cluster
混合ガウス分布からクラスターを作成
構文
説明
例
関数 mvnrnd を使用して、2 つの二変量ガウス分布の混合に従う確率変量を生成します。関数 fitgmdist を使用して、生成したデータに混合ガウスモデル (GMM) を当てはめます。次に、関数 cluster を使用して、当てはめた GMM の成分によって決定される 2 つのクラスターにデータを分割します。
2 つの二変量混合ガウス成分の分布パラメーター (平均と共分散) を定義します。
mu1 = [2 2]; % Mean of the 1st component sigma1 = [2 0; 0 1]; % Covariance of the 1st component mu2 = [-2 -1]; % Mean of the 2nd component sigma2 = [1 0; 0 1]; % Covariance of the 2nd component
各成分から同じ個数の確率変量を生成し、2 組の確率変量を結合します。
rng('default') % For reproducibility r1 = mvnrnd(mu1,sigma1,1000); r2 = mvnrnd(mu2,sigma2,1000); X = [r1; r2];
結合したデータ セット X には、2 つの二変量ガウス分布の混合に従う確率変量が含まれています。
2 成分の GMM を X に当てはめます。
gm = fitgmdist(X,2);
scatterを使用して、X をプロットします。当てはめられたモデル gm を pdfとfcontour を使用して可視化します。
figure scatter(X(:,1),X(:,2),10,'.') % Scatter plot with points of size 10 hold on gmPDF = @(x,y) arrayfun(@(x0,y0) pdf(gm,[x0 y0]),x,y); fcontour(gmPDF,[-6 8 -4 6])

近似させた GMM とデータを cluster に渡すことにより、データをクラスターに分割します。
idx = cluster(gm,X);
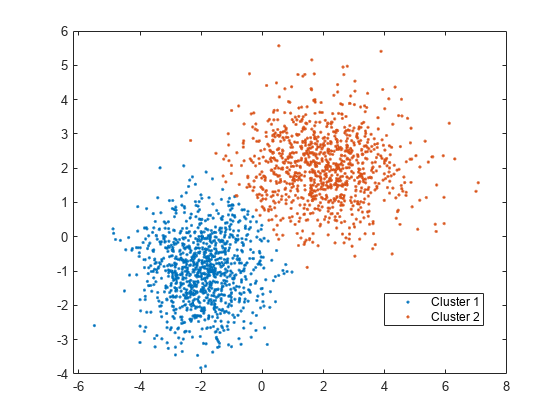
gscatter を使用して、idx によってグループ化された散布図を作成します。
figure; gscatter(X(:,1),X(:,2),idx); legend('Cluster 1','Cluster 2','Location','best');
入力引数
出力引数
バージョン履歴
R2007b で導入