イメージとビデオの分類
Computer Vision Toolbox™ は、深層学習や従来型のコンピューター ビジョン技術を使用してイメージやビデオを分類するためのエンドツーエンドのワークフローを提供します。イメージ カテゴリ分類には、深層学習に基づく事前学習済みのビジョン トランスフォーマー (ViT) モデルや CLIP モデルを使用するか、視覚的コンテンツに基づいてイメージを分類する bag-of-visual-words アプローチを適用することができます。これらのワークフローは、シーン認識、コンテンツ フィルター処理、自動タグ付けなどの用途をサポートします。まず、イメージ ラベラー アプリとビデオ ラベラー アプリを使用してシーンレベルのカテゴリにラベルを付け、次にラベル付けしたデータを使用してモデルの学習または微調整を行います。
ビデオの分類やアクティビティ認識において、ツールボックスを使用することで、深層学習モデルを使用して、フレームのシーケンスを歩く、泳ぐ、座るなどの動作カテゴリに分類できます。これらの機能は、ヒューマン-コンピューター インタラクションや監視などのタスクに不可欠です。ツールボックスは、ビデオ データ内の時間的パターンを解釈して複雑なアクティビティやジェスチャを認識できるモデルの学習、評価、および展開をサポートしています。
カテゴリ
- イメージ カテゴリの分類
bag-of-features、CNN、ビジョン トランスフォーマー、視覚言語モデルを使用してイメージを分類する
- ビデオ分類
深層学習を使用してビデオを分類し、アクティビティ認識を実行する
注目の例
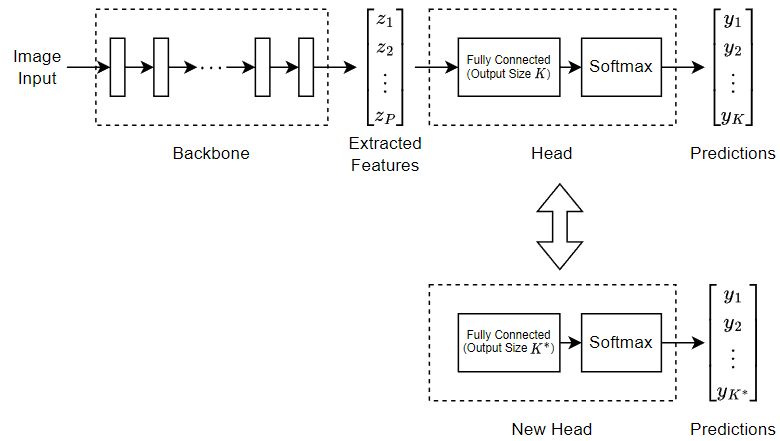
イメージ分類のためのビジョン トランスフォーマー ネットワークの学習
この例では、事前学習済みのビジョン トランスフォーマー (ViT) ニューラル ネットワークを微調整して、新しいイメージ コレクションを分類する方法を説明します。

bag of features を使用したイメージ カテゴリの分類
この例では、bag of features の手法を使用してイメージ カテゴリの分類を行う方法を説明します。この手法は、多くの場合 bag of words とも呼ばれます。視覚的イメージの分類は、テスト対象のイメージにカテゴリ ラベルを割り当てる処理です。カテゴリには犬、猫、列車、船舶など、あらゆるものを表すイメージが含まれます。

深層学習を使用したイメージ カテゴリの分類
この例では、事前学習済みの畳み込みニューラル ネットワーク (CNN) を特徴抽出器として使用して、イメージ カテゴリ分類器に学習させる方法を説明します。

深層学習を使用したビデオとオプティカル フロー データのアクティビティ認識
ビデオの RGB データとオプティカル フロー データを使用し、アクティビティ認識用の I3D (Inflated 3-D) 2 ストリーム畳み込みニューラル ネットワークに学習させる。
Human Activity Recognition Using R(2+1)D Video Classification
Train an R(2+1)D video classifier for activity recognition.
Gesture Recognition using Videos and Deep Learning
Train a SlowFast convolutional neural network for gesture recognition using RGB data from videos.