深層学習を使用したビデオとオプティカル フロー データのアクティビティ認識
この例では、まず、事前学習済みの Inflated 3-D (I3D) 2 ストリーム畳み込みニューラル ネットワークをベースとしたビデオ分類器を使用してアクティビティ認識を行う方法を説明し、次に、ビデオの RGB データとオプティカル フロー データを使用して、転移学習によりそのようなビデオ分類器に学習させる方法を説明します [1]。
概要
視覚ベースのアクティビティ認識では、一連のビデオ フレームを使用し、歩く、泳ぐ、座るといったオブジェクトのアクションを予測します。ビデオのアクティビティ認識は、ヒューマン-コンピューター インタラクション、ロボット学習、異常検出、監視、オブジェクト検出といったさまざまな分野で応用されています。たとえば、複数カメラから入力されるビデオから複数のアクションをオンラインで予測することは、ロボット学習にとって重要です。ビデオのデータ セットに含まれるグラウンド トゥルース データは不正確で、ビデオ内のアクターによって実行される動作は多種多様であり、データ セットのクラスは非常に偏っており、ロバストな分類器にゼロから学習させるには大量のデータが必要であるため、ビデオを使用したアクション認識はイメージ分類と比べてモデル化が困難です。I3D 2 ストリーム畳み込みネットワーク [1]、R(2+1)D [4]、および SlowFast [5] などの深層学習手法では、Kinetics-400 [6] などの大規模なビデオ アクティビティ認識データセットで事前学習済みのネットワークを使用して転移学習を行うことにより、小規模なデータセットでパフォーマンスを改善できることが示されています。
メモ: この例では、Computer Vision Toolbox™ Model for Inflated-3D Video Classification が必要です。Computer Vision Toolbox Model for Inflated-3D Video Classification はアドオン エクスプローラーからインストールできます。アドオンのインストールの詳細については、アドオンの取得と管理を参照してください。
事前学習済みの Infrated-3D (I3D) ビデオ分類器の読み込み
事前学習済みの Inflated-3D ビデオ分類器、およびアクティビティ認識を行うビデオ ファイルをダウンロードします。ダウンロードした zip ファイルのサイズは約 89 MB です。
downloadFolder = fullfile(tempdir,"hmdb51","pretrained","I3D"); if ~isfolder(downloadFolder) mkdir(downloadFolder); end filename = "activityRecognition-I3D-HMDB51-21b.zip"; zipFile = fullfile(downloadFolder,filename); if ~isfile(zipFile) disp('Downloading the pretrained network...'); downloadURL = "https://ssd.mathworks.com/supportfiles/vision/data/" + filename; websave(zipFile,downloadURL); unzip(zipFile,downloadFolder); end
事前学習済みの Inflated-3D ビデオ分類器を読み込みます。
pretrainedDataFile = fullfile(downloadFolder,"inflated3d-FiveClasses-hmdb51.mat");
pretrained = load(pretrainedDataFile);
inflated3dPretrained = pretrained.data.inflated3d;ビデオ シーケンス内のアクティビティの分類
事前学習済みのビデオ分類器のクラス ラベル名を表示します。
classes = inflated3dPretrained.Classes
classes = 5×1 categorical array
"kiss"
"laugh"
"pick"
"pour"
"pushup"
VideoReader と vision.VideoPlayer を使用し、ビデオ pour.avi を読み取って表示します。
videoFilename = fullfile(downloadFolder, "pour.avi"); videoReader = VideoReader(videoFilename); videoPlayer = vision.VideoPlayer; videoPlayer.Name = "pour"; while hasFrame(videoReader) frame = readFrame(videoReader); % Resize the frame for display. frame = imresize(frame, 1.5); step(videoPlayer,frame); end release(videoPlayer);
ビデオの分類に使用する 10 個のビデオ シーケンスをランダムに選択します。その際、ビデオ内で最も顕著なアクション クラスを検出できるように、ファイル全体から均等に選択します。
numSequences = 10;
関数 classifyVideoFile を使用して、ビデオ ファイルを分類します。
[actionLabel,score] = classifyVideoFile(inflated3dPretrained, videoFilename, "NumSequences", numSequences)
actionLabel = categorical
pour
score = single
0.4482
学習データの読み込み
この例では、HMDB51 データ セットを使用して I3D ビデオ分類器に学習させます。https://serre.lab.brown.edu/hmdb51.html から hmdb51_org.rar をダウンロードし、次のフォルダーに保存します。
downloadFolder = fullfile(tempdir,"hmdb51");ダウンロードが完了したら、RAR ファイル hmdb51_org.rar を hmdb51 フォルダーに解凍します。次に、この例の最後にリストされている補助関数 checkForHMDB51Folder を使用し、ダウンロードして解凍したファイルが所定の場所にあることを確認します。
allClasses = checkForHMDB51Folder(downloadFolder);
データ セットには、"飲む"、"走る"、"握手する" など、51 を超えるクラスの 7000 個のクリップから成る約 2 GB のビデオ データが格納されています。各ビデオ フレームの高さは 240 ピクセルで、最小幅は 176 ピクセルです。フレーム数は、18 から約 1000 までの範囲になります。
この例では、学習時間を短縮するために、データ セットに含まれる 51 のすべてのクラスではなく、5 つのアクション クラスを分類するようにアクティビティ認識ネットワークに学習させます。51 のすべてのクラスについて学習させる場合は useAllData を true に設定します。
useAllData = false; if useAllData classes = allClasses; end dataFolder = fullfile(downloadFolder, "hmdb51_org");
データ セットを、分類器に学習させるための学習セットと分類器を評価するためのテスト セットに分割します。データの 80% を学習セットに使用し、残りをテスト セットに使用します。folders2labels および splitlabels を使用し、フォルダーからラベル情報を作成し、各ラベルから一定の割合のファイルをランダムに選択し、各ラベルに基づいてデータを学習データ セットとテスト データ セットに分割します。
[labels,files] = folders2labels(fullfile(dataFolder,string(classes)),... "IncludeSubfolders",true,... "FileExtensions",'.avi'); indices = splitlabels(labels,0.8,'randomized'); trainFilenames = files(indices{1}); testFilenames = files(indices{2});
ネットワークの入力データを正規化するために、データ セットの最小値および最大値が、この例に添付されている MAT ファイル inputStatistics.mat に用意されています。異なるデータ セットの最小値および最大値を見つけるには、この例の最後にリストされているサポート関数 inputStatistics を使用します。
inputStatsFilename = 'inputStatistics.mat'; if ~exist(inputStatsFilename, 'file') disp("Reading all the training data for input statistics...") inputStats = inputStatistics(dataFolder); else d = load(inputStatsFilename); inputStats = d.inputStats; end
データセットの読み込み
この例では、データストアを使用して、ビデオ シーン、対応するオプティカル フロー データ、および対応するラベルをビデオ ファイルから読み取ります。
データストアからデータを読み取るたびに、データストアに出力させるビデオ フレーム数を指定します。
numFrames = 64;
ここでは、メモリ使用量と分類時間のバランスをとるために、64 の値を使用します。一般的に、16、32、64、または 128 の値を検討してください。より多くのフレームを使用すればより多くの時間情報を取得できますが、より多くのメモリが必要になります。システム リソースによっては、この値を下げることが必要になる場合もあります。最適なフレーム数を決定するには、経験的解析が必要です。
次に、データストアに出力させるフレームの高さと幅を指定します。データストアは、複数のビデオ シーケンスをバッチ処理できるように、生のビデオ フレームのサイズを指定されたサイズに自動的に変更します。
frameSize = [112,112];
ビデオ シーンに含まれる長い時間関係を取得する場合、[112 112] の値が使用されます。これは、長時間続くアクティビティを分類するのに役立ちます。サイズの一般的な値は [112 112]、[224 224]、または [256 256] です。サイズを小さくすると、メモリ使用量と処理時間が増え、空間分解能が下がりますが、より多くのビデオ フレームを使用できるようになります。HMDB51 データ セット内のビデオ フレームの高さと幅の最小値は、それぞれ 240 と 176 です。データストアが読み取るフレームのサイズを最小値よりも大きく ([256, 256] など) 指定する場合、まず、imresize を使用してフレームのサイズを変更します。最適なフレーム数の値を決定するには、経験的解析が必要です。
RGB ビデオ サブネットワークのチャネル数を 3、I3D ビデオ分類器のオプティカル フロー サブネットワークのチャネル数を 2 として指定します。オプティカル フロー データの 2 つのチャネルは、速度の 成分と 成分である と をそれぞれ表します。
rgbChannels = 3; flowChannels = 2;
補助関数 createFileDatastore を使用して、データを読み込むための 2 つの FileDatastore オブジェクトを設定します。1 つは学習用、もう 1 つは検証用です。この補助関数は、この例の終わりにリストされています。各データストアは、ビデオ ファイルを読み取って、RGB データおよび対応するラベル情報を提供します。
isDataForTraining = true; dsTrain = createFileDatastore(trainFilenames,numFrames,rgbChannels,classes,isDataForTraining); isDataForTraining = false; dsVal = createFileDatastore(testFilenames,numFrames,rgbChannels,classes,isDataForTraining);
I3D ビデオ分類器の構成
ネットワーク アーキテクチャの定義
I3D ネットワーク
3 次元 CNN の使用は、ビデオから時空間特徴を抽出するための自然なアプローチです。2 次元フィルターとプーリング カーネルを 3 次元に拡張することにより、事前学習済みの 2 次元イメージ分類ネットワーク (Inception v1 や ResNet-50 など) から I3D ネットワークを作成できます。この手順では、イメージ分類タスクから学習した重みを再利用し、ビデオ認識タスクをブートストラップします。
次の図は、2 次元畳み込み層を 3 次元畳み込み層に拡張する方法を示したサンプルです。この拡張では、3 番目の次元 (時間次元) を追加することにより、フィルター サイズ、重み、バイアスを拡張します。

2 ストリーム I3D ネットワーク
ビデオ データは、空間コンポーネントと時間コンポーネントという 2 つの部分をもつと見なすことができます。
空間コンポーネントは、ビデオ内のオブジェクトの形状、テクスチャ、色に関する情報で構成されます。RGB データにはこの情報が含まれています。
時間コンポーネントは、フレーム全体のオブジェクトのモーションに関する情報で構成され、カメラと、シーン内のオブジェクトの間の重要な動作を表します。オプティカル フローの計算は、ビデオから時間情報を抽出するための一般的な手法です。
2 ストリーム CNN には、空間サブネットワークと時間サブネットワークが組み込まれています [2]。高密度のオプティカル フローとビデオ データ ストリームで学習させた畳み込みニューラル ネットワークは、スタックされた生の RGB フレームよりも、制限された学習データを使ってパフォーマンスを改善できます。次の図は、典型的な 2 ストリーム I3D ネットワークを表しています。
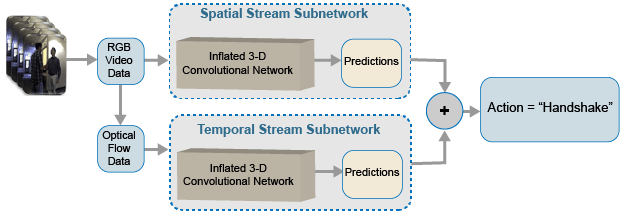
この例では、Kinetics-400 データセットで事前学習させた 3 次元畳み込みニューラル ネットワーク ビデオ分類器である GoogLeNet アーキテクチャに基づいて、I3D ビデオ分類器を作成します。
2 つのサブネットワーク (1 つはビデオ データ用、もう 1 つはオプティカル フロー データ用) を含む I3D ビデオ分類器のバックボーンとなる畳み込みニューラル ネットワーク アーキテクチャとして、GoogLeNet を指定します。
baseNetwork = "googlenet-video-flow";Inflated-3D ビデオ分類器の入力サイズを指定します。
inputSize = [frameSize, rgbChannels, numFrames];
inputStatistics.mat ファイルから読み込まれた inputStats 構造体の RGB データおよびオプティカル フロー データの最小値と最大値を取得します。これらの値は、入力データを正規化するために必要です。
oflowMin = squeeze(inputStats.oflowMin)'; oflowMax = squeeze(inputStats.oflowMax)'; rgbMin = squeeze(inputStats.rgbMin)'; rgbMax = squeeze(inputStats.rgbMax)'; stats.Video.Min = rgbMin; stats.Video.Max = rgbMax; stats.Video.Mean = []; stats.Video.StandardDeviation = []; stats.OpticalFlow.Min = oflowMin(1:flowChannels); stats.OpticalFlow.Max = oflowMax(1:flowChannels); stats.OpticalFlow.Mean = []; stats.OpticalFlow.StandardDeviation = [];
関数 inflated3dVideoClassifier を使用して、I3D ビデオ分類器を作成します。
i3d = inflated3dVideoClassifier(baseNetwork,string(classes),... "InputSize",inputSize,... "InputNormalizationStatistics",stats);
ビデオ分類器のモデル名を指定します。
i3d.ModelName = "Inflated-3D Activity Recognizer Using Video and Optical Flow";学習用データの準備
データ拡張を使用すると、限られたデータ セットで学習を行うことができます。フレームのコレクション (ビデオ シーケンス) では、ネットワークの入力サイズに基づき、ビデオ データに対して同じ拡張を適用しなければなりません。平行移動、トリミング、変換などのわずかな変更をイメージに加えることで、ロバストなビデオ分類器の学習に使用できる特徴的な一意のイメージが新たに作成されます。データストアは、データの集合の読み取りや拡張に便利です。この例の終わりに定義されているサポート関数 augmentVideo を使用して、学習ビデオ データを拡張します。
dsTrain = transform(dsTrain, @augmentVideo);
前処理として、この例の終わりに定義されている preprocessVideoClips を使用し、I3D ビデオ分類器の入力サイズに合わせて学習ビデオ データのサイズを変更します。ビデオ分類器の InputNormalizationStatistics プロパティ、および前処理関数への入力のサイズを、struct preprocessInfo のフィールド値として指定します。InputNormalizationStatistics プロパティは、ビデオ フレームとオプティカル フロー データを -1 ~ 1 に再スケーリングするのに使用されます。入力サイズは、struct info の SizingOption の値に基づき、imresize を使用してビデオ フレームのサイズを変更するのに使用されます。あるいは、"randomcrop" または "centercrop" を使用して、ビデオ分類器の入力サイズに合わせて入力データをランダムにトリミングするか中央でトリミングできます。データ拡張は、テスト データと検証データには適用されないことに注意してください。理想的には、テスト データと検証データは元のデータを代表するもので、バイアスのない評価を行うために変更なしで使用されなければなりません。
preprocessInfo.Statistics = i3d.InputNormalizationStatistics;
preprocessInfo.InputSize = inputSize;
preprocessInfo.SizingOption = "resize";
dsTrain = transform(dsTrain, @(data)preprocessVideoClips(data, preprocessInfo));
dsVal = transform(dsVal, @(data)preprocessVideoClips(data, preprocessInfo));I3D ビデオ分類器の学習
この例のこの節では、転移学習を使用して前述のビデオ分類器に学習させる方法を示します。学習の完了を待つことなく事前学習済みのビデオ分類器を使用するには、変数 doTraining を false に設定します。一方、ビデオ分類器に学習させる場合は、変数 doTraining を true に設定します。
doTraining = false;
モデル勾配関数の定義
この例の最後にリストされているサポート関数 modelGradients を作成します。関数 modelGradients は、I3D ビデオ分類器 i3d、入力データ dlRGB および dlFlow のミニバッチ、グラウンド トゥルース ラベル データ dlY のミニバッチを入力として受け取ります。関数は、学習損失値、分類器の学習可能なパラメーターについての損失の勾配、および分類器のミニバッチの精度を返します。
損失は、各サブネットワークから得られる予測のクロスエントロピー損失の平均を求めることによって計算されます。ネットワークの出力予測は、各クラスについて 0 ~ 1 の確率となります。
各分類器の精度は、RGB およびオプティカル フローの予測の平均を受け取り、それを入力のグラウンド トゥルース ラベルと比較することによって計算されます。
学習オプションの指定
ミニバッチ サイズを 20、反復回数を 600 として学習させます。SaveBestAfterIteration パラメーターを使用し、最大の検証精度でビデオ分類器を保存するまでの反復回数を指定します。
コサインアニーリング学習率スケジュール [3] パラメーターを指定します。
最小学習率として 1e-4。
最大学習率として 1e-3。
学習率スケジュール サイクルが再開するまでのコサインの反復数として 100、200、300。オプション
CosineNumIterationsでは、各コサイン サイクルの幅を定義します。
SGDM 最適化のパラメーターを指定します。学習開始時に SGDM 最適化パラメーターを初期化します。
モーメンタムとして 0.9。
[]として初期化された初期速度パラメーター。L2 正則化係数として 0.0005。
並列プールを使用し、バックグラウンドでデータのディスパッチを実行するように指定します。DispatchInBackground が true に設定されている場合、並列ワーカーの指定された数で並列プールを開き、この例の一部として提供される DispatchInBackgroundDatastore を作成します。そして、非同期のデータの読み込みと前処理を使用して学習を高速化するために、バックグラウンドでデータのディスパッチを行います。既定では、この例は利用可能な GPU がある場合にそれを使用します。そうでない場合は CPU が使用されます。GPU を使用するには、Parallel Computing Toolbox™、および CUDA® 対応の NVIDIA® GPU が必要です。サポートされる Compute Capability の詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。
params.Classes = classes; params.MiniBatchSize = 20; params.NumIterations = 600; params.SaveBestAfterIteration = 400; params.CosineNumIterations = [100, 200, 300]; params.MinLearningRate = 1e-4; params.MaxLearningRate = 1e-3; params.Momentum = 0.9; params.VelocityRGB = []; params.VelocityFlow = []; params.L2Regularization = 0.0005; params.ProgressPlot = true; params.Verbose = true; params.ValidationData = dsVal; params.DispatchInBackground = false; params.NumWorkers = 4;
RGB ビデオ データとオプティカル フロー データを使用し、I3D ビデオ分類器に学習させます。
各エポックで次を行います。
データのミニバッチをループ処理する前にデータをシャッフルします。
minibatchqueueを使用してミニバッチをループ処理します。この例の最後にリストされているサポート関数createMiniBatchQueueは、指定された学習データストアを使用してminibatchqueueを作成します。検証データ
dsValを使用してネットワークを検証します。この例の最後にリストされているサポート関数
displayVerboseOutputEveryEpochを使用し、各エポックの損失と精度の結果を表示します。
各ミニバッチで次を行います。
ビデオ データまたはオプティカル フロー データとラベルを、基となる型が single の
dlarrayオブジェクトに変換します。I3D ビデオ分類器を使用してビデオ データの時間次元を処理できるようにするには、時間シーケンスの次元
"T"を指定します。ビデオ データに次元ラベル"SSCTB"(spatial、spatial、channel、temporal、batch) を指定し、ラベル データに"CB"を指定します。
minibatchqueue オブジェクトは、この例の最後にリストされているサポート関数 batchVideoAndFlow を使用し、RGB ビデオ データとオプティカル フロー データをバッチ処理します。
params.ModelFilename = "inflated3d-FiveClasses-hmdb51.mat"; if doTraining epoch = 1; bestLoss = realmax; accTrain = []; accTrainRGB = []; accTrainFlow = []; lossTrain = []; iteration = 1; start = tic; trainTime = start; shuffled = shuffleTrainDs(dsTrain); % Number of outputs is three: One for RGB frames, one for optical flow % data, and one for ground truth labels. numOutputs = 3; mbq = createMiniBatchQueue(shuffled, numOutputs, params); % Use the initializeTrainingProgressPlot and initializeVerboseOutput % supporting functions, listed at the end of the example, to initialize % the training progress plot and verbose output to display the training % loss, training accuracy, and validation accuracy. plotters = initializeTrainingProgressPlot(params); initializeVerboseOutput(params); while iteration <= params.NumIterations % Iterate through the data set. [dlVideo,dlFlow,dlY] = next(mbq); % Evaluate the model gradients and loss using dlfeval. [gradRGB,gradFlow,loss,acc,accRGB,accFlow,stateRGB,stateFlow] = ... dlfeval(@modelGradients,i3d,dlVideo,dlFlow,dlY); % Accumulate the loss and accuracies. lossTrain = [lossTrain, loss]; accTrain = [accTrain, acc]; accTrainRGB = [accTrainRGB, accRGB]; accTrainFlow = [accTrainFlow, accFlow]; % Update the network state. i3d.VideoState = stateRGB; i3d.OpticalFlowState = stateFlow; % Update the gradients and parameters for the RGB and optical flow % subnetworks using the SGDM optimizer. [i3d.VideoLearnables,params.VelocityRGB] = ... updateLearnables(i3d.VideoLearnables,gradRGB,params,params.VelocityRGB,iteration); [i3d.OpticalFlowLearnables,params.VelocityFlow,learnRate] = ... updateLearnables(i3d.OpticalFlowLearnables,gradFlow,params,params.VelocityFlow,iteration); if ~hasdata(mbq) || iteration == params.NumIterations % Current epoch is complete. Do validation and update progress. trainTime = toc(trainTime); [validationTime,cmat,lossValidation,accValidation,accValidationRGB,accValidationFlow] = ... doValidation(params, i3d); accTrain = mean(accTrain); accTrainRGB = mean(accTrainRGB); accTrainFlow = mean(accTrainFlow); lossTrain = mean(lossTrain); % Update the training progress. displayVerboseOutputEveryEpoch(params,start,learnRate,epoch,iteration,... accTrain,accTrainRGB,accTrainFlow,... accValidation,accValidationRGB,accValidationFlow,... lossTrain,lossValidation,trainTime,validationTime); updateProgressPlot(params,plotters,epoch,iteration,start,lossTrain,accTrain,accValidation); % Save the trained video classifier and the parameters, that gave % the best validation loss so far. Use the saveData supporting function, % listed at the end of this example. bestLoss = saveData(i3d,bestLoss,iteration,cmat,lossTrain,lossValidation,... accTrain,accValidation,params); end if ~hasdata(mbq) && iteration < params.NumIterations % Current epoch is complete. Initialize the training loss, accuracy % values, and minibatchqueue for the next epoch. accTrain = []; accTrainRGB = []; accTrainFlow = []; lossTrain = []; trainTime = tic; epoch = epoch + 1; shuffled = shuffleTrainDs(dsTrain); numOutputs = 3; mbq = createMiniBatchQueue(shuffled, numOutputs, params); end iteration = iteration + 1; end % Display a message when training is complete. endVerboseOutput(params); disp("Model saved to: " + params.ModelFilename); end
I3D ビデオ分類器の評価
テスト データ セットを使用し、学習済みのビデオ分類器の精度を評価します。
学習中に保存された最適なモデルを読み込むか、事前学習済みのモデルを使用します。
if doTraining transferLearned = load(params.ModelFilename); inflated3dPretrained = transferLearned.data.inflated3d; end
minibatchqueue オブジェクトを作成し、テスト データのバッチを読み込みます。
numOutputs = 3; mbq = createMiniBatchQueue(params.ValidationData, numOutputs, params);
テスト データの各バッチについて、RGB ネットワークとオプティカル フロー ネットワークを使用して予測を行い、予測の平均を求め、混同行列を使用して予測精度を計算します。
numClasses = numel(classes); cmat = sparse(numClasses,numClasses); while hasdata(mbq) [dlRGB, dlFlow, dlY] = next(mbq); % Pass the video input as RGB and optical flow data through the % two-stream I3D Video Classifier to get the separate predictions. [dlYPredRGB,dlYPredFlow] = predict(inflated3dPretrained,dlRGB,dlFlow); % Fuse the predictions by calculating the average of the predictions. dlYPred = (dlYPredRGB + dlYPredFlow)/2; % Calculate the accuracy of the predictions. [~,YTest] = max(dlY,[],1); [~,YPred] = max(dlYPred,[],1); cmat = aggregateConfusionMetric(cmat,YTest,YPred); end
学習済みのネットワークの平均分類精度を計算します。
accuracyEval = sum(diag(cmat))./sum(cmat,"all")accuracyEval = 0.8850
混同行列を表示します。
figure chart = confusionchart(cmat,classes);
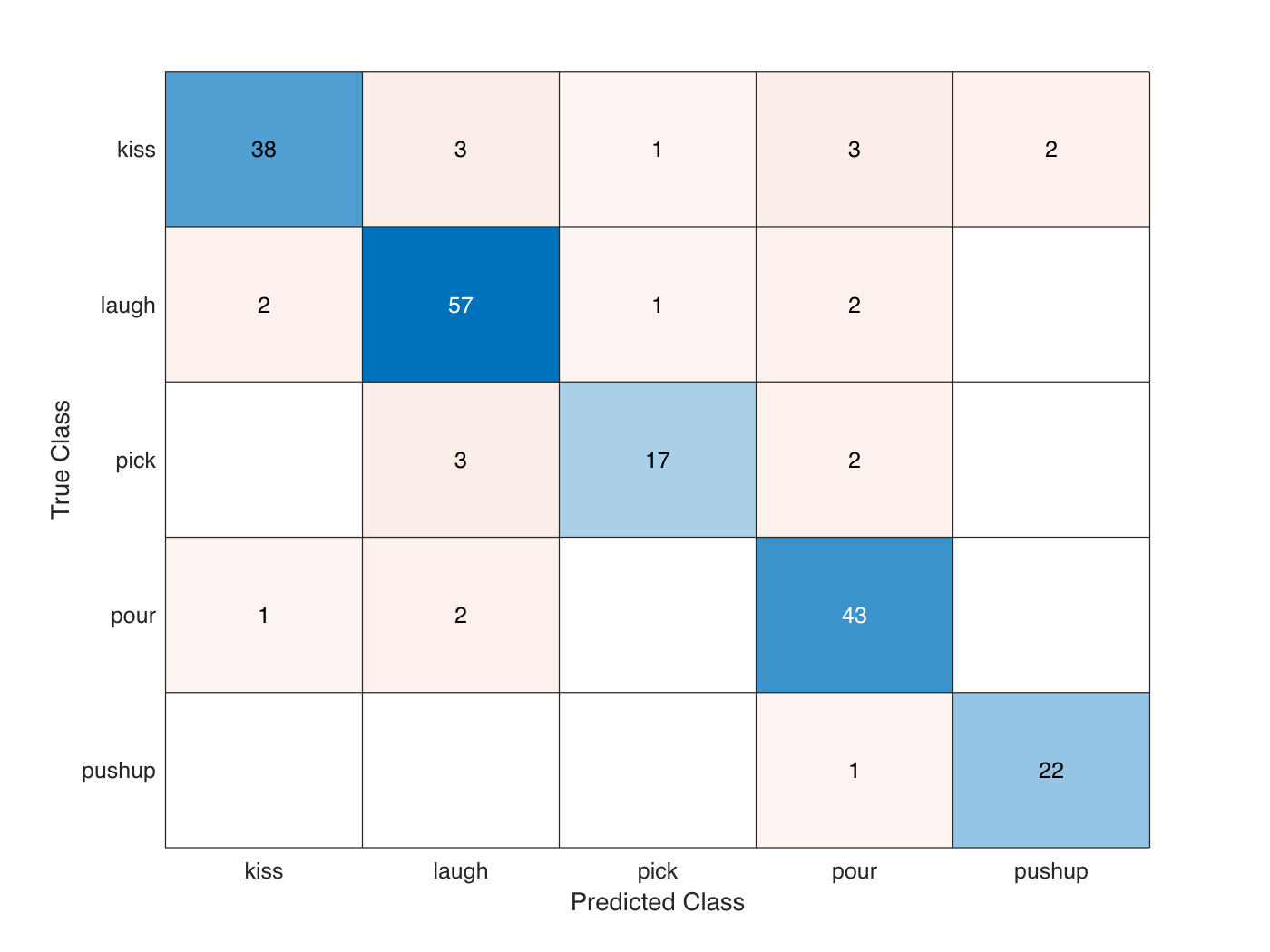
Kinetics-400 データセットで事前学習させた I3D ビデオ分類器は、転移学習を行うことで行動認識の性能が向上します。前述の学習は、24GB Titan-X GPU で約 100 分間実行されました。小規模なアクティビティ認識ビデオ データセットでゼロから学習させる場合、事前学習済みのビデオ分類器を使用する場合と比べて学習と収束により多くの時間がかかります。Kinetics-400 で事前学習させた I3D ビデオ分類器を使用して転移学習を行うと、実行エポック数が大きい場合の過適合を防ぐこともできます。ただし、Kinetics-400 データセットで事前学習させた SlowFast ビデオ分類器や R(2+1)D ビデオ分類器は、I3D ビデオ分類器と比べ、学習時の性能が高く、より短時間で収束します。深層学習を使用したビデオ認識の詳細については、Getting Started with Video Classification Using Deep Learningを参照してください。
サポート関数
inputStatistics
関数 inputStatistics は、HMDB51 データを格納するフォルダーの名前を入力として受け取り、RGB データとオプティカル フロー データの最小値と最大値を計算します。最小値と最大値は、ネットワークの入力層への正規化入力として使用されます。この関数は、ネットワークの学習中およびテスト中に、後で使用する各ビデオ ファイルのフレーム数も取得します。異なるデータ セットの最小値および最大値を見つけるには、データ セットを格納しているフォルダー名でこの関数を使用します。
function inputStats = inputStatistics(dataFolder) ds = createDatastore(dataFolder); ds.ReadFcn = @getMinMax; tic; tt = tall(ds); varnames = {'rgbMax','rgbMin','oflowMax','oflowMin'}; stats = gather(groupsummary(tt,[],{'max','min'}, varnames)); inputStats.Filename = gather(tt.Filename); inputStats.NumFrames = gather(tt.NumFrames); inputStats.rgbMax = stats.max_rgbMax; inputStats.rgbMin = stats.min_rgbMin; inputStats.oflowMax = stats.max_oflowMax; inputStats.oflowMin = stats.min_oflowMin; save('inputStatistics.mat','inputStats'); toc; end function data = getMinMax(filename) reader = VideoReader(filename); opticFlow = opticalFlowFarneback; data = []; while hasFrame(reader) frame = readFrame(reader); [rgb,oflow] = findMinMax(frame,opticFlow); data = assignMinMax(data, rgb, oflow); end totalFrames = floor(reader.Duration * reader.FrameRate); totalFrames = min(totalFrames, reader.NumFrames); [labelName, filename] = getLabelFilename(filename); data.Filename = fullfile(labelName, filename); data.NumFrames = totalFrames; data = struct2table(data,'AsArray',true); end function [labelName, filename] = getLabelFilename(filename) fileNameSplit = split(filename,'/'); labelName = fileNameSplit{end-1}; filename = fileNameSplit{end}; end function data = assignMinMax(data, rgb, oflow) if isempty(data) data.rgbMax = rgb.Max; data.rgbMin = rgb.Min; data.oflowMax = oflow.Max; data.oflowMin = oflow.Min; return; end data.rgbMax = max(data.rgbMax, rgb.Max); data.rgbMin = min(data.rgbMin, rgb.Min); data.oflowMax = max(data.oflowMax, oflow.Max); data.oflowMin = min(data.oflowMin, oflow.Min); end function [rgbMinMax,oflowMinMax] = findMinMax(rgb, opticFlow) rgbMinMax.Max = max(rgb,[],[1,2]); rgbMinMax.Min = min(rgb,[],[1,2]); gray = rgb2gray(rgb); flow = estimateFlow(opticFlow,gray); oflow = cat(3,flow.Vx,flow.Vy,flow.Magnitude); oflowMinMax.Max = max(oflow,[],[1,2]); oflowMinMax.Min = min(oflow,[],[1,2]); end function ds = createDatastore(folder) ds = fileDatastore(folder,... 'IncludeSubfolders', true,... 'FileExtensions', '.avi',... 'UniformRead', true,... 'ReadFcn', @getMinMax); disp("NumFiles: " + numel(ds.Files)); end
createFileDatastore
関数 createFileDatastore は、指定されたファイル名を使用して FileDatastore オブジェクトを作成します。FileDatastore オブジェクトは 'partialfile' モードでデータを読み取るため、すべての読み取りにおいてビデオから部分的に読み取ったフレームを返すことができます。この特徴は、大きなビデオ ファイルの読み取りで、フレームのすべてをメモリに取り込めない場合に役立ちます。
function datastore = createFileDatastore(trainingFolder,numFrames,numChannels,classes,isDataForTraining) readFcn = @(f,u)readVideo(f,u,numFrames,numChannels,classes,isDataForTraining); datastore = fileDatastore(trainingFolder,... 'IncludeSubfolders',true,... 'FileExtensions','.avi',... 'ReadFcn',readFcn,... 'ReadMode','partialfile'); end
shuffleTrainDs
関数 shuffleTrainDs は、学習データストア dsTrain に存在するファイルをシャッフルします。
function shuffled = shuffleTrainDs(dsTrain) shuffled = copy(dsTrain); transformed = isa(shuffled, 'matlab.io.datastore.TransformedDatastore'); if transformed files = shuffled.UnderlyingDatastores{1}.Files; else files = shuffled.Files; end n = numel(files); shuffledIndices = randperm(n); if transformed shuffled.UnderlyingDatastores{1}.Files = files(shuffledIndices); else shuffled.Files = files(shuffledIndices); end reset(shuffled); end
readVideo
関数 readVideo は、ビデオ フレーム、および指定されたビデオ ファイルの対応するラベル値を読み取ります。学習中、読み取り関数は、ランダムに選択された開始フレームを使用し、ネットワークの入力サイズに従って特定の数のフレームを読み取ります。テスト中、すべてのフレームは順番に読み取られます。ビデオ フレームは、学習用、テスト用、および検証用に、分類器ネットワークで必要とされる入力サイズになるようにサイズが変更されます。
function [data,userdata,done] = readVideo(filename,userdata,numFrames,numChannels,classes,isDataForTraining) if isempty(userdata) userdata.reader = VideoReader(filename); userdata.batchesRead = 0; userdata.label = getLabel(filename,classes); totalFrames = floor(userdata.reader.Duration * userdata.reader.FrameRate); totalFrames = min(totalFrames, userdata.reader.NumFrames); userdata.totalFrames = totalFrames; userdata.datatype = class(read(userdata.reader,1)); end reader = userdata.reader; totalFrames = userdata.totalFrames; label = userdata.label; batchesRead = userdata.batchesRead; if isDataForTraining video = readForTraining(reader, numFrames, totalFrames); else video = readForValidation(reader, userdata.datatype, numChannels, numFrames, totalFrames); end data = {video, label}; batchesRead = batchesRead + 1; userdata.batchesRead = batchesRead; if numFrames > totalFrames numBatches = 1; else numBatches = floor(totalFrames/numFrames); end % Set the done flag to true, if the reader has read all the frames or % if it is training. done = batchesRead == numBatches || isDataForTraining; end
readForTraining
関数 readForTraining は、ビデオ分類器の学習に使用するビデオ フレームを読み取ります。この関数は、ランダムに選択された開始フレームを使用し、ネットワークの入力サイズに従って特定の数のフレームを読み取ります。十分なフレームが残っていない場合、必要なフレーム数となるようにビデオ シーケンスが繰り返されます。
function video = readForTraining(reader, numFrames, totalFrames) if numFrames >= totalFrames startIdx = 1; endIdx = totalFrames; else startIdx = randperm(totalFrames - numFrames + 1); startIdx = startIdx(1); endIdx = startIdx + numFrames - 1; end video = read(reader,[startIdx,endIdx]); if numFrames > totalFrames % Add more frames to fill in the network input size. additional = ceil(numFrames/totalFrames); video = repmat(video,1,1,1,additional); video = video(:,:,:,1:numFrames); end end
readForValidation
関数 readForValidation は、学習済みビデオ分類器の評価に使用するビデオ フレームを読み取ります。この関数は、ネットワークの入力サイズに従って特定の数のフレームを順番に読み取ります。十分なフレームが残っていない場合、必要なフレーム数となるようにビデオ シーケンスが繰り返されます。
function video = readForValidation(reader, datatype, numChannels, numFrames, totalFrames) H = reader.Height; W = reader.Width; toRead = min([numFrames,totalFrames]); video = zeros([H,W,numChannels,toRead], datatype); frameIndex = 0; while hasFrame(reader) && frameIndex < numFrames frame = readFrame(reader); frameIndex = frameIndex + 1; video(:,:,:,frameIndex) = frame; end if frameIndex < numFrames video = video(:,:,:,1:frameIndex); additional = ceil(numFrames/frameIndex); video = repmat(video,1,1,1,additional); video = video(:,:,:,1:numFrames); end end
getLabel
関数 getLabel は、ファイル名の絶対パスからラベル名を取得します。ファイルのラベルは、そのファイルが存在するフォルダーです。たとえば、ファイル パスが "/path/to/dataset/clapping/video_0001.avi" である場合、ラベル名は "clapping" となります。
function label = getLabel(filename,classes) folder = fileparts(string(filename)); [~,label] = fileparts(folder); label = categorical(string(label), string(classes)); end
augmentVideo
関数 augmentVideo は、サポート関数 augmentTransform によって提供される拡張変換関数を使用して、ビデオ シーケンス全体に同じ拡張を適用します。
function data = augmentVideo(data) numSequences = size(data,1); for ii = 1:numSequences video = data{ii,1}; % HxWxC sz = size(video,[1,2,3]); % One augmentation per sequence augmentFcn = augmentTransform(sz); data{ii,1} = augmentFcn(video); end end
augmentTransform
関数 augmentTransform は、ランダムな左右反転係数とスケーリング係数を使った拡張方法を作成します。
function augmentFcn = augmentTransform(sz) % Randomly flip and scale the image. tform = randomAffine2d('XReflection',true,'Scale',[1 1.1]); rout = affineOutputView(sz,tform,'BoundsStyle','CenterOutput'); augmentFcn = @(data)augmentData(data,tform,rout); function data = augmentData(data,tform,rout) data = imwarp(data,tform,'OutputView',rout); end end
preprocessVideoClips
関数 preprocessVideoClips は、前処理として、I3D ビデオ分類器の入力サイズに合わせて学習ビデオ データのサイズを変更します。これは、struct info に含まれるビデオ分類器の InputNormalizationStatistics プロパティと InputSize プロパティを受け取ります。InputNormalizationStatistics プロパティは、ビデオ フレームとオプティカル フロー データを -1 ~ 1 に再スケーリングするのに使用されます。入力サイズは、struct info の SizingOption の値に基づき、imresize を使用してビデオ フレームのサイズを変更するのに使用されます。あるいは、"randomcrop" または "centercrop" を SizingOption の値として使用して、ビデオ分類器の入力サイズに合わせて入力データをランダムにトリミングするか中央でトリミングできます。
function preprocessed = preprocessVideoClips(data, info) inputSize = info.InputSize(1:2); sizingOption = info.SizingOption; switch sizingOption case "resize" sizingFcn = @(x)imresize(x,inputSize); case "randomcrop" sizingFcn = @(x)cropVideo(x,@randomCropWindow2d,inputSize); case "centercrop" sizingFcn = @(x)cropVideo(x,@centerCropWindow2d,inputSize); end numClips = size(data,1); rgbMin = info.Statistics.Video.Min; rgbMax = info.Statistics.Video.Max; oflowMin = info.Statistics.OpticalFlow.Min; oflowMax = info.Statistics.OpticalFlow.Max; numChannels = length(rgbMin); rgbMin = reshape(rgbMin, 1, 1, numChannels); rgbMax = reshape(rgbMax, 1, 1, numChannels); numChannels = length(oflowMin); oflowMin = reshape(oflowMin, 1, 1, numChannels); oflowMax = reshape(oflowMax, 1, 1, numChannels); preprocessed = cell(numClips, 3); for ii = 1:numClips video = data{ii,1}; resized = sizingFcn(video); oflow = computeFlow(resized,inputSize); % Cast the input to single. resized = single(resized); oflow = single(oflow); % Rescale the input between -1 and 1. resized = rescale(resized,-1,1,"InputMin",rgbMin,"InputMax",rgbMax); oflow = rescale(oflow,-1,1,"InputMin",oflowMin,"InputMax",oflowMax); preprocessed{ii,1} = resized; preprocessed{ii,2} = oflow; preprocessed{ii,3} = data{ii,2}; end end function outData = cropVideo(data, cropFcn, inputSize) imsz = size(data,[1,2]); cropWindow = cropFcn(imsz, inputSize); numFrames = size(data,4); sz = [inputSize, size(data,3), numFrames]; outData = zeros(sz, 'like', data); for f = 1:numFrames outData(:,:,:,f) = imcrop(data(:,:,:,f), cropWindow); end end
computeFlow
関数 computeFlow は、入力としてビデオ シーケンス videoFrames を受け取り、opticalFlowFarneback を使用して対応するオプティカル フロー データ opticalFlowData を計算します。オプティカル フロー データには、速度の 成分と 成分に対応する 2 つのチャネルが含まれています。
function opticalFlowData = computeFlow(videoFrames, inputSize) opticalFlow = opticalFlowFarneback; numFrames = size(videoFrames,4); sz = [inputSize, 2, numFrames]; opticalFlowData = zeros(sz, 'like', videoFrames); for f = 1:numFrames gray = rgb2gray(videoFrames(:,:,:,f)); flow = estimateFlow(opticalFlow,gray); opticalFlowData(:,:,:,f) = cat(3,flow.Vx,flow.Vy); end end
createMiniBatchQueue
関数 createMiniBatchQueue は、指定されたデータストアからのデータ量 miniBatchSize を提供する minibatchqueue オブジェクトを作成します。また、並列プールが開いている場合は、DispatchInBackgroundDatastore も作成します。
function mbq = createMiniBatchQueue(datastore, numOutputs, params) if params.DispatchInBackground && isempty(gcp('nocreate')) % Start a parallel pool, if DispatchInBackground is true, to dispatch % data in the background using the parallel pool. c = parcluster('local'); c.NumWorkers = params.NumWorkers; parpool('local',params.NumWorkers); end p = gcp('nocreate'); if ~isempty(p) datastore = DispatchInBackgroundDatastore(datastore, p.NumWorkers); end inputFormat(1:numOutputs-1) = "SSCTB"; outputFormat = "CB"; mbq = minibatchqueue(datastore, numOutputs, ... "MiniBatchSize", params.MiniBatchSize, ... "MiniBatchFcn", @batchVideoAndFlow, ... "MiniBatchFormat", [inputFormat,outputFormat]); end
batchVideoAndFlow
関数 batchVideoAndFlow は、cell 配列から取得したビデオ データ、オプティカル フロー データ、およびラベル データをバッチ処理します。これは、関数 onehotencode 使用して、グラウンド トゥルース カテゴリカル ラベルを one-hot 配列に符号化します。one-hot 符号化された配列では、ラベルのクラスに対応する位置に 1 が格納され、その他のすべての位置に 0 が格納されます。
function [video,flow,labels] = batchVideoAndFlow(video, flow, labels) % Batch dimension: 5 video = cat(5,video{:}); flow = cat(5,flow{:}); % Batch dimension: 2 labels = cat(2,labels{:}); % Feature dimension: 1 labels = onehotencode(labels,1); end
modelGradients
関数 modelGradients は、RGB データ dlRGB のミニバッチ、対応するオプティカル フロー データ dlFlow、および対応するターゲット dlY を入力として受け取り、対応する損失、学習可能なパラメーターについての損失の勾配、および学習精度を返します。勾配を計算するため、学習ループの中で関数 dlfeval を使用して、関数 modelGradients を評価します。
function [gradientsRGB,gradientsFlow,loss,acc,accRGB,accFlow,stateRGB,stateFlow] = modelGradients(i3d,dlRGB,dlFlow,Y) % Pass video input as RGB and optical flow data through the two-stream % network. [dlYPredRGB,dlYPredFlow,stateRGB,stateFlow] = forward(i3d,dlRGB,dlFlow); % Calculate fused loss, gradients, and accuracy for the two-stream % predictions. rgbLoss = crossentropy(dlYPredRGB,Y); flowLoss = crossentropy(dlYPredFlow,Y); % Fuse the losses. loss = mean([rgbLoss,flowLoss]); gradientsRGB = dlgradient(rgbLoss,i3d.VideoLearnables); gradientsFlow = dlgradient(flowLoss,i3d.OpticalFlowLearnables); % Fuse the predictions by calculating the average of the predictions. dlYPred = (dlYPredRGB + dlYPredFlow)/2; % Calculate the accuracy of the predictions. [~,YTest] = max(Y,[],1); [~,YPred] = max(dlYPred,[],1); acc = gather(extractdata(sum(YTest == YPred)./numel(YTest))); % Calculate the accuracy of the RGB and flow predictions. [~,YTest] = max(Y,[],1); [~,YPredRGB] = max(dlYPredRGB,[],1); [~,YPredFlow] = max(dlYPredFlow,[],1); accRGB = gather(extractdata(sum(YTest == YPredRGB)./numel(YTest))); accFlow = gather(extractdata(sum(YTest == YPredFlow)./numel(YTest))); end
updateLearnables
関数 updateLearnables は、SGDM 最適化関数 sgdmupdate を使用して、勾配およびその他のパラメーターと共に、指定された learnables を更新します。
function [learnables,velocity,learnRate] = updateLearnables(learnables,gradients,params,velocity,iteration) % Determine the learning rate using the cosine-annealing learning rate schedule. learnRate = cosineAnnealingLearnRate(iteration, params); % Apply L2 regularization to the weights. idx = learnables.Parameter == "Weights"; gradients(idx,:) = dlupdate(@(g,w) g + params.L2Regularization*w, gradients(idx,:), learnables(idx,:)); % Update the network parameters using the SGDM optimizer. [learnables, velocity] = sgdmupdate(learnables, gradients, velocity, learnRate, params.Momentum); end
cosineAnnealingLearnRate
関数 cosineAnnealingLearnRate は、現在の反復回数、最小学習率、最大学習率、およびアニーリングの反復回数に基づいて学習率を計算します [3]。
function lr = cosineAnnealingLearnRate(iteration, params) if iteration == params.NumIterations lr = params.MinLearningRate; return; end cosineNumIter = [0, params.CosineNumIterations]; csum = cumsum(cosineNumIter); block = find(csum >= iteration, 1,'first'); cosineIter = iteration - csum(block - 1); annealingIteration = mod(cosineIter, cosineNumIter(block)); cosineIteration = cosineNumIter(block); minR = params.MinLearningRate; maxR = params.MaxLearningRate; cosMult = 1 + cos(pi * annealingIteration / cosineIteration); lr = minR + ((maxR - minR) * cosMult / 2); end
aggregateConfusionMetric
関数 aggregateConfusionMetric は、予測される結果 YPred と期待される結果 YTest をインクリメンタルに混同行列に追加します。
function cmat = aggregateConfusionMetric(cmat,YTest,YPred) YTest = gather(extractdata(YTest)); YPred = gather(extractdata(YPred)); [m,n] = size(cmat); cmat = cmat + full(sparse(YTest,YPred,1,m,n)); end
doValidation
関数 doValidation は、検証データを使用してビデオ分類器を検証します。
function [validationTime, cmat, lossValidation, accValidation, accValidationRGB, accValidationFlow] = doValidation(params, i3d) validationTime = tic; numOutputs = 3; mbq = createMiniBatchQueue(params.ValidationData, numOutputs, params); lossValidation = []; numClasses = numel(params.Classes); cmat = sparse(numClasses,numClasses); cmatRGB = sparse(numClasses,numClasses); cmatFlow = sparse(numClasses,numClasses); while hasdata(mbq) [dlX1,dlX2,dlY] = next(mbq); [loss,YTest,YPred,YPredRGB,YPredFlow] = predictValidation(i3d,dlX1,dlX2,dlY); lossValidation = [lossValidation,loss]; cmat = aggregateConfusionMetric(cmat,YTest,YPred); cmatRGB = aggregateConfusionMetric(cmatRGB,YTest,YPredRGB); cmatFlow = aggregateConfusionMetric(cmatFlow,YTest,YPredFlow); end lossValidation = mean(lossValidation); accValidation = sum(diag(cmat))./sum(cmat,"all"); accValidationRGB = sum(diag(cmatRGB))./sum(cmatRGB,"all"); accValidationFlow = sum(diag(cmatFlow))./sum(cmatFlow,"all"); validationTime = toc(validationTime); end
predictValidation
関数 predictValidation は、RGB データとオプティカル フロー データに対して、指定されたビデオ分類器を使用して損失と予測値を計算します。
function [loss,YTest,YPred,YPredRGB,YPredFlow] = predictValidation(i3d,dlRGB,dlFlow,Y) % Pass the video input through the two-stream Inflated-3D video classifier. [dlYPredRGB,dlYPredFlow] = predict(i3d,dlRGB,dlFlow); % Calculate the cross-entropy separately for the two-stream outputs. rgbLoss = crossentropy(dlYPredRGB,Y); flowLoss = crossentropy(dlYPredFlow,Y); % Fuse the losses. loss = mean([rgbLoss,flowLoss]); % Fuse the predictions by calculating the average of the predictions. dlYPred = (dlYPredRGB + dlYPredFlow)/2; % Calculate the accuracy of the predictions. [~,YTest] = max(Y,[],1); [~,YPred] = max(dlYPred,[],1); [~,YPredRGB] = max(dlYPredRGB,[],1); [~,YPredFlow] = max(dlYPredFlow,[],1); end
saveData
関数 saveData は、指定された Inflated-3d ビデオ分類器、精度、損失、およびその他の学習パラメーターを MAT ファイルに保存します。
function bestLoss = saveData(inflated3d,bestLoss,iteration,cmat,lossTrain,lossValidation,... accTrain,accValidation,params) if iteration >= params.SaveBestAfterIteration lossValidtion = extractdata(gather(lossValidation)); if lossValidtion < bestLoss params = rmfield(params, 'VelocityRGB'); params = rmfield(params, 'VelocityFlow'); bestLoss = lossValidtion; inflated3d = gatherFromGPUToSave(inflated3d); data.BestLoss = bestLoss; data.TrainingLoss = extractdata(gather(lossTrain)); data.TrainingAccuracy = accTrain; data.ValidationAccuracy = accValidation; data.ValidationConfmat= cmat; data.inflated3d = inflated3d; data.Params = params; save(params.ModelFilename, 'data'); end end end
gatherFromGPUToSave
関数 gatherFromGPUToSave は、ビデオ分類器をディスクに保存するために GPU からデータを収集します。
function classifier = gatherFromGPUToSave(classifier) if ~canUseGPU return; end p = string(properties(classifier)); p = p(endsWith(p, ["Learnables","State"])); for jj = 1:numel(p) prop = p(jj); classifier.(prop) = gatherValues(classifier.(prop)); end function tbl = gatherValues(tbl) for ii = 1:height(tbl) tbl.Value{ii} = gather(tbl.Value{ii}); end end end
checkForHMDB51Folder
関数 checkForHMDB51Folder は、ダウンロード フォルダーにあるダウンロード済みのデータをチェックします。
function classes = checkForHMDB51Folder(dataLoc) hmdbFolder = fullfile(dataLoc, "hmdb51_org"); if ~isfolder(hmdbFolder) error("Download 'hmdb51_org.rar' file from https://serre.lab.brown.edu/hmdb51.html before running the example and extract the RAR file."); end classes = ["brush_hair","cartwheel","catch","chew","clap","climb","climb_stairs",... "dive","draw_sword","dribble","drink","eat","fall_floor","fencing",... "flic_flac","golf","handstand","hit","hug","jump","kick","kick_ball",... "kiss","laugh","pick","pour","pullup","punch","push","pushup","ride_bike",... "ride_horse","run","shake_hands","shoot_ball","shoot_bow","shoot_gun",... "sit","situp","smile","smoke","somersault","stand","swing_baseball","sword",... "sword_exercise","talk","throw","turn","walk","wave"]; expectFolders = fullfile(hmdbFolder, classes); if ~all(arrayfun(@(x)exist(x,'dir'),expectFolders)) error("Download hmdb51_org.rar using the supporting function 'downloadHMDB51' before running the example and extract the RAR file."); end end
initializeTrainingProgressPlot
関数 initializeTrainingProgressPlot は、学習損失、学習精度、および検証精度を表示する 2 つのプロットを構成します。
function plotters = initializeTrainingProgressPlot(params) if params.ProgressPlot % Plot the loss, training accuracy, and validation accuracy. figure % Loss plot subplot(2,1,1) plotters.LossPlotter = animatedline; xlabel("Iteration") ylabel("Loss") % Accuracy plot subplot(2,1,2) plotters.TrainAccPlotter = animatedline('Color','b'); plotters.ValAccPlotter = animatedline('Color','g'); legend('Training Accuracy','Validation Accuracy','Location','northwest'); xlabel("Iteration") ylabel("Accuracy") else plotters = []; end end
updateProgressPlot
関数 updateProgressPlot は、学習中の損失と精度の情報で進行状況プロットを更新します。
function updateProgressPlot(params,plotters,epoch,iteration,start,lossTrain,accuracyTrain,accuracyValidation) if params.ProgressPlot % Update the training progress. D = duration(0,0,toc(start),"Format","hh:mm:ss"); title(plotters.LossPlotter.Parent,"Epoch: " + epoch + ", Elapsed: " + string(D)); addpoints(plotters.LossPlotter,iteration,double(gather(extractdata(lossTrain)))); addpoints(plotters.TrainAccPlotter,iteration,accuracyTrain); addpoints(plotters.ValAccPlotter,iteration,accuracyValidation); drawnow end end
initializeVerboseOutput
関数 initializeVerboseOutput は、学習値のテーブルの列見出しを表示します。列見出しは、エポック、ミニバッチ精度、その他の学習値を示します。
function initializeVerboseOutput(params) if params.Verbose disp(" ") if canUseGPU disp("Training on GPU.") else disp("Training on CPU.") end p = gcp('nocreate'); if ~isempty(p) disp("Training on parallel cluster '" + p.Cluster.Profile + "'. ") end disp("NumIterations:" + string(params.NumIterations)); disp("MiniBatchSize:" + string(params.MiniBatchSize)); disp("Classes:" + join(string(params.Classes), ",")); disp("|=======================================================================================================================================================================|") disp("| Epoch | Iteration | Time Elapsed | Mini-Batch Accuracy | Validation Accuracy | Mini-Batch | Validation | Base Learning | Train Time | Validation Time |") disp("| | | (hh:mm:ss) | (Avg:RGB:Flow) | (Avg:RGB:Flow) | Loss | Loss | Rate | (hh:mm:ss) | (hh:mm:ss) |") disp("|=======================================================================================================================================================================|") end end
displayVerboseOutputEveryEpoch
関数 displayVerboseOutputEveryEpoch は、エポック、ミニバッチ精度、検証精度、ミニバッチ損失など、学習値の詳細出力を表示します。
function displayVerboseOutputEveryEpoch(params,start,learnRate,epoch,iteration,... accTrain,accTrainRGB,accTrainFlow,accValidation,accValidationRGB,accValidationFlow,lossTrain,lossValidation,trainTime,validationTime) if params.Verbose D = duration(0,0,toc(start),'Format','hh:mm:ss'); trainTime = duration(0,0,trainTime,'Format','hh:mm:ss'); validationTime = duration(0,0,validationTime,'Format','hh:mm:ss'); lossValidation = gather(extractdata(lossValidation)); lossValidation = compose('%.4f',lossValidation); accValidation = composePadAccuracy(accValidation); accValidationRGB = composePadAccuracy(accValidationRGB); accValidationFlow = composePadAccuracy(accValidationFlow); accVal = join([accValidation,accValidationRGB,accValidationFlow], " : "); lossTrain = gather(extractdata(lossTrain)); lossTrain = compose('%.4f',lossTrain); accTrain = composePadAccuracy(accTrain); accTrainRGB = composePadAccuracy(accTrainRGB); accTrainFlow = composePadAccuracy(accTrainFlow); accTrain = join([accTrain,accTrainRGB,accTrainFlow], " : "); learnRate = compose('%.13f',learnRate); disp("| " + ... pad(string(epoch),5,'both') + " | " + ... pad(string(iteration),9,'both') + " | " + ... pad(string(D),12,'both') + " | " + ... pad(string(accTrain),26,'both') + " | " + ... pad(string(accVal),26,'both') + " | " + ... pad(string(lossTrain),10,'both') + " | " + ... pad(string(lossValidation),10,'both') + " | " + ... pad(string(learnRate),13,'both') + " | " + ... pad(string(trainTime),10,'both') + " | " + ... pad(string(validationTime),15,'both') + " |") end function acc = composePadAccuracy(acc) acc = compose('%.2f',acc*100) + "%"; acc = pad(string(acc),6,'left'); end end
endVerboseOutput
関数 endVerboseOutput は、学習中の詳細出力の末尾を表示します。
function endVerboseOutput(params) if params.Verbose disp("|=======================================================================================================================================================================|") end end
参考文献
[1] Carreira, Joao, and Andrew Zisserman. "Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR): 6299??6308.Honolulu, HI: IEEE, 2017.
[2] Simonyan, Karen, and Andrew Zisserman. "Two-Stream Convolutional Networks for Action Recognition in Videos." Advances in Neural Information Processing Systems 27, Long Beach, CA: NIPS, 2017.
[3] Loshchilov, Ilya, and Frank Hutter. "SGDR: Stochastic Gradient Descent with Warm Restarts." International Conferencee on Learning Representations 2017. Toulon, France: ICLR, 2017.
[4] Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, Manohar Paluri."A Closer Look at Spatiotemporal Convolutions for Action Recognition".Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 6450-6459.
[5] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He."SlowFast Networks for Video Recognition."Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
[6] Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, Andrew Zisserman."The Kinetics Human Action Video Dataset." arXiv preprint arXiv:1705.06950, 2017.