CompactClassificationEnsemble
Compact classification ensemble
Description
Compact version of a classification ensemble. The compact version does not include the data for training the classification ensemble. Therefore, you cannot perform some tasks with a compact classification ensemble, such as cross validation. Use a compact classification ensemble for making predictions (classifications) of new data.
Creation
Syntax
Description
Input Arguments
Properties
Object Functions
compareHoldout | Compare accuracies of two classification models using new data |
edge | Classification edge for classification ensemble model |
gather | Gather properties of Statistics and Machine Learning Toolbox object from GPU |
lime | Local interpretable model-agnostic explanations (LIME) |
loss | Classification loss for classification ensemble model |
margin | Classification margins for classification ensemble model |
partialDependence | Compute partial dependence |
plotPartialDependence | Create partial dependence plot (PDP) and individual conditional expectation (ICE) plots |
predict | Predict labels using classification ensemble model |
predictorImportance | Estimates of predictor importance for classification ensemble of decision trees |
removeLearners | Remove members of compact classification ensemble |
shapley | Shapley values |
Examples
Reduce Size of Classification Ensemble
Create a compact classification ensemble for efficiently making predictions on new data.
Load the ionosphere data set.
load ionosphereTrain a boosted ensemble of 100 classification trees using all measurements and the AdaBoostM1 method.
Mdl = fitcensemble(X,Y,Method="AdaBoostM1")Mdl =
ClassificationEnsemble
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumObservations: 351
NumTrained: 100
Method: 'AdaBoostM1'
LearnerNames: {'Tree'}
ReasonForTermination: 'Terminated normally after completing the requested number of training cycles.'
FitInfo: [100x1 double]
FitInfoDescription: {2x1 cell}
Mdl is a ClassificationEnsemble model object that contains the training data, among other things.
Create a compact version of Mdl.
CMdl = compact(Mdl)
CMdl =
CompactClassificationEnsemble
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumTrained: 100
CMdl is a CompactClassificationEnsemble model object. CMdl is almost the same as Mdl. One exception is that CMdl does not store the training data.
Compare the amounts of space consumed by Mdl and CMdl.
mdlInfo = whos("Mdl"); cMdlInfo = whos("CMdl"); [mdlInfo.bytes cMdlInfo.bytes]
ans = 1×2
895597 648755
Mdl consumes more space than CMdl.
CMdl.Trained stores the trained classification trees (CompactClassificationTree model objects) that compose Mdl.
Display a graph of the first tree in the compact ensemble.
view(CMdl.Trained{1},Mode="graph");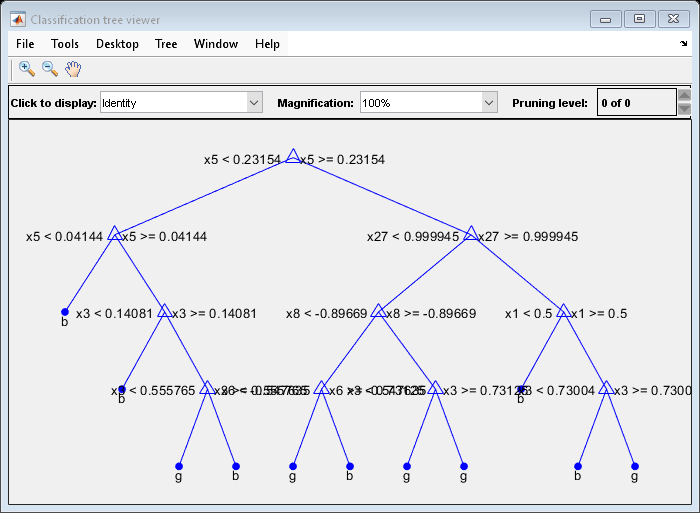
By default, fitcensemble grows shallow trees for boosted ensembles of trees.
Predict the label of the mean of X using the compact ensemble.
predMeanX = predict(CMdl,mean(X))
predMeanX = 1x1 cell array
{'g'}
Tips
For an ensemble of classification trees, the Trained property
of ens stores an ens.NumTrained-by-1
cell vector of compact classification models. For a textual or graphical
display of tree t in the cell vector, enter:
view(ens.Trained{for ensembles aggregated using LogitBoost or GentleBoost.t}.CompactRegressionLearner)view(ens.Trained{for all other aggregation methods.t})
Extended Capabilities
Version History
Introduced in R2011aSee Also
fitcensemble | ClassificationEnsemble | predict | compact | fitctree | view | compareHoldout
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)