イメージ カテゴリの分類
Computer Vision Toolbox™ のイメージ カテゴリ分類ツールを使用すると、深層学習ベースのビジョン トランスフォーマー モデルまたは従来の bag-of-visual-words 手法のいずれかを使用して、イメージを定義済みのカテゴリに分類できます。イメージ カテゴリ分類機能は、シーン認識、コンテンツ フィルター処理、自動タグ付けなどの用途において不可欠です。イメージ ラベラー アプリとビデオ ラベラー アプリを使用して、ラベル付きデータ セットを作成することから始められます。これらのアプリは、それぞれイメージとビデオ フレームに対するシーンレベルのラベルの、対話形式および AI アシストによる注釈付けをサポートしています。これらのラベルは、イメージ分類モデルの学習と評価におけるグラウンド トゥルースとして機能します。
深層学習ベースの分類のために、ツールボックスは visionTransformer 関数を通じて、事前学習済みのビジョン トランスフォーマー (ViT) モデルへのアクセスを提供します。これらのモデルは self-attention メカニズムを使用してイメージ全体のコンテキストを捉え、カスタム データ セット用に微調整することも可能です。patchEmbeddingLayer などのサポート層を使用することで、ViT アーキテクチャの設計と拡張が可能になります。さらに、ツールボックスには、視覚と言語理解を組み合わせてイメージ分類を実行する CLIP ネットワークのサポートも含まれます。clipNetwork オブジェクトと classify オブジェクト関数を使用して、視覚コンテンツとテキストによる説明を関連付けるイメージ分類タスクを実行し、マルチモーダル アプリケーションを実現します。
従来式のアプローチのために、ツールボックスは、イメージを視覚的な単語出現頻度のヒストグラムとして表現する bag-of-features (BoF) フレームワークをサポートしています。bagOfFeatures オブジェクトを使用して特徴を抽出し、ビジュアル ボキャブラリを構築した後、trainImageCategoryClassifier 関数を使用して分類器に学習させ、imageCategoryClassifier 関数を使用して予測を行うことができます。この方法は、軽量なアプリケーションや、解釈可能性が優先される場合に特に有効です。詳細については、bag of visual words を用いたイメージの分類を参照してください。
関数
トピック
イメージ分類のためのグラウンド トゥルースの作成
- イメージ ラベラー入門
四角形の ROI (オブジェクト検出用)、ピクセル (セマンティック セグメンテーション用)、多角形 (インスタンス セグメンテーション用)、およびシーン (イメージ分類用) に対話形式でラベルを付ける。 - ビデオ ラベラー入門
ビデオおよびイメージのシーケンス内の四角形の ROI (オブジェクト検出用)、ピクセル (セマンティック セグメンテーション用)、多角形 (インスタンス セグメンテーション用)、およびシーン (イメージ分類用) に対話形式でラベルを付ける。
深層学習モデルを使用したイメージ分類
- イメージ分類のためのビジョン トランスフォーマー ネットワークの学習
この例では、事前学習済みのビジョン トランスフォーマー (ViT) ニューラル ネットワークを微調整して、新しいイメージ コレクションを分類する方法を説明します。 - シンプルなイメージ分類ネットワークの作成 (Deep Learning Toolbox)
この例では、深層学習による分類用のシンプルな畳み込みニューラル ネットワークを作成し、学習を行う方法を説明します。 - イメージ分類入門 (Deep Learning Toolbox)
この例では、ディープ ネットワーク デザイナー アプリを使用して深層学習による分類用のシンプルな畳み込みニューラル ネットワークを作成する方法を示します。
Bag of Features アプローチを使用したイメージの分類
- カスタム特徴抽出器の作成
bag-of-features (BoF) フレームワークはさまざまなタイプのイメージ特徴に使用できます。 - bag of visual words を用いたイメージの分類
Computer Vision Toolbox 関数を使用して bag of visual words を作成することで、イメージをカテゴリに分類します。
注目の例
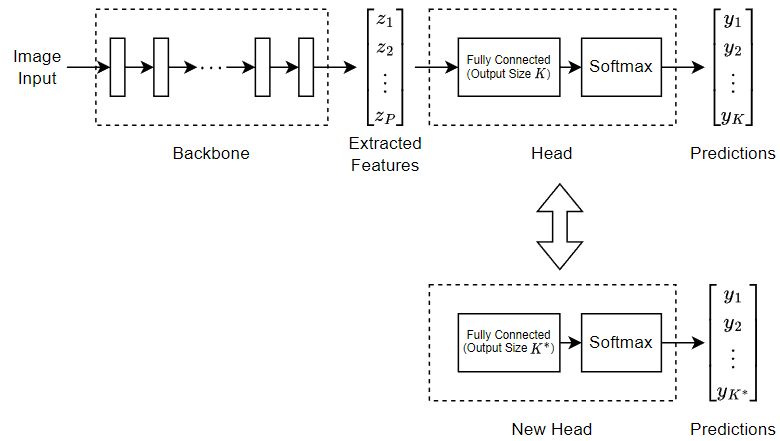
イメージ分類のためのビジョン トランスフォーマー ネットワークの学習
この例では、事前学習済みのビジョン トランスフォーマー (ViT) ニューラル ネットワークを微調整して、新しいイメージ コレクションを分類する方法を説明します。

bag of features を使用したイメージ カテゴリの分類
この例では、bag of features の手法を使用してイメージ カテゴリの分類を行う方法を説明します。この手法は、多くの場合 bag of words とも呼ばれます。視覚的イメージの分類は、テスト対象のイメージにカテゴリ ラベルを割り当てる処理です。カテゴリには犬、猫、列車、船舶など、あらゆるものを表すイメージが含まれます。

深層学習を使用したイメージ カテゴリの分類
この例では、事前学習済みの畳み込みニューラル ネットワーク (CNN) を特徴抽出器として使用して、イメージ カテゴリ分類器に学習させる方法を説明します。