Gesture Recognition using Videos and Deep Learning
This example first shows how to perform gesture recognition using a pretrained SlowFast [1] video classifier and then shows how to use transfer learning to train a classifier on a custom gesture recognition data set.
Overview
Vision-based human gesture recognition involves predicting a gesture, such as waving hello, sign language gestures, or clapping, using a set of video frames. One of the appealing features of gesture recognition is that they make it possible for humans to communicate with computers and devices without the need for an external input equipment such as a mouse or a remote control. Gesture recognition from videos has many applications, such as control of consumer electronics and mechanical systems, robot learning, and computer games. For example, online prediction of multiple actions for incoming videos from multiple cameras can be important for robot learning. Compared to image classification, human gesture recognition using videos is challenging to model because of the inaccurate ground truth data for video data sets, the variety of gestures that actors in a video can perform, the heavily class imbalanced data sets, and the large amount of data required to train a robust classifier from scratch. Deep learning techniques, such as SlowFast two pathway convolutional networks [1], have shown improved performance on smaller data sets using transfer learning with networks pretrained on large video activity recognition data sets.
This example requires the Computer Vision Toolbox™ Model for SlowFast Video Classification. You can install the Computer Vision Toolbox Model for SlowFast Video Classification from Add-On Explorer. For more information about installing add-ons, see Get and Manage Add-Ons.
Load Pretrained SlowFast Video Classifier
Download the pretrained SlowFast video classifier along with a video file on which to perform gesture recognition. The size of the downloaded zip file is around 245 MB.
downloadFolder = fullfile(tempdir,"gesture"); if ~isfolder(downloadFolder) mkdir(downloadFolder); end zipFile = "slowFastPretrained_fourClasses.zip"; if ~isfile(fullfile(downloadFolder,zipFile)) disp('Downloading the pretrained network...'); downloadURL = "https://ssd.mathworks.com/supportfiles/vision/data/" + zipFile; zipFile = fullfile(downloadFolder,zipFile); websave(zipFile,downloadURL); unzip(zipFile,downloadFolder); disp("Downloaded.") end
Downloading the pretrained network...
Downloaded.
Load the pretrained SlowFast video classifier.
pretrainedDataFile = fullfile(downloadFolder,"slowFastPretrained_fourClasses.mat");
pretrained = load(pretrainedDataFile);
slowFastClassifier = pretrained.data.slowFast;Classify Gestures in a Video Sequence
Display the class label names of the pretrained video classifier.
classes = slowFastClassifier.Classes
classes = 4×1 categorical array
"clapping"
"noAction"
"somethingElse"
"wavingHello"
Read and display the video waving-hello.avi using VideoReader and vision.VideoPlayer.
videoFilename = fullfile(downloadFolder,"waving-hello.avi"); videoReader = VideoReader(videoFilename); videoPlayer = vision.VideoPlayer; videoPlayer.Name = "waving-hello"; while hasFrame(videoReader) frame = readFrame(videoReader); step(videoPlayer,frame); end release(videoPlayer);
Choose 10 randomly selected video sequences to classify the video, to uniformly cover the entirety of the file to find the action class that is predominant in the video.
numSequences = 10;
Classify the video file using the classifyVideoFile function.
[gestureLabel,score] = classifyVideoFile(slowFastClassifier,videoFilename,NumSequences=numSequences)
gestureLabel = categorical
wavingHello
score = single
0.4753
The classification can also be applied to a streaming video. To learn how to classify a streaming webcam video, see Classify Streaming Webcam Video Using SlowFast Video Classifier.
Load Training Data
This example trains a SlowFast video classification network using downloadable gesture data set that contains four gestures: "clapping","wavingHello","somethingElse", and "noAction". The data set contains videos that are labeled using a Video Labeler and the corresponding ground truth data.
Create directories to store the ground truth training data.
groundTruthFolder = fullfile(downloadFolder,"groundTruthFolder"); if ~isfolder(groundTruthFolder) mkdir(groundTruthFolder); end
Download the data set and extract the zip archive into the downloadFolder.
zipFile = 'videoClipsAndSceneLabels.zip'; if ~isfile(fullfile(groundTruthFolder,zipFile)) disp('Downloading the ground truth training data...'); downloadURL = "https://ssd.mathworks.com/supportfiles/vision/data/" + zipFile; zipFile = fullfile(groundTruthFolder,zipFile); websave(zipFile,downloadURL); unzip(zipFile,groundTruthFolder); end
Extract Training Video Sequences
To train a video classifier, you need a collection of videos and its corresponding collection of scene labels. Use the helper function extractVideoScenes, defined at the end of this example, to extract labeled video scenes from the ground truth data and write them to disk as separate video files. To learn more about extracting training data from videos, see Extract Training Data for Video Classification.
groundTruthFolder = fullfile(downloadFolder,"groundTruthFolder"); trainingFolder = fullfile(downloadFolder,"videoScenes"); extractVideoScenes(groundTruthFolder,trainingFolder,classes);
A total of 40 video scenes are extracted from the downloaded ground truth data.
Load Data Set
This example uses a datastore to read the videos scenes and labels extracted from the ground truth data.
Specify the number of video frames the datastore should be configured to output for each time data is read from the datastore.
numFrames = 16;
A value of 16 is used here to balance memory usage and classification time. Common values to consider are 8, 16, 32, 64, or 128. Using more frames helps capture additional temporal information, but requires more memory. Empirical analysis is required to determine the optimal number of frames.
Next, specify the height and width of the frames the datastore should be configured to output. The datastore automatically resizes the raw video frames to the specified size to enable batch processing of multiple video sequences.
frameSize = [112,112];
A value of [112 112] is used to capture longer temporal relationships in the video scene which help classify gestures with long time durations. Common values for the size are [112 112], [224 224], or [256 256]. Smaller sizes enable the use of more video frames at the cost of memory usage, processing time, and spatial resolution. As with the number of frames, empirical analysis is required to determine the optimal values.
Specify the number of channels as 3, as the videos are RGB.
numChannels = 3;
Use the helper function, createFileDatastore, to configure a FileDatastore for loading the data. The helper function is listed at the end of this example.
isDataForTraining = true; dsTrain = createFileDatastore(trainingFolder,numFrames,numChannels,classes,isDataForTraining);
Configure SlowFast Video Classifier
Create a SlowFast video classifier for transfer learning by using the slowFastVideoClassifier function. The slowFastVideoClassifier function creates a SlowFast video classifier object that is pretrained on the Kinetics-400 data set [2].
Specify ResNet-50 as the base network convolution neural network 3D architecture for the SlowFast classifier.
baseNetwork = "resnet50-3d";Specify the input size for the SlowFast video classifier.
inputSize = [frameSize,numChannels,numFrames];
Create a SlowFast video classifier by specifying the classes for the gesture data set and the network input size.
slowFast = slowFastVideoClassifier(baseNetwork,string(classes),InputSize=inputSize);
Specify a model name for the video classifier.
slowFast.ModelName = "Gesture Recognizer Using Deep Learning";Prepare Data for Training
Data augmentation provides a way to use limited data sets for training. Augmentation on video data must be the same for a collection of frames based on the network input size. Minor changes, such as translation, cropping, or transforming an image, provide, new, distinct, and unique images that you can use to train a robust video classifier. Datastores are a convenient way to read and augment collections of data. Augment the training video data by using the augmentVideo supporting function, defined at the end of this example.
dsTrain = transform(dsTrain,@augmentVideo);
Preprocess the training video data to resize to the SlowFast video classifier input size, by using the preprocessVideoClips, defined at the end of this example. Specify the InputNormalizationStatistics property of the video classifier and input size to the preprocessing function as field values in a struct, preprocessInfo. The InputNormalizationStatistics property is used to rescale the video frames between 0 and 1, and then normalize the rescaled data using mean and standard deviation. The input size is used to resize the video frames using imresize based on the SizingOption value in the info struct. Alternatively, you could use "randomcrop" or "centercrop" as values for SizingOption to random crop or center crop the input data to the input size of the video classifier.
preprocessInfo.Statistics = slowFast.InputNormalizationStatistics;
preprocessInfo.InputSize = inputSize;
preprocessInfo.SizingOption = "resize";
dsTrain = transform(dsTrain,@(data)preprocessVideoClips(data,preprocessInfo));Train SlowFast Video Classifier
This section of the example shows how the video classifier shown above is trained using transfer learning. Set the doTraining variable to false to use the pretrained video classifier without having to wait for training to complete. Alternatively, if you want to train the video classifier, set the doTraining variable to true.
doTraining = false;
Define Model Gradients Function
The modelGradients function, listed at the end of this example, takes as input the SlowFast video classifier slowFast, a mini-batch of input data dlRGB, and a mini-batch of ground truth label data dlY. The function returns the training loss value, the gradients of the loss with respect to the learnable parameters of the classifier, and the mini-batch accuracy of the classifier.
The loss is calculated by computing the cross-entropy loss of the predictions from video classifier. The output predictions of the network are probabilities between 0 and 1 for each of the classes.
The accuracy of the classifier is calculated by comparing the classifier predictions to the ground truth label of the inputs, dlY.
Specify Training Options
Train with a mini-batch size of 5 for 600 iterations. Specify the iteration after which to save the model with the best mini-batch loss by using the SaveBestAfterIteration parameter.
Specify the cosine-annealing learning rate schedule [3] parameters:
A minimum learning rate of 1e-4.
A maximum learning rate of 1e-3.
Cosine number of iterations of 200, 300, and 400, after which the learning rate schedule cycle restarts. The option
CosineNumIterationsdefines the width of each cosine cycle.
Specify the parameters for SGDM optimization. Initialize the SGDM optimization parameters at the beginning of the training:
A momentum of 0.9.
An initial velocity parameter initialized as
[].An L2 regularization factor of 0.0005.
Specify to dispatch the data in the background using a parallel pool. If DispatchInBackground is set to true, open a parallel pool with the specified number of parallel workers, and create a DispatchInBackgroundDatastore, provided as part of this example, that dispatches the data in the background to speed up training using asynchronous data loading and preprocessing. By default, this example uses a GPU if one is available. Otherwise, it uses a CPU. Using a GPU requires Parallel Computing Toolbox™ and a CUDA® enabled NVIDIA® GPU. For information about the supported compute capabilities, see GPU Computing Requirements (Parallel Computing Toolbox).
params.Classes = classes; params.MiniBatchSize = 5; params.NumIterations = 600; params.CosineNumIterations = [100 200 300]; params.SaveBestAfterIteration = 400; params.MinLearningRate = 1e-4; params.MaxLearningRate = 1e-3; params.Momentum = 0.9; params.Velocity = []; params.L2Regularization = 0.0005; params.ProgressPlot = false; params.Verbose = true; params.DispatchInBackground = true; params.NumWorkers = 12;
Train the SlowFast video classifier using the video data.
For each epoch:
Shuffle the data before looping over mini-batches of data.
Use
minibatchqueueto loop over the mini-batches. The supporting functioncreateMiniBatchQueue, listed at the end of this example, uses the given training datastore to create aminibatchqueue.Display the loss and accuracy results for each epoch using the supporting function
displayVerboseOutputEveryEpoch, listed at the end of this example.
For each mini-batch:
Convert the video data and the labels to
dlarrayobjects with the underlying type single.To enable processing the time dimension of the video data using the SlowFast video classifier specify the temporal sequence dimension,
"T". Specify the dimension labels"SSCTB"(spatial, spatial, channel, temporal, batch) for the video data, and"CB"for the label data.
The minibatchqueue object uses the supporting function batchVideo, listed at the end of this example, to batch the RGB video data.
params.ModelFilename = "slowFastPretrained_fourClasses.mat"; if doTraining epoch = 1; bestLoss = realmax; accTrain = []; lossTrain = []; iteration = 1; start = tic; trainTime = start; shuffled = shuffleTrainDs(dsTrain); % Number of outputs is two: One for RGB frames, and one for ground truth labels. numOutputs = 2; mbq = createMiniBatchQueue(shuffled, numOutputs, params); % Use the initializeTrainingProgressPlot and initializeVerboseOutput % supporting functions, listed at the end of the example, to initialize % the training progress plot and verbose output to display the training % loss, training accuracy, and validation accuracy. plotters = initializeTrainingProgressPlot(params); initializeVerboseOutput(params); while iteration <= params.NumIterations % Iterate through the data set. [dlX1,dlY] = next(mbq); % Evaluate the model gradients and loss using dlfeval. [gradients,loss,acc,state] = ... dlfeval(@modelGradients,slowFast,dlX1,dlY); % Accumulate the loss and accuracies. lossTrain = [lossTrain, loss]; accTrain = [accTrain, acc]; % Update the network state. slowFast.State = state; % Update the gradients and parameters for the video classifier % using the SGDM optimizer. [slowFast,params.Velocity,learnRate] = ... updateLearnables(slowFast,gradients,params,params.Velocity,iteration); if ~hasdata(mbq) || iteration == params.NumIterations % Current epoch is complete. Do validation and update progress. trainTime = toc(trainTime); accTrain = mean(accTrain); lossTrain = mean(lossTrain); % Update the training progress. displayVerboseOutputEveryEpoch(params,start,learnRate,epoch,iteration,... accTrain,lossTrain,trainTime); updateProgressPlot(params,plotters,epoch,iteration,start,lossTrain,accTrain); % Save the trained video classifier and the parameters, that gave % the best training loss so far. Use the saveData supporting function, % listed at the end of this example. bestLoss = saveData(slowFast,bestLoss,iteration,lossTrain,params); end if ~hasdata(mbq) && iteration < params.NumIterations % Current epoch is complete. Initialize the training loss, accuracy % values, and minibatchqueue for the next epoch. accTrain = []; lossTrain = []; epoch = epoch + 1; trainTime = tic; shuffled = shuffleTrainDs(dsTrain); mbq = createMiniBatchQueue(shuffled, numOutputs, params); end iteration = iteration + 1; end % Display a message when training is complete. endVerboseOutput(params); disp("Model saved to: " + params.ModelFilename); end
Evaluate SlowFast Video Classifier
To evaluate the accuracy of the trained SlowFast video classifier, set the isDataForTraining variable to false and create a fileDatastore. Note that data augmentation is not applied to the evaluation data. Ideally, test and evaluation data should be representative of the original data and is left unmodified for unbiased evaluation.
isDataForTraining = false; dsEval = createFileDatastore(trainingFolder,numFrames,numChannels,classes,isDataForTraining); dsEval = transform(dsEval,@(data)preprocessVideoClips(data,preprocessInfo));
Load the best model saved during training or use the pretrained model.
if doTraining transferLearned = load(params.ModelFilename); slowFastClassifier = transferLearned.data.slowFast; end
Create a minibatchqueue object to load batches of the test data.
numOutputs = 2; mbq = createMiniBatchQueue(dsEval,numOutputs,params);
For each batch of evaluation data, make predictions using the SlowFast video classifier, and compute the prediction accuracy using a confusion matrix.
numClasses = numel(params.Classes); cmat = sparse(numClasses,numClasses); while hasdata(mbq) [dlVideo,dlY] = next(mbq); % Computer the predictions of the trained SlowFast % video classifier. dlYPred = predict(slowFastClassifier,dlVideo); dlYPred = squeezeIfNeeded(dlYPred,dlY); % Aggregate the confusion matrix by using the maximum % values of the prediction scores and the ground truth labels. [~,YTest] = max(dlY,[],1); [~,YPred] = max(dlYPred,[],1); cmat = aggregateConfusionMetric(cmat,YTest,YPred); end
Compute the average clip classification accuracy for the trained SlowFast video classifier.
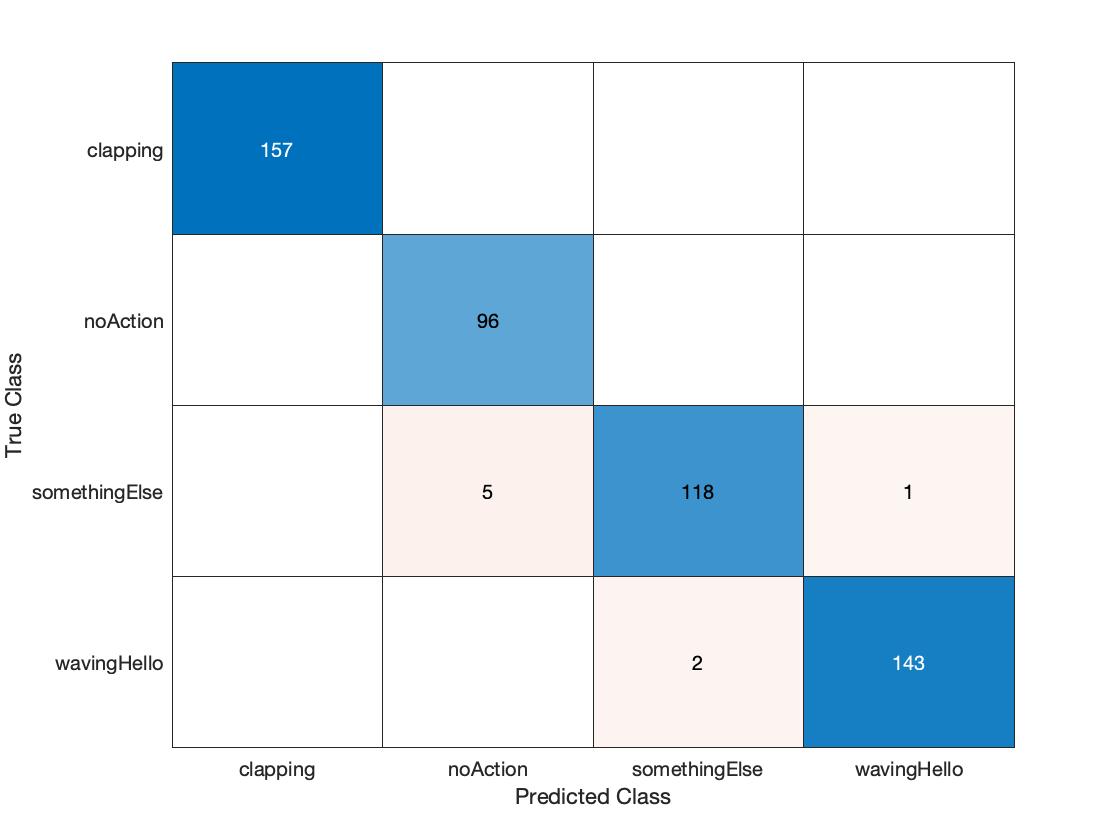
evalClipAccuracy = sum(diag(cmat))./sum(cmat,"all")evalClipAccuracy = 0.9847
Display the confusion matrix.
figure chart = confusionchart(cmat,classes);
The SlowFast video classifier that is pretrained on the Kinetics-400 data set [2], provides strong performance for human gesture recognition on transfer learning. The above training was run on 24GB Titan-X GPU for about 60 minutes. When training from scratch on a small gesture recognition video data set, the training time and convergence takes much longer than the pretrained video classifier. Transer learning using the Kinetics-400 pretrained SlowFast video classifier also avoids overfitting the classifier when ran for larger number of epochs on such a small gesture recognition video data set. To learn more about video recognition using deep learning, see Getting Started with Video Classification Using Deep Learning.
Supporting Functions
createFileDatastore
The createFileDatastore function creates a FileDatastore object using the given folder name. The FileDatastore object reads the data in 'partialfile' mode, so every read can return partially read frames from videos. This feature helps with reading large video files, if all of the frames do not fit in memory.
function datastore = createFileDatastore(trainingFolder,numFrames,numChannels,classes,isDataForTraining) readFcn = @(f,u)readVideo(f,u,numFrames,numChannels,classes,isDataForTraining); datastore = fileDatastore(trainingFolder,... 'IncludeSubfolders',true,... 'FileExtensions','.avi',... 'ReadFcn',readFcn,... 'ReadMode','partialfile'); end
shuffleTrainDs
The shuffleTrainDs function shuffles the files present in the training datastore, dsTrain.
function shuffled = shuffleTrainDs(dsTrain) shuffled = copy(dsTrain); transformed = isa(shuffled, 'matlab.io.datastore.TransformedDatastore'); if transformed files = shuffled.UnderlyingDatastores{1}.Files; else files = shuffled.Files; end n = numel(files); shuffledIndices = randperm(n); if transformed shuffled.UnderlyingDatastores{1}.Files = files(shuffledIndices); else shuffled.Files = files(shuffledIndices); end reset(shuffled); end
readVideo
The readVideo function reads video frames, and the corresponding label values for a given video file. During training, the read function reads the specific number of frames as per the network input size, with a randomly chosen starting frame. During testing, all the frames are sequentially read. The video frames are resized to the required classifier network input size for training, and for testing and validation.
function [data,userdata,done] = readVideo(filename,userdata,numFrames,numChannels,classes,isDataForTraining) if isempty(userdata) userdata.reader = VideoReader(filename); userdata.batchesRead = 0; userdata.label = getLabel(filename,classes); totalFrames = floor(userdata.reader.Duration * userdata.reader.FrameRate); totalFrames = min(totalFrames, userdata.reader.NumFrames); userdata.totalFrames = totalFrames; userdata.datatype = class(read(userdata.reader,1)); end reader = userdata.reader; totalFrames = userdata.totalFrames; label = userdata.label; batchesRead = userdata.batchesRead; if isDataForTraining video = readForTraining(reader,numFrames,totalFrames); else video = readForEvaluation(reader,userdata.datatype,numChannels,numFrames,totalFrames); end data = {video, label}; batchesRead = batchesRead + 1; userdata.batchesRead = batchesRead; if numFrames > totalFrames numBatches = 1; else numBatches = floor(totalFrames/numFrames); end % Set the done flag to true, if the reader has read all the frames or % if it is training. done = batchesRead == numBatches || isDataForTraining; end
readForTraining
The readForTraining function reads the video frames for training the video classifier. The function reads the specific number of frames as per the network input size, with a randomly chosen starting frame. If there are not enough frames left over, the video sequence is repeated to pad the required number of frames.
function video = readForTraining(reader,numFrames,totalFrames) if numFrames >= totalFrames startIdx = 1; endIdx = totalFrames; else startIdx = randperm(totalFrames - numFrames + 1); startIdx = startIdx(1); endIdx = startIdx + numFrames - 1; end video = read(reader,[startIdx,endIdx]); if numFrames > totalFrames % Add more frames to fill in the network input size. additional = ceil(numFrames/totalFrames); video = repmat(video,1,1,1,additional); video = video(:,:,:,1:numFrames); end end
readForEvaluation
The readForEvaluation function reads the video frames for evaluating the trained video classifier. The function reads the specific number of frames sequentially as per the network input size. If there are not enough frames left over, the video sequence is repeated to pad the required number of frames.
function video = readForEvaluation(reader,datatype,numChannels,numFrames,totalFrames) H = reader.Height; W = reader.Width; toRead = min([numFrames,totalFrames]); video = zeros([H,W,numChannels,toRead],datatype); frameIndex = 0; while hasFrame(reader) && frameIndex < numFrames frame = readFrame(reader); frameIndex = frameIndex + 1; video(:,:,:,frameIndex) = frame; end if frameIndex < numFrames video = video(:,:,:,1:frameIndex); additional = ceil(numFrames/frameIndex); video = repmat(video,1,1,1,additional); video = video(:,:,:,1:numFrames); end end
getLabel
The getLabel function obtains the label name from the full path of a filename. The label for a file is the folder in which it exists. For example, for a file path such as "/path/to/data set/clapping/video_0001.avi", the label name is "clapping".
function label = getLabel(filename,classes) folder = fileparts(string(filename)); [~,label] = fileparts(folder); label = categorical(string(label),string(classes)); end
augmentVideo
The augmentVideo function augments the video frames for training the video classifier. The function augments a video sequence with the same augmentation technique provided by the augmentTransform function.
function data = augmentVideo(data) numClips = size(data,1); for ii = 1:numClips video = data{ii,1}; % HxWxC sz = size(video,[1,2,3]); % One augment fcn per clip augmentFcn = augmentTransform(sz); data{ii,1} = augmentFcn(video); end end
augmentTransform
The augmentTransform function creates an augmentation method with random left-right flipping and scaling factors.
function augmentFcn = augmentTransform(sz) % Randomly flip and scale the image. tform = randomAffine2d('XReflection',true,'Scale',[1 1.1]); rout = affineOutputView(sz,tform,'BoundsStyle','CenterOutput'); augmentFcn = @(data)augmentData(data,tform,rout); function data = augmentData(data,tform,rout) data = imwarp(data,tform,'OutputView',rout); end end
preprocessVideoClips
The preprocessVideoClips function preprocesses the training video data to resize to the SlowFast video classifier input size. It takes the InputNormalizationStatistics and the InputSize properties of the video classifier in a struct, info. The InputNormalizationStatistics property is used to rescale the video frames between 0 and 1, and then normalize the rescaled data using mean and standard deviation. The input size is used to resize the video frames using imresize based on the SizingOption value in the info struct. Alternatively, you could use "randomcrop" or "centercrop" as values for SizingOption to random crop or center crop the input data to the input size of the video classifier.
function data = preprocessVideoClips(data, info) inputSize = info.InputSize(1:2); sizingOption = info.SizingOption; switch sizingOption case "resize" sizingFcn = @(x)imresize(x,inputSize); case "randomcrop" sizingFcn = @(x)cropVideo(x,@randomCropWindow2d,inputSize); case "centercrop" sizingFcn = @(x)cropVideo(x,@centerCropWindow2d,inputSize); end numClips = size(data,1); minValue = info.Statistics.Min; maxValue = info.Statistics.Max; meanValue = info.Statistics.Mean; stdValue = info.Statistics.StandardDeviation; minValue = reshape(minValue,1,1,3); maxValue = reshape(maxValue,1,1,3); meanValue = reshape(meanValue,1,1,3); stdValue = reshape(stdValue,1,1,3); for ii = 1:numClips video = data{ii,1}; resized = sizingFcn(video); % Cast the input to single. resized = single(resized); % Rescale the input between 0 and 1. resized = rescale(resized,0,1,InputMin=minValue,InputMax=maxValue); % Normalize using mean and standard deviation. resized = resized - meanValue; resized = resized./stdValue; data{ii,1} = resized; end function outData = cropVideo(data,cropFcn,inputSize) imsz = size(data,[1,2]); cropWindow = cropFcn(imsz,inputSize); numBatches = size(data,4); sz = [inputSize, size(data,3),numBatches]; outData = zeros(sz,'like',data); for b = 1:numBatches outData(:,:,:,b) = imcrop(data(:,:,:,b),cropWindow); end end end
createMiniBatchQueue
The createMiniBatchQueue function creates a minibatchqueue object that provides miniBatchSize amount of data from the given datastore. It also creates a DispatchInBackgroundDatastore if a parallel pool is open.
function mbq = createMiniBatchQueue(datastore, numOutputs, params) if params.DispatchInBackground && isempty(gcp('nocreate')) % Start a parallel pool, if DispatchInBackground is true, to dispatch % data in the background using the parallel pool. c = parcluster('local'); c.NumWorkers = params.NumWorkers; parpool('local',params.NumWorkers); end p = gcp('nocreate'); if ~isempty(p) datastore = DispatchInBackgroundDatastore(datastore, p.NumWorkers); end inputFormat(1:numOutputs-1) = "SSCTB"; outputFormat = "CB"; mbq = minibatchqueue(datastore, numOutputs, ... "MiniBatchSize", params.MiniBatchSize, ... "MiniBatchFcn", @batchVideo, ... "MiniBatchFormat", [inputFormat,outputFormat]); end
batchVideo
The batchVideo function batches the video, and the label data from cell arrays. It uses onehotencode function to encode ground truth categorical labels into one-hot arrays. The one-hot encoded array contains a 1 in the position corresponding to the class of the label, and 0 in every other position.
function [video,labels] = batchVideo(video,labels) % Batch dimension: 5 video = cat(5,video{:}); % Batch dimension: 2 labels = cat(2,labels{:}); % Feature dimension: 1 labels = onehotencode(labels,1); end
modelGradients
The modelGradients function takes as input a mini-batch of RGB data dlRGB, and the corresponding target dlY, and returns the corresponding loss, the gradients of the loss with respect to the learnable parameters, and the training accuracy. To compute the gradients, evaluate the modelGradients function using the dlfeval function in the training loop.
function [gradientsRGB,loss,acc,stateRGB] = modelGradients(slowFast,dlRGB,dlY) [dlYPredRGB,stateRGB] = forward(slowFast,dlRGB); dlYPred = squeezeIfNeeded(dlYPredRGB,dlY); loss = crossentropy(dlYPred,dlY); gradientsRGB = dlgradient(loss,slowFast.Learnables); % Calculate the accuracy of the predictions. [~,YTest] = max(dlY,[],1); [~,YPred] = max(dlYPred,[],1); acc = gather(extractdata(sum(YTest == YPred)./numel(YTest))); end
squeezeIfNeeded
The squeezeIfNeeded function takes as the predicted scores, dlYPred and corresponding target Y, and returns the predicted scores dlYPred, after squeezing the singleton dimensions, if there are any.
function dlYPred = squeezeIfNeeded(dlYPred,Y) if ~isequal(size(Y),size(dlYPred)) dlYPred = squeeze(dlYPred); dlYPred = dlarray(dlYPred,dims(Y)); end end
updateLearnables
The updateLearnables function updates the learnable parameters of the SlowFast video classifier with gradients and other parameters using SGDM optimization function sgdmupdate.
function [slowFast,velocity,learnRate] = updateLearnables(slowFast,gradients,params,velocity,iteration) % Determine the learning rate using the cosine-annealing learning rate schedule. learnRate = cosineAnnealingLearnRate(iteration, params); % Apply L2 regularization to the weights. learnables = slowFast.Learnables; idx = learnables.Parameter == "Weights"; gradients(idx,:) = dlupdate(@(g,w) g + params.L2Regularization*w,gradients(idx,:),learnables(idx,:)); % Update the network parameters using the SGDM optimizer. [slowFast, velocity] = sgdmupdate(slowFast,gradients,velocity,learnRate,params.Momentum); end
cosineAnnealingLearnRate
The cosineAnnealingLearnRate function computes the learning rate based on the current iteration number, minimum learning rate, maximum learning rate, and number of iterations for annealing [3].
function lr = cosineAnnealingLearnRate(iteration,params) if iteration == params.NumIterations lr = params.MinLearningRate; return; end cosineNumIter = [0, params.CosineNumIterations]; csum = cumsum(cosineNumIter); block = find(csum >= iteration, 1,'first'); cosineIter = iteration - csum(block - 1); annealingIteration = mod(cosineIter,cosineNumIter(block)); cosineIteration = cosineNumIter(block); minR = params.MinLearningRate; maxR = params.MaxLearningRate; cosMult = 1 + cos(pi * annealingIteration / cosineIteration); lr = minR + ((maxR - minR) * cosMult / 2); end
aggregateConfusionMetric
The aggregateConfusionMetric function incrementally fills a confusion matrix based on the predicted results YPred and the expected results YTest.
function cmat = aggregateConfusionMetric(cmat,YTest,YPred) YTest = gather(extractdata(YTest)); YPred = gather(extractdata(YPred)); [m,n] = size(cmat); cmat = cmat + full(sparse(YTest,YPred,1,m,n)); end
saveData
The saveData function saves the given SlowFast video classifier, loss, and other training parameters to a MAT-file.
function bestLoss = saveData(slowFast,bestLoss,iteration,lossTrain,params) if iteration >= params.SaveBestAfterIteration trainingLoss = extractdata(gather(lossTrain)); if trainingLoss < bestLoss bestLoss = trainingLoss; slowFast = gatherFromGPUToSave(slowFast); data.BestLoss = bestLoss; data.slowFast = slowFast; data.Params = params; save(params.ModelFilename,'data'); end end end
gatherFromGPUToSave
The gatherFromGPUToSave function gathers data from the GPU in order to save the model to disk.
function slowfast = gatherFromGPUToSave(slowfast) if ~canUseGPU return; end slowfast.Learnables = gatherValues(slowfast.Learnables); slowfast.State = gatherValues(slowfast.State); function tbl = gatherValues(tbl) for ii = 1:height(tbl) tbl.Value{ii} = gather(tbl.Value{ii}); end end end
extractVideoScenes
The extractVideoScenes function extracts training video data from a collection of videos and its corresponding collection of scene labels, by using the functions sceneTimeRanges and writeVideoScenes.
function extractVideoScenes(groundTruthFolder,trainingFolder,classes) % If the video scenes are already extracted, no need to download % the data set and extract video scenes. if isfolder(trainingFolder) classFolders = fullfile(trainingFolder,string(classes)); allClassFoldersFound = true; for ii = 1:numel(classFolders) if ~isfolder(classFolders(ii)) allClassFoldersFound = false; break; end end if allClassFoldersFound return; end end if ~isfolder(groundTruthFolder) mkdir(groundTruthFolder); end downloadURL = "https://ssd.mathworks.com/supportfiles/vision/data/videoClipsAndSceneLabels.zip"; filename = fullfile(groundTruthFolder,"videoClipsAndSceneLabels.zip"); if ~exist(filename,'file') disp("Downloading the video clips and the corresponding scene labels to " + groundTruthFolder); websave(filename,downloadURL); end % Unzip the contents to the download folder. unzip(filename,groundTruthFolder); labelDataFiles = dir(fullfile(groundTruthFolder,"*_labelData.mat")); labelDataFiles = fullfile(groundTruthFolder,{labelDataFiles.name}'); numGtruth = numel(labelDataFiles); % Load the label data information and create ground truth objects. gTruth = groundTruth.empty(numGtruth,0); for ii = 1:numGtruth ld = load(labelDataFiles{ii}); videoFilename = fullfile(groundTruthFolder,ld.videoFilename); gds = groundTruthDataSource(videoFilename); gTruth(ii) = groundTruth(gds,ld.labelDefs,ld.labelData); end % Gather all the scene time ranges and the corresponding scene labels % using the sceneTimeRanges function. [timeRanges, sceneLabels] = sceneTimeRanges(gTruth); % Specify the subfolder names for each duration as the scene label names. foldernames = sceneLabels; % Delete the folder if it already exists. if isfolder(trainingFolder) rmdir(trainingFolder,'s'); end % Video files are written to the folders specified by the folderNames input. writeVideoScenes(gTruth,timeRanges,trainingFolder,foldernames); end
initializeTrainingProgressPlot
The initializeTrainingProgressPlot function configures two plots for displaying the training loss, and the training accuracy.
function plotters = initializeTrainingProgressPlot(params) if params.ProgressPlot % Plot the loss, training accuracy, and validation accuracy. figure % Loss plot subplot(2,1,1) plotters.LossPlotter = animatedline; xlabel("Iteration") ylabel("Loss") % Accuracy plot subplot(2,1,2) plotters.TrainAccPlotter = animatedline('Color','b'); legend('Training Accuracy','Location','northwest'); xlabel("Iteration") ylabel("Accuracy") else plotters = []; end end
updateProgressPlot
The updateProgressPlot function updates the progress plot with loss and accuracy information during training.
function updateProgressPlot(params,plotters,epoch,iteration,start,lossTrain,accuracyTrain) if params.ProgressPlot % Update the training progress. D = duration(0,0,toc(start),"Format","hh:mm:ss"); title(plotters.LossPlotter.Parent,"Epoch: " + epoch + ", Elapsed: " + string(D)); addpoints(plotters.LossPlotter,iteration,double(gather(extractdata(lossTrain)))); addpoints(plotters.TrainAccPlotter,iteration,accuracyTrain); drawnow end end
initializeVerboseOutput
The initializeVerboseOutput function displays the column headings for the table of training values, which shows the epoch, mini-batch accuracy, and other training values.
function initializeVerboseOutput(params) if params.Verbose disp(" ") if canUseGPU disp("Training on GPU.") else disp("Training on CPU.") end p = gcp('nocreate'); if ~isempty(p) disp("Training on parallel cluster '" + p.Cluster.Profile + "'. ") end disp("NumIterations:" + string(params.NumIterations)); disp("MiniBatchSize:" + string(params.MiniBatchSize)); disp("Classes:" + join(string(params.Classes),",")); disp("|===========================================================================================|") disp("| Epoch | Iteration | Time Elapsed | Mini-Batch | Mini-Batch | Base Learning | Train Time |") disp("| | | (hh:mm:ss) | Accuracy | Loss | Rate | (hh:mm:ss) |") disp("|===========================================================================================|") end end
displayVerboseOutputEveryEpoch
The displayVerboseOutputEveryEpoch function displays the verbose output of the training values, such as the epoch, mini-batch accuracy, and mini-batch loss.
function displayVerboseOutputEveryEpoch(params,start,learnRate,epoch,iteration,... accTrain,lossTrain,trainTime) if params.Verbose D = duration(0,0,toc(start),'Format','hh:mm:ss'); trainTime = duration(0,0,trainTime,'Format','hh:mm:ss'); lossTrain = gather(extractdata(lossTrain)); lossTrain = compose('%.4f',lossTrain); accTrain = composePadAccuracy(accTrain); learnRate = compose('%.13f',learnRate); disp("| " + ... pad(string(epoch),5,'both') + " | " + ... pad(string(iteration),9,'both') + " | " + ... pad(string(D),12,'both') + " | " + ... pad(string(accTrain),10,'both') + " | " + ... pad(string(lossTrain),10,'both') + " | " + ... pad(string(learnRate),13,'both') + " | " + ... pad(string(trainTime),10,'both') + " |") end function acc = composePadAccuracy(acc) acc = compose('%.2f',acc*100) + "%"; acc = pad(string(acc),6,'left'); end end
endVerboseOutput
The endVerboseOutput function displays the end of verbose output during training.
function endVerboseOutput(params) if params.Verbose disp("|===========================================================================================|") end end
References
[1] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. "SlowFast Networks for Video Recognition." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
[2] Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, Andrew Zisserman. "The Kinetics Human Action Video data set." arXiv preprint arXiv:1705.06950, 2017.
[3] Loshchilov, Ilya, and Frank Hutter. "SGDR: Stochastic Gradient Descent with Warm Restarts." International Conferencee on Learning Representations 2017. Toulon, France: ICLR, 2017.