このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
GPU を使用したシミュレーションの高速化
GPU ベースの処理をサポートする関数または System object を使用し、MATLAB® のシミュレーションを設計できます。GPU ベースの System object を含むMATLAB System (Simulink) ブロックを使用して Simulink® モデルを構築することもできます。GPU は、大量データの処理と高負荷計算の実行に威力を発揮します。大量データ処理とは、シミュレーションにおいて GPU のスループットを最大限に活用する 1 つの手法です。GPU が一度に処理するデータ量は、GPU ベースのシミュレーションの入力に渡されるデータのサイズによって異なります。
GPU ベースのシミュレーションに MATLAB 配列を渡すには、GPU ベースの処理を行うための初期データを CPU から GPU に転送しなければなりません。その後、シミュレーションによって出力データが CPU に返されます。この処理を繰り返すとレイテンシが発生します。gpuArray (Parallel Computing Toolbox) オブジェクトの形式で GPU 対応関数または System object™ にデータを渡すと、データ転送によるレイテンシを回避できます。そのため、gpuArray オブジェクトを入力として与え、シミュレーションで CPU と GPU との間のデータ転送回数を最小限に抑えると、GPU ベースのシミュレーションの実行速度が速くなります。詳細については、GPU での配列の確立 (Parallel Computing Toolbox)を参照してください。
GPU を使用した LDPC 復号化
GPU を使用して、LDPC 符号化、PSK 変調、AWGN チャネル モデリング、PSK 復調、LDPC 復号化、およびビット エラー レートの計算を高速化します。この例では、確率伝播復号化アルゴリズムおよび正規化 min-sum 復号化アルゴリズムの誤り統計を計算します。
LDPC 構成オブジェクトの作成
LDPC 符号化器構成オブジェクトおよび LDPC 復号化器構成オブジェクトを作成します。シミュレーション変数を定義します。
% Use ldpcQuasiCyclicMatrix to create a parity-check matrix load("LDPCExamplePrototypeMatrix.mat","P"); % A prototype matrix from the 5G standard blockSize = 384; H = ldpcQuasiCyclicMatrix(blockSize, P); encoderCfg = ldpcEncoderConfig(H); decoderCfg1 = ldpcDecoderConfig(encoderCfg); % The default algorithm is "bp" decoderCfg2 = ldpcDecoderConfig(encoderCfg,"norm-min-sum"); M = 4; % Modulation order (QPSK) snr = [-2 -1.5 -1]; numFramesPerCall = 50; numCalls = 40; maxNumIter = 20; s = rng(1235); % Fix random seed errRate = zeros(length(snr),2);
ビット エラー レートの計算
gpuArray (Parallel Computing Toolbox)オブジェクトにランダム ビットを生成し、そのデータを ldpcEncode、pskmod、awgn、pskdemod、ldpcDecode、および biterr 各関数に順に渡します。各 SNR 設定に対して、確率伝播復号化アルゴリズムおよび正規化 min-sum 復号化アルゴリズムの誤り統計を計算します。
for ii = 1:length(snr) ttlErr = [0 0]; noiseVariance = 1/10^(snr(ii)/10); for counter = 1:numCalls data = gpuArray.randi([0 1],encoderCfg.NumInformationBits,numFramesPerCall,'logical'); % Transmit and receive LDPC coded signal data encData = ldpcEncode(data,encoderCfg); modSig = pskmod(encData,M,pi/4,'InputType','bit'); rxSig = awgn(modSig,snr(ii)); % Signal power = 0 dBW demodSig = pskdemod(rxSig,M,pi/4,... 'OutputType','approxllr','NoiseVariance',noiseVariance); % Decode and update number of bit errors % Using bp rxBits1 = ldpcDecode(demodSig,decoderCfg1,maxNumIter); numErr1 = biterr(data,rxBits1); % Using norm-min-sum rxBits2 = ldpcDecode(demodSig,decoderCfg2,maxNumIter); numErr2 = biterr(data,rxBits2); ttlErr = ttlErr + [numErr1 numErr2]; end ttlBits = numCalls*numel(rxBits1); errRate(ii,:) = ttlErr/ttlBits; end
ビット エラー レートの比較
誤り統計をプロットします。確率伝播アルゴリズムのビット エラー レートは、正規化 min-sum アルゴリズムよりもわずかに低くなることが予想されます。
plot(snr,errRate,'-x') grid on legend('bp','norm-min-sum') xlabel('SNR (dB)') ylabel('BER')
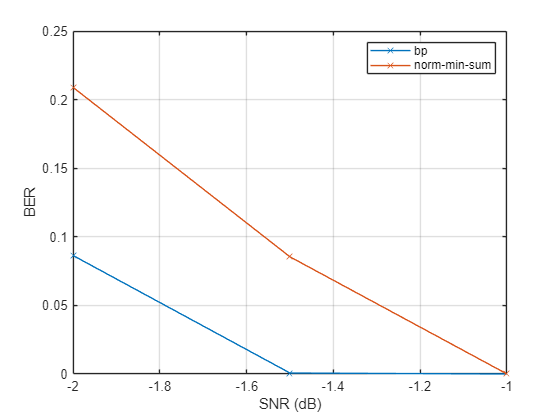
速度の比較
4 つの場合について実行時間を比較します。既定では、ldpcDecode はすべてのパリティ チェックが満たされた後に復号化を終了します。
% Use belief propagation algorithm on CPU, without multithreading demodSigCPU = gather(demodSig); tic [rxBitsCPU1,actualNumIterCPU1,finalParityChecksCPU1] = ... ldpcDecode(demodSigCPU,decoderCfg1,maxNumIter,'Multithreaded',false); toc
Elapsed time is 4.270400 seconds.
% Use belief propagation algorithm on CPU, with multithreading tic [rxBitsCPU2,actualNumIterCPU2,finalParityChecksCPU2] = ... ldpcDecode(demodSigCPU,decoderCfg1,maxNumIter); toc
Elapsed time is 1.069500 seconds.
% Use belief propagation algorithm on GPU tic [rxBits1,actualNumIter1,finalParityChecks1] = ... ldpcDecode(demodSig,decoderCfg1,maxNumIter); toc
Elapsed time is 2.117112 seconds.
% Use normalized min-sum algorithm on GPU tic [rxBits2,actualNumIter2,finalParityChecks2] = ... ldpcDecode(demodSig,decoderCfg2,maxNumIter); toc
Elapsed time is 0.615488 seconds.
オプションの復号化器出力の確認
SNR が十分高い場合は、確率伝播アルゴリズムよりも正規化 min-sum アルゴリズムの方が少ない反復回数で済むことを確認します。
length(find(actualNumIter2 < actualNumIter1))
ans = 50
length(find(actualNumIter2 == actualNumIter1))
ans = 0
指定した最大反復回数よりも実際に実行された反復回数の方が少ない場合、最終的なパリティ チェックの結果がすべてゼロになることを確認します。
nnz(finalParityChecks1(:,actualNumIter1<maxNumIter))
ans = 0
nnz(finalParityChecks2(:,actualNumIter2<maxNumIter))
ans = 0
乱数発生器の状態を復元します。
rng(s);
GPU ベースの System object を使用した複数のデータ フレームの処理
1 つの GPU System object™ を使用して、複数のデータ フレームを同時に処理できます。ビタビ復号化器などの一部の GPU ベースの System object では、システムのフレーム サイズをオブジェクトのプロパティから推定することはできません。代わりに、ビタビ復号化器オブジェクトの NumFrames プロパティを使用して、入力データに含まれるフレーム数を定義しなければなりません。
numframes = 10; convEncoder = comm.ConvolutionalEncoder( ... TerminationMethod="Terminated"); vitDecoder = comm.ViterbiDecoder( ... TerminationMethod="Terminated");
NumFrames プロパティを使用して、GPU ベースのビタビ復号化器 System object を作成します。
vitGPUDecoder = comm.gpu.ViterbiDecoder( ... TerminationMethod="Terminated", ... NumFrames=numframes); msg = randi([0 1],200,numframes); for ii=1:numframes convEncOut(:,ii) = 1-2*convEncoder(msg(:,ii)); end % Decode on the CPU for ii=1:numframes cVitOut(:,ii) = vitDecoder(convEncOut(:,ii)); end % Decode on the GPU gVitOut = vitGPUDecoder(convEncOut(:)); % Check equality isequal(gVitOut,cVitOut(:))
ans = logical
1
gpuarray 入力を使用した GPU ベースの System object へのデータの受け渡し
この例では、畳み込み符号化率 1/2 の 16-PSK 変調データを AWGN チャネル経由で送信し、受信データを復調および復号化して受信データのエラー レートを評価します。この実装では、GPU ベースのビタビ復号化器 System object™ を使用して複数の信号フレームを 1 回の呼び出しで処理し、gpuArray (Parallel Computing Toolbox)オブジェクトを使用して GPU ベースの System object との間でデータをやり取りします。
PSK 変調と復調、畳み込み符号化、およびビタビ復号化用の、GPU ベースの System object を作成します。エラー レート計算用の System object を作成します。
M = 16; % Modulation order numframes = 100; gpuconvenc = comm.gpu.ConvolutionalEncoder; gpupskmod = comm.gpu.PSKModulator(M,pi/16,BitInput=true); gpupskdemod = comm.gpu.PSKDemodulator(M,pi/16,BitOutput=true); gpuvitdec = comm.gpu.ViterbiDecoder( ... InputFormat='Hard', ... TerminationMethod='Truncated', ... NumFrames=numframes); errorrate = comm.ErrorRate(ComputationDelay=0,ReceiveDelay=0);
ビタビ復号化アルゴリズムの計算量ゆえに、信号データの複数のフレームを GPU に読み込んで 1 回の呼び出しで処理すると、シミュレーション全体の時間を短縮できます。この実装を有効にするために、GPU ベースのビタビ復号化器 System object には NumFrames プロパティが含まれています。外部 for ループを使用してデータの個々のフレームを処理する代わりに、NumFrames プロパティを使用して GPU ベースのビタビ復号化器 System object を構成し、複数のデータ フレームを処理します。バイナリ データ フレームの numframes を生成します。GPU ベースの System object による処理のためにデータ フレームを効率的に管理するには、送信データ フレームを gpuArray オブジェクトとして表現します。
numsymbols = 50; rate = 1/2; dataA = gpuArray.randi([0 1],rate*numsymbols*log2(M),numframes);
エラー レート オブジェクトは gpuArray オブジェクトやマルチチャネル データをサポートしていないため、関数gather (Parallel Computing Toolbox)を使用して GPU から配列を取得し、for ループ内でデータの各フレームのエラー レートを計算しなければなりません。for ループ内で GPU ベースの符号化、変調、AWGN、および復調を実行します。
for ii = 1:numframes encodedData = gpuconvenc(dataA(:,ii)); modsig = gpupskmod(encodedData); noisysig = awgn(modsig,30); % SNR = 30 dB. Signal power = 0 dBW demodsig(:,ii) = gpupskdemod(noisysig); end
GPU ベースのビタビ復号化器は、for ループなしでマルチフレーム処理を実行します。
rxbits = gpuvitdec(demodsig(:)); errorStats = errorrate(gather(dataA(:)),gather(rxbits)); fprintf('BER = %f\nNumber of errors = %d\nTotal bits = %d', ... errorStats(1), errorStats(2), errorStats(3))
BER = 0.009900 Number of errors = 99 Total bits = 10000
MATLAB System ブロックでの GPU ベースの System object のサポート
実装で MATLAB System (Simulink) ブロックを使用している場合、以下の GPU ベースの System object を含めることができます。
comm.gpu.BlockDeinterleavercomm.gpu.BlockInterleavercomm.gpu.ConvolutionalDeinterleavercomm.gpu.ConvolutionalEncodercomm.gpu.ConvolutionalInterleavercomm.gpu.PSKDemodulatorcomm.gpu.PSKModulatorcomm.gpu.TurboDecodercomm.gpu.ViterbiDecoder
これらの GPU System object は、[インタープリター型実行] オプションを使用してシミュレートしなければなりません。このオプションは、ブロック マスクの [シミュレーション実行方法] パラメーターから明示的に選択します。既定値は [コード生成] です。

参考
トピック
- GPU での MATLAB 関数の実行 (Parallel Computing Toolbox)
- GPU 計算の要件 (Parallel Computing Toolbox)
- C/C++ コード生成