countlabels
一意のラベル数のカウント
説明
機械学習や深層学習の分類問題に取り組む際に、データセットの中のラベル値の比率を調べたい場合に使用する関数です。
例
categorical 配列
カテゴリ A、B、C および D をもつ categorical 配列を生成します。配列には、各カテゴリのサンプルが含まれます。
lbls = categorical(["B" "C" "A" "D" "B" "A" "A" "B" "C" "A"]', ... ["A" "B" "C" "D"])
lbls = 10×1 categorical
B
C
A
D
B
A
A
B
C
A
配列内の一意のラベル カテゴリ値の数をカウントします。
cnt = countlabels(lbls)
cnt=4×3 table
Label Count Percent
_____ _____ _______
A 4 40
B 3 30
C 2 20
D 1 10
同じカテゴリをもつ 2 番目の categorical 配列を生成します。配列には、各カテゴリのサンプルと、欠損値をもつサンプルが 1 つ含まれます。
mlbls = categorical(["B" "C" "A" "D" "B" "A" missing "B" "C" "A"]', ... ["A" "B" "C" "D"])
mlbls = 10×1 categorical
B
C
A
D
B
A
<undefined>
B
C
A
配列内の一意のラベル カテゴリ値の数をカウントします。欠損値をもつサンプルは、<undefined> としてカウントに含まれます。
mcnt = countlabels(mlbls)
mcnt=5×3 table
Label Count Percent
___________ _____ _______
A 3 30
B 3 30
C 2 20
D 1 10
<undefined> 1 10
文字配列
関数 fileread でウィリアム・シェイクスピアのソネット集を読み取ります。テキストからアルファベット以外の文字をすべて削除し、小文字に変換します。
sonnets = fileread("sonnets.txt"); letters = lower(sonnets(regexp(sonnets,"[A-z]")))';
それぞれの文字がソネット集の中に何回出現するかカウントします。最も多く出現する文字をリスト表示します。
cnt = countlabels(letters); cnt = sortrows(cnt,"Count","descend"); head(cnt)
Label Count Percent
_____ _____ _______
e 9028 12.298
t 7210 9.8216
o 5710 7.7782
h 5064 6.8982
s 4994 6.8029
a 4940 6.7293
i 4895 6.668
n 4522 6.1599
数値配列
関数 poisrand を使用して、レート パラメーター 3 のポアソン分布から 1,000 個のランダムな整数の配列を生成します。結果のヒストグラムをプロットします。
N = 1000; lam = 3; nums = zeros(N,1); for jk = 1:N nums(jk) = poisrand(lam); end histogram(nums)
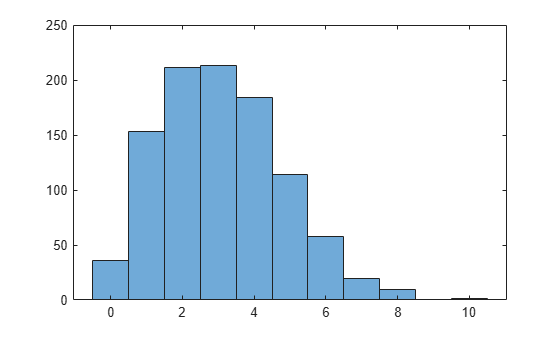
配列で表現される整数の度数をカウントします。
mm = countlabels(nums)
mm=10×3 table
Label Count Percent
_____ _____ _______
0 36 3.6
1 153 15.3
10 1 0.1
2 211 21.1
3 213 21.3
4 184 18.4
5 114 11.4
6 58 5.8
7 20 2
8 10 1
function num = poisrand(lam) % Poisson random integer using rejection method p = 0; num = -1; while p <= lam p = p - log(rand); num = num + 1; end end
2 つの変数をもつ文字の table を作成します。最初の変数 Type1 には、P 、Q および R の文字のインスタンスが格納されます。2 番目の変数 Type2 には、A、B および D の文字のインスタンスが格納されます。
tbl = table(["P" "R" "P" "Q" "Q" "Q" "R" "P"]', ... ["A" "B" "B" "A" "D" "D" "A" "A"]',... 'VariableNames',["Type1","Type2"]);
それぞれの文字が各 table 変数の中に何回出現するかカウントします。
cnt = countlabels(tbl,'TableVariable','Type1')
cnt=3×3 table
Type1 Count Percent
_____ _____ _______
P 3 37.5
Q 3 37.5
R 2 25
cnt = countlabels(tbl,'TableVariable','Type2')
cnt=3×3 table
Type2 Count Percent
_____ _____ _______
A 4 50
B 2 25
D 2 25
table を格納する ArrayDatastore オブジェクトを作成します。
ads = arrayDatastore(tbl,'OutputType','same');
それぞれの文字が各 table 変数の中に何回出現するかカウントします。
cnt = countlabels(ads,'TableVariable','Type1')
cnt=3×3 table
Type1 Count Percent
_____ _____ _______
P 3 37.5
Q 3 37.5
R 2 25
cnt = countlabels(ads,'TableVariable','Type2')
cnt=3×3 table
Type2 Count Percent
_____ _____ _______
A 4 50
B 2 25
D 2 25
入力引数
名前と値の引数
出力引数
バージョン履歴
R2021a で導入