AXI4 Master インターフェイスを生成するためのモデル設計
外部メモリからの大規模なデータセットへのアクセスを必要とする設計では、簡易 AXI4 Master プロトコルを使用してアルゴリズムをモデル化します。IP Core Generation ワークフローを実行すると、HDL Coder™ は AXI4 Master インターフェイスを備えた IP コアを生成します。AXI4 Master インターフェイスは、AXI4 Master プロトコルを使用して現在の設計と外部メモリ コントローラー IP の間の通信を行うことができます。次の場合に AXI4 Master インターフェイスを使用します。
設計がマルチフレーム動画処理アプリケーションをターゲットにしている場合。イメージ データをボード上の DDR3 メモリなどの外部メモリに格納して、そのイメージを高速処理のためにバーストで設計に読み取ったり書き込んだりできます。
アルゴリズムがストリーミング以外の任意のパターンでメモリ データにアクセスしなければならない場合。
DUT IP コアがシステム内の、AXI4 や AXI4-Lite などのレジスタ インターフェイスを備えた他の IP を制御しなければならない場合。この機能はスタンドアロンの FPGA デバイスで特に役に立ちます。
簡易 AXI4 Master プロトコル - 書き込みチャネル
DUT 端子を AXI4 Master インターフェイスにマッピングするには、簡略化された AXI4 Master プロトコルを使用します。実際の AXI4 Master プロトコルをモデル化する必要はありません。代わりに、簡易プロトコルを使用できます。IP Core Generation ワークフローを実行すると、生成された HDL コードに、簡易プロトコルと実際の AXI4 Master プロトコル間で変換されるラッパー ロジックが含まれます。簡易プロトコルでは、必要なプロトコル信号の数が少なく、Valid 信号と Ready 信号間のハンドシェイキング メカニズムが容易になり、任意の長さのバーストがサポートされます。
書き込みトランザクションには簡易 AXI4 Master 書き込みプロトコルを使用します。読み取りトランザクションには簡易 AXI4 Master 読み取りプロトコルを使用します。次の図は AXI4 Master 書き込みトランザクション用に DUT 入力および出力インターフェイスでモデル化した信号のタイミング図を示しています。

DUT は書き込み要求を開始するために wr_ready が High になるのを待ちます。wr_ready が High になると DUT は書き込み要求を送信できます。書き込み要求は Data 信号と Write Master to Slave bus 信号で構成されます。このバスは wr_len、wr_addr および wr_valid で構成されます。wr_addr 信号は DUT が書き込みを行う開始アドレスを指定します。wr_len 信号はこの書き込みトランザクションのデータ要素の数に対応します。Data は wr_valid が High のときに送信できます。wr_ready が Low になると、1 クロック サイクル以内に DUT はデータの送信を停止しなければならず、Data 信号は無効になります。DUT が 1 クロック サイクル以降もデータの送信を続けた場合、データは無視されます。
簡易 AXI4 Master プロトコルではパイプライン化された要求がサポートされます。このプロトコルでは、wr_complete 信号が High になるのを待ってから後続の書き込み要求を発行する必要はありません。このインターフェイスでは、パイプラインが停滞して wr_ready 信号が Low になる前は、最大 16 件のトランザクション (または 16 個のデータ ワード) がサポートされます。
出力信号
DUT 出力インターフェイスの Data 信号と Write Master to Slave bus 信号をモデル化します。
Data:転送するデータ。トランザクションの各サイクルで有効です。Write Master to Slave bus。次で構成されます。wr_addr:書き込みトランザクションの開始アドレス。トランザクションの最初のサイクルでサンプリングされます。アドレスはバイト単位で指定されます。wr_len:転送するデータ値の数。トランザクションの最初のサイクルでサンプリングされます。wr_len信号は語長で指定されます。つまり、wr_lenの各ユニットは完全なデータ要素です。たとえば、wr_lenが2で、データのビット幅が128ビットの場合、2 つの128ビット データ要素が書き込まれます。wr_valid:この制御信号が High になると、出力でサンプリングされたData信号が有効であることを示します。wr_awid(オプション信号): この信号は、単一チャネルを介した複数のストリームを識別するアドレス ID です。wr_awidをマッピングしない場合、生成された IP コアではwr_awidが定数 0 に設定されます。
入力信号
次で構成される Write Slave to Master bus をモデル化します。
wr_complete(オプション信号): 1 クロック サイクルの間 High であった場合に書き込みトランザクションが完了したことを示す制御信号です。データの次のバーストは、wr_completeがアサートした後に送信できます。wr_completeの早期アサーションにより、平均レイテンシが 2 つのバースト間の3クロック サイクルとほぼ同じになり、書き込み操作がパイプライン化されて、書き込みスループットが向上します。wr_ready:この信号はスレーブ IP コアまたは外部メモリからのバック プレッシャーに対応します。この制御信号が High の場合、データが送信可能なことを示します。wr_readyが Low の場合、1 クロック サイクル以内に DUT はデータ送信を停止しなければなりません。また、wr_ready信号を使用して、DUT が最初のバースト信号を送信した直後に 2 番目のバースト信号を送信可能かどうかを判断することもできます。複数のバースト信号がサポートされています。つまりwr_ready信号が High を維持している場合、最初のバーストの最後の要素を受信した直後に 2 番目のバーストを受け取ることができます。wr_readyを使用して次のバーストを開始するタイミングを決定すると、2 つのバースト間の平均レイテンシは、3クロック サイクルよりも少なくなります。wr_bvalid(オプション信号): 診断目的で使用できるスレーブ IP コアからの応答信号です。wr_bvalid信号は、AXI4 相互接続が各バースト トランザクションを受信した後に High になります。wr_lenが256より大きい場合、AXI4 Master の書き込みモジュールは大きなバースト信号を 256 の大きさのバーストに分割します。wr_bvalid信号は 256 の大きさのバーストごとに High になります。wr_bresp(オプション信号): 診断目的で使用できるスレーブ IP コアからの応答信号です。この信号はwr_bvalid信号と共に使用します。wr_bid(オプション信号): この信号は、単一チャネルを介した複数のストリームを識別する書き込み応答 ID です。wr_bidをマッピングしない場合、生成された IP コアではwr_bidが終端処理されます。
AXI4 マスター プロトコルは、最大バースト サイズ 256 をサポートします。バースト サイズが 256 を超える場合、生成された HDL IP コアの AXI Master インターフェイスは、大きいバーストを、サイズが 256 より小さい複数のバーストに分割します。データのバーストが大きい場合でも、書き込みスループットが向上します。
簡易 AXI4 Master プロトコル - 読み取りチャネル
次の図は AXI4 Master 読み取りトランザクション用に DUT 入力および出力インターフェイスでモデル化した信号のタイミング図を示しています。これらの信号には Data、Read Master to Slave Bus および Read Slave to Master Bus が含まれます。

DUT は読み取り要求を開始するために rd_aready が High になるのを待ちます。rd_aready が High になると DUT は読み取り要求を送信できます。読み取り要求は Read Master to Slave bus の rd_addr、rd_len および rd_avalid 信号で構成されます。スレーブ IP または外部メモリは、各クロック サイクルに Data を送信することで読み取り要求に応答します。rd_len 信号は読み取るデータ値の数に対応します。DUT は rd_dvalid が High である間 Data を受信できます。
読み取り要求
DUT 出力インターフェイスでの読み取り要求をモデル化するには、次で構成される Read Master to Slave bus をモデル化します。
rd_addr:読み取りトランザクションの開始アドレス。トランザクションの最初のサイクルにサンプリングされます。アドレスはバイト単位で指定されます。rd_len:読み取るデータ値の数。トランザクションの最初のサイクルにサンプリングされます。rd_len信号は語長で指定されます。つまり、rd_lenの各ユニットは完全なデータ要素です。たとえば、rd_lenが2で、データのビット幅が128ビットの場合、2 つの128ビット データ要素が読み取られます。rd_avalid:読み取り要求が有効かどうかを示す制御信号。rd_arid(オプション信号): この信号は、単一チャネルを介した複数のストリームを識別するアドレス ID です。rd_aridをマッピングしない場合、生成された IP コアではrd_aridが定数 0 に設定されます。
DUT 入力インターフェイスで、新しい読み取り要求をいつ送信するかを示す Ready 信号 rd_aready をモデル化できます。 rd_aready 信号は、DUT が連続する複数のバースト要求を送信できるかどうかを示します。DUT は Ready 信号がアサートされてから 1 クロック サイクル後に新しい要求を送信できます。Ready 信号がデアサートされた後、DUT は読み取り要求をもう 1 つ送信できます。DUT は Ready 信号がデアサートされてから 1 クロック サイクル後は新しい要求を送信できず、要求は無視されます。
簡易 AXI4 Master プロトコルではパイプライン化された要求がサポートされるため、読み取り応答が完了するのを待ってから後続の読み取り要求を発行する必要はありません。このインターフェイスでは、パイプラインが停滞して rd_aready 信号が Low になる前は、最大 4 件の読み取りトランザクションがサポートされます。
読み取り応答
DUT 入力インターフェイスで Data 信号と Read Slave to Master bus 信号をモデル化します。
Data:読み取り要求によって返されるデータ。Read Slave to Master bus。次で構成されます。rd_dvalid:読み取り要求によって返されるDataが有効であることを示す制御信号。rd_rresp(オプション信号): 読み取りトランザクションのステータスを示すスレーブ IP コアからの応答信号。rd_rid(オプション信号): この信号は、単一チャネルを介した複数のストリームを識別するデータ ID です。rd_ridをマッピングしない場合、生成された IP コアではrd_ridが終端処理されます。
DUT 出力インターフェイスでは、オプションで rd_dready 信号を実装できます。この信号は Read Master to Slave bus の一部で、DUT がデータの受信を開始できるタイミングを示します。既定では、この信号を AXI4 Master 読み取りインターフェイスにマッピングしない場合、生成された HDL IP コアでは rd_dready 信号がロジック High に結び付けられます。
ベース アドレス レジスタの計算
生成する IP コアに関して、AXI4 Master の読み取りチャネルと書き込みチャネルの両方をオーサリングするドライバーをサポートするために、HDL Coder にはベース アドレス レジスタが含まれています。ベース アドレス レジスタは DUT ADDR ポートで指定されるアドレスに加算されて AXI4 Master アドレスを形成します。この機能によって、ドライバーはアドレッシング モードを使用できるようになります。このモードではバッファーのベース アドレスを使用して固定のレジスタ アドレスをプログラムします。プログラムされたアドレスは DUT ADDR ポートと共に、バッファーのインデックス付けに使用されます。この機能を使用しない場合、既定ではレジスタは値 0 をとります。

AXI4 マスターの読み取りと書き込みに使用するベース アドレスの初期値の指定
IP Core Generation ワークフローまたは Simulink Real-Time FPGA I/O ワークフローを実行するときに、AXI4 マスター データの読み取りと書き込みに使用するベース アドレス レジスタの初期値を指定できます。既定では、初期値はゼロです。非ゼロの値を指定するには、次を実行します。
ターゲット プラットフォーム インターフェイス テーブルで、入力 DUT 端子を AXI4 マスター読み取りデータ端子にマッピングするか、出力 DUT 端子を AXI4 マスター書き込みデータ端子インターフェイスにマッピングするときに、[Options] ボタンが [Interface Options] 列に表示されます。
[Options] ボタンをクリックしてから、[DefaultReadBaseAddress] または [DefaultWriteBaseAddress] を指定します。
AXI4 Master インターフェイスのモデル化
DUT ポートで Data および AXI4 Master プロトコル信号を使用するアルゴリズムをモデル化し、それらの信号を AXI4 Master インターフェイスにマッピングできます。
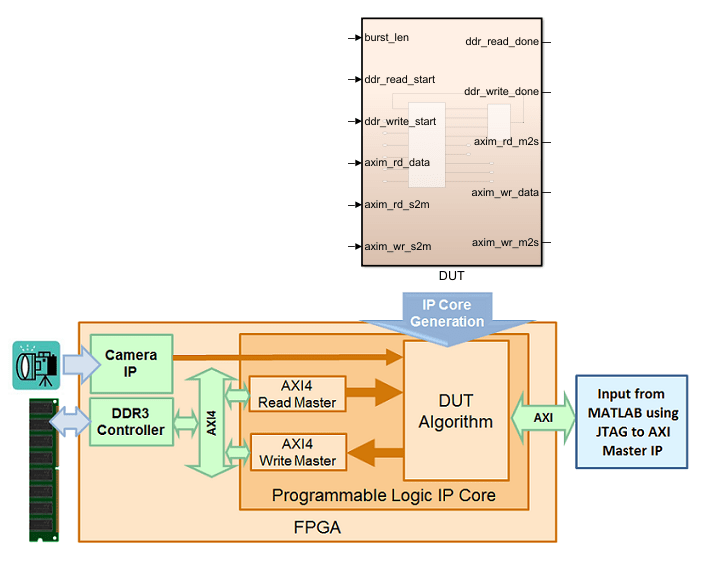
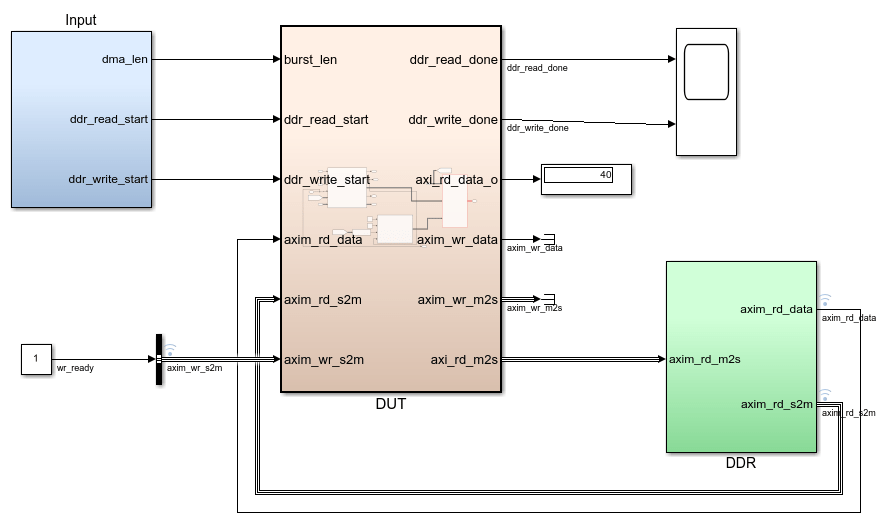
AXI4 Master インターフェイスのマッピングのために DUT アルゴリズムをモデル化する方法について学ぶには、この Simulink® モデルを開きます。DUT サブシステムには、DDR からデータを読み取って DDR メモリの別のアドレスに書き戻す簡単なアルゴリズムが含まれています。
open_system('hdlcoder_axi_master') sim ('hdlcoder_axi_master')
DUT サブシステムを開きます。DDR_Access_Controller サブシステムは AXI Master の読み取りチャネルと書き込みチャネルをモデル化しており、wr_data 信号を計算する Simple Dual Port RAM ブロックが含まれています。DDR_Access_Controller サブシステムをダブルクリックすると、2 つのエッジ検出 Subsystem ブロックが表示されます。これらのブロックは各 MATLAB Function ブロックへの入力として 2 つの開始パルスを生成します。一方のエッジ検出サブシステムと DDR Read Controller MATLAB Function ブロックは読み取りトランザクションをモデル化します。もう一方のエッジ検出サブシステムと DDR Write Controller MATLAB Function ブロックは書き込みトランザクションをモデル化します。この設計を変更し、1 つのエッジ検出サブシステムと対応する MATLAB Function ブロックを使用して、書き込みトランザクションのみまたは読み取りトランザクションのみをモデル化できます。
読み取りチャネル
DDR Read Controller は、INIT、IDLE、READ_BURST_START、および DATA_COUNT の 4 つのステートをもつステート マシンとしてモデル化されます。INIT ステートは読み取り信号と RAM 入力信号を初期化します。開始信号が High になると、ステート マシンは IDLE ステートに切り替わり、rd``_a``ready 信号が High になるのを待ちます。rd``_a``ready が High になるとステート マシンは "READ_BURST_START" ステートに遷移し、DUT はデータの読み取りを開始します。ステート マシンは次に無条件で DATA_COUNT ステートに切り替わり、rd``_a``valid が Low になるまでデータの読み取りを続けます。
書き込みチャネル
DDR Write Controller は、読み取りチャネルと同様に、IDLE、WRITE_BURST_START、DATA_COUNT、および ACK_WAIT の 4 つのステートをもつステート マシンとしてモデル化されます。DUT は IDLE ステートで、次に WRITE_BURST_START ステートに切り替わって wr``_r``eady 信号を待ちます。wr``_r``eady が High になるとステート マシンは DATA_COUNT ステートに切り替わり、データの書き込みを開始します。wr``_v``alid が High の場合、データは有効です。wr``_r``eady が High のときは DUT はデータの書き込みを続けます。wr``_r``eady が Low になるとステート マシンは ACK_WAIT ステートに切り替わり、Ready 信号を待って次の書き込みトランザクションを開始します。
動作している簡易 AXI4 Master プロトコルを確認するには、モデルのシミュレーションを実行します。DSP System Toolbox™ がインストールされている場合は、ロジック アナライザーで結果を表示および解析できます。
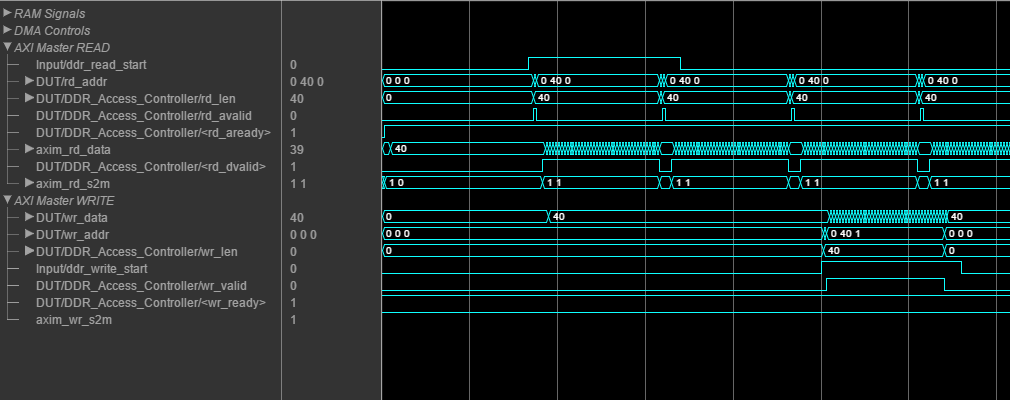
IP コアの生成ワークフローを使用して、AXI4 Master インターフェイスを備えた HDL IP コアを生成できます。HDL Verifier™ がインストールされていて Xilinx® Zynq® ZC706 ボードを使用している場合、IP コアを Default System with External DDR3 Memory Access リファレンス設計に統合できます。
AXI4 Master インターフェイスへのベクトル端子のマッピング
AXI4 Master インターフェイスにベクトル端子をマッピングすると、HDL Coder は生成コードにおいて、ベクトルのすべての要素を組み合わせたビット幅にそれらの要素を連結します。たとえば、128 ビットのベクトルの 4 要素ベクトルは、生成コードでは 512 ビットのデータに連結されます。AXI4 Master インターフェイスは、1024 ビットの最大ビット幅をサポートします。ベクトル端子の組み合わせたビット幅が 1024 ビットを超える場合はエラーになります。
メモ
R2024b より前は、Simulink® でサポートされる固定小数点データ型の語長は最大 128 ビットでした。結果として、生成コードで 128 ビットを超えるビット幅を実現するにはベクトル データ型を使用していました。R2024b 以降では、ビット幅が 128 ビットを超える固定小数点データ型を Simulink で直接モデル化してコードを生成できます。より大きいビット幅を使用することで、外部の DDR メモリにアクセスするときのスループットを高めたり、既存の設計に HDL IP コアを統合するときの要件を満たしたりするのに役立ちます。
たとえば、hdlcoder_axi_master モデルで、axim_rd_data 端子のビット幅を 512 ビットに拡張するには目的の語長のデータ型を指定します。あるいは、ベクトル連結を使用して 512 ビット幅を実現するには、DDR 内の ddr_data パラメーターを fi(([40:-1:1]),0,128,0) に変更してから、128 ビットの入力を 4 回連結します。この方法では、Vector Concatenate ブロックを使用して 512 ビットの出力が生成されます。モデルをシミュレートするには、DUT サブシステム内の Simple Dual Port RAM ブロックを Simple Dual port RAM System ブロックで置き換えます。
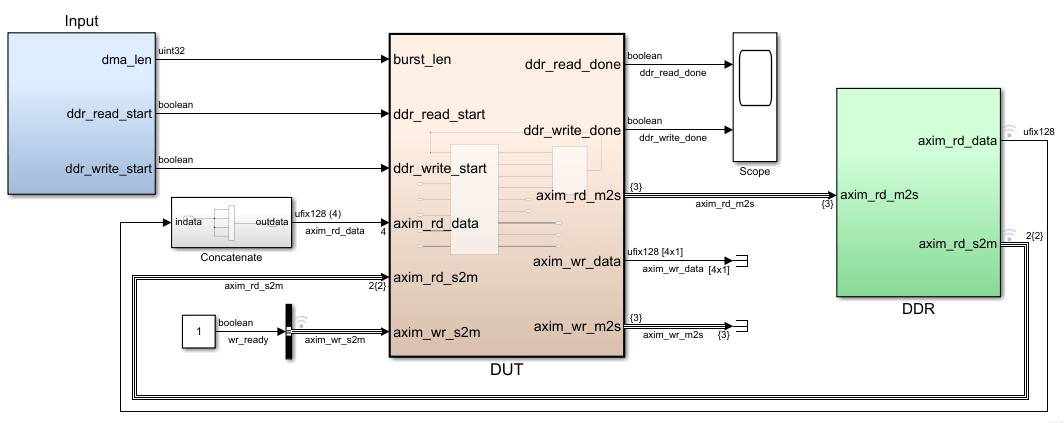
次に、これらの DUT データ端子を [ターゲット プラットフォーム インターフェイス テーブル] の [AXI4 Master Read] 端子または [AXI Master Write] 端子にマッピングし、HDL IP コアを生成して、IP コアを Vivado® または Qsys リファレンス設計に統合します。DUT IP コアに対して生成された HDL コードで、Data 端子は、512 ビットのインターフェイスにマッピングされます。ベクトル入力の各要素に対応する複数の FIFO ブロックが生成されます。
ENTITY DUT_ip IS
PORT( IPCORE_CLK : IN std_logic; -- ufix1
IPCORE_RESETN : IN std_logic; -- ufix1
AXI4_Master_Rd_RDATA : IN std_logic_vector(511 DOWNTO 0); -- ufix256
...
...
AXI4_Master_Wr_WDATA : OUT std_logic_vector(511 DOWNTO 0); -- ufix256
...
);
END DUT_ip;この図は、ベクトル データの書き込みと読み込みが行われる順序を示しています。
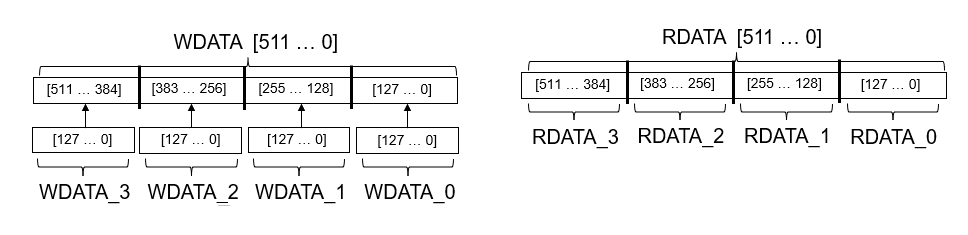
DUT IP コアの HDL コードでは、AXI4_Master_Rd_RDATA および AXI4_master_Wr_WDATA インターフェイスが DUT 端子にマッピングされる方法および AXI4 Master インターフェイスにデータが書き込まれ、読み戻される順序を確認できます。
...
...
--------------------------------------------------------------------
AXI4 Master Read Sequence
--------------------------------------------------------------------
AXI4_Master_Rd_RDATA_0 <= AXI4_Master_Rd_RDATA_unsigned(127 DOWNTO 0);
AXI4_Master_Rd_RDATA_1 <= AXI4_Master_Rd_RDATA_unsigned_1(255 DOWNTO 128);
AXI4_Master_Rd_RDATA_2 <= AXI4_Master_Rd_RDATA_unsigned_7(383 DOWNTO 256);
AXI4_Master_Rd_RDATA_3 <= AXI4_Master_Rd_RDATA_unsigned_7(511 DOWNTO 384);
--------------------------------------------------------------------
AXI4 Master Write Sequence
--------------------------------------------------------------------
AXI4_Master_Wr_WDATA_tmp <= unsigned(AXI4_Master_Wr_WDATA_Vec_3) &
unsigned(AXI4_Master_Wr_WDATA_Vec_2) &
unsigned(AXI4_Master_Wr_WDATA_Vec_1) &
unsigned(AXI4_Master_Wr_WDATA_Vec_0);
AXI4_Master_Wr_WDATA <= std_logic_vector(AXI4_Master_Wr_WDATA_tmp);
...
...
AXI4 Master Data 端子に非標準ビット幅を使用している場合、Data 端子は、より大きいサイズの標準ビット幅コンテナーにアップグレードされます。標準ビット幅は、32、64、128、256、512、および 1024 ビットです。たとえば、4 つの 35 ビット要素をもつベクトルを使用すると、結果のビット幅 140 ビット (35x4) が 256 ビットの AXI4 Master インターフェイスにマッピングされます。書き込みチャネル Data 端子では、255 ~ 141 ビットが 0 でパディングされます。読み取りチャネル Data 端子では、255 ~ 141 ビットは無視されます。

非標準ビット幅を使用すると、AXI4 Master インターフェイス全体が使用されないため、パフォーマンスに影響がある可能性があります。パフォーマンスへの影響を回避するには、標準 AIX ビット幅を使用します。
AXI4 Master インターフェイスの数を減らすための ID 信号のモデル化
IP コアの生成ワークフローで簡易 AXI4 Master プロトコルの ID 信号をモデル化できます。ID 信号は次の目的で使用します。
複数のモジュールで同じ AXI Master インターフェイスを共有する。
順不同のデータの要求を有効にする。ID 信号を使用すると、AXI Master で前の要求が終了するのを待たずに要求を発行できます。
Simulink モデルに必要な AXI4 Master インターフェイスの量を減らす。
書き込みチャネルでは、オプションの信号 wr_awid および wr_bid を使用して ID 信号をモデル化できます。読み取りチャネルでは、オプションの信号 rd_arid および rd_rid を使用して ID 信号をモデル化できます。ID 信号の幅について、次の制限があります。
ID の幅は、最大 32 ビットの符号なし整数でなければなりません。
ID の幅は、同じ AXI4 Master インターフェイスの読み取りチャネルと書き込みチャネルで一致していなければなりません。異なる AXI Master インターフェイスでは ID の幅が異なっていてもかまいません。
DUT に外部メモリへのアクセスを必要とするカーネルが複数ある場合、IP コアの生成時に、DUT 内部の各カーネル インターフェイス用に読み取りと書き込みの AXI マスターを生成できます。これらの AXI マスターはハードウェア リソースを消費し、AXI マスターの数が増えると IP コア全体にクリティカルな遅延が追加されます。

複数のモジュールで同じ AXI Master インターフェイスを共有してハードウェアの消費とクリティカルな遅延を減らすために、ID 信号を使用できます。物理的な ID 信号のモデル化に加え、DUT 内部でアービトレイターをモデル化します。設計のニーズに基づき、処理カーネル数の増加に応じてアービトレイターを拡張できるようにすることができます。
この設計でモデル化されている単純な読み取りのアービトレイターを表示するには、multi_masters_with_ID.slx モデルを開き、DUT サブシステムをダブルクリックします。
複数のサンプルレートを使用した設計のモデル化
HDL Coder ソフトウェアは、IP コアの生成ワークフローの実行時に複数のサンプルレートを使用する設計をサポートします。インターフェイス端子を AXI4 Master インターフェイスにマッピングする場合に複数のサンプルレートを使用するには、これらの AXI4 インターフェイスにマッピングされる DUT 端子が、HDL コード生成後に設計の最速のレートで実行していることを確認します。
詳細については、マルチレート モデルからの IP コアの生成を参照してください。
IP Core Integration のリファレンス設計
生成された HDL IP コアを AXI4 Master インターフェイスとともに、これらの HDL Coder リファレンス設計に統合できます。
Default System with External DDR3 Memory Access:ターゲット プラットフォームがXilinx Zynq ZC706 評価キットのとき。Default System with External DDR4 Memory Access:ターゲットプラットフォームがIntel Arria10 SoC 開発キットのとき。Default system with External LPDDR4 Memory Access:ターゲット プラットフォームがXilinx Versal AI Core シリーズ VCK190 評価キットのとき。
このリファレンス設計を使用するには、HDL Verifier™ がインストールされていなければなりません。次の図は、リファレンス設計アーキテクチャの概要をブロック線図で示しています。

このアーキテクチャで、HDL DUT IP ブロックは IP Core Generation ワークフローから生成された IP コアに対応します。このアーキテクチャのその他のブロックは事前定義されたリファレンス設計を表しており、HDL Verifier によって提供される MATLAB® ベースの JTAG AXI Manager IP で構成されています。ボード上で FPGA 設計を実行した後で、JTAG AXI Manager IP を使用し、MATLAB 内の入力データを使用してオンボードの DDR3 外部メモリを初期化できます。HDL DUT IP コアは AXI4 Master インターフェイス経由で外部メモリから入力データを読み取ります。次に IP コアはアルゴリズムの計算を実施してその結果を AXI4 Master インターフェイス経由で DDR3 メモリに書き込みます。JTAG AXI Manager IP は DDR3 メモリから結果を読み取って MATLAB 内でその結果を検証できます。
hdlcoder.ReferenceDesign クラスの addAXI4MasterInterface メソッドを使用して、IP コアを AXI4 Master インターフェイスとともに、独自のカスタム リファレンス設計に統合できます。
制限
合成ツール:
[Xilinx Vivado]または[Altera QUARTUS II]でなければなりません。[Xilinx ISE]はサポートされていません。ターゲット ワークフロー:
[IP Core Generation]ワークフローを使用します。このワークフローを実行するには、Simulink で DUT アルゴリズムから HDL ワークフロー アドバイザーを開きます。MATLAB から HDL へのワークフローはサポートされていません。プロセッサ/FPGA 同期:
[フリー ラン]モードでなければなりません。