を使用して入力シーケンスのシンボルをデインターリーブするには、次のようにします。
comm.gpu.ConvolutionalDeinterleaverオブジェクトを作成し、そのプロパティを設定します。関数と同様に、引数を指定してオブジェクトを呼び出します。
System object の機能の詳細については、System object とはを参照してください。
作成
構文
説明
deintrlvr = comm.gpu.ConvolutionalDeinterleaver
deintrlvr = comm.gpu.ConvolutionalDeinterleaver(Name=Value)NumRegisters=10 は内部シフト レジスタの数を指定します。
intrlvr = comm.gpu.ConvolutionalDeinterleaver(m,b,ic)NumRegisters プロパティを m に、RegisterLengthStep プロパティを b に、InitialConditions プロパティを ic に設定します。
プロパティ
使用法
説明
deintrlvseq = deintrlvr(intrlvseq)inputseq をデインターリーブします。出力は、デインターリーブされたシーケンスです。
遅延の詳細については、畳み込みインターリーブと畳み込みデインターリーブの遅延を参照してください。
入力引数
出力引数
オブジェクト関数
オブジェクト関数を使用するには、System object を最初の入力引数として指定します。たとえば、obj という名前の System object のシステム リソースを解放するには、次の構文を使用します。
release(obj)
例
詳細
畳み込みインターリーバーと畳み込みデインターリーバーのペアによる合計遅延は N × slope × (N – 1) です。
N はレジスタの数で、
NumRegistersプロパティの値と同じslope はレジスタの長さのステップで、
RegisterLengthStepプロパティの値と同じ
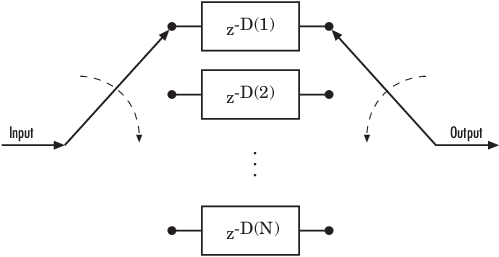
次の図は、シフト レジスタのセットで構成される一般的な畳み込みインターリーバーの構造を示しています。各シフト レジスタには、D(1)、D(2)、...、D(N) として示される指定された遅延と、入力を切り替え、レジスタを経由してシンボルを出力するコミュテーターがあります。k 番目のシフト レジスタは D(k) 個のシンボルを保持します。ここで k = 1, 2, 3, … N です。k 番目のシフト レジスタの遅延値は ((k–1) × slope) です。新しい入力シンボルごとに、コミュテーターは新しいレジスタに切り替わり、新しいシンボルをシフトインしながら、そのレジスタ内の最も古いシンボルをシフトアウトします。コミュテーターが N 番目のレジスタに到達し、次の新しい入力が発生すると、コミュテーターは最初のレジスタに戻ります。
ヒント
このオブジェクトを使用するには、Parallel Computing Toolbox™ がインストールされており、サポートされる GPU にアクセスできなければなりません。ホスト コンピューターに GPU が構成されている場合、処理には GPU が使用されます。そうでない場合、処理には CPU が使用されます。GPU の詳細については、GPU コンピューティング (Parallel Computing Toolbox)を参照してください。
拡張機能
バージョン履歴
R2012a で導入参考
オブジェクト
gpuArray(Parallel Computing Toolbox)
関数
ブロック
トピック
- インターリーブ
- System object の GPU 配列のサポート リスト
- GPU コンピューティング (Parallel Computing Toolbox)
- GPU を使用したシミュレーションの高速化