オブジェクト検出器の層の量子化と CUDA コードの生成
この例では、畳み込み層に対して 8 ビット整数で推論計算を実行する SSD 車両検出器および YOLO v2 車両検出器の CUDA® コードを生成する方法を示します。
深層学習は、イメージの特徴を学ぶようにネットワークを訓練し、検出タスクを実行する強力な機械学習手法です。深層学習を使用したオブジェクト検出には、Faster R-CNN、You Only Look Once (YOLO v2)、SSD など、いくつかの方法があります。詳細については、YOLO v2 深層学習を使用したオブジェクトの検出 (Computer Vision Toolbox)とSSD 深層学習を使用したオブジェクト検出 (Computer Vision Toolbox)を参照してください。
深層学習用途で使用されるニューラル ネットワーク アーキテクチャには、畳み込み層を含む多くの処理層が含まれます。深層学習モデルは通常、ラベル付きデータの大量のセットに対して動作します。これらのモデルで推論を実行すると、計算量が多くなり、大量のメモリが消費されます。ニューラル ネットワークでは、入力がネットワーク経由で伝播するときに、各層からの入力データ、パラメーター (重み)、および活性化を保存するためにメモリが使用されます。MATLAB® で学習させた深層ニューラル ネットワークは、単精度浮動小数点データ型を使用します。小規模なネットワークでも、これらの浮動小数点算術演算を実行するには大量のメモリとハードウェアが必要です。このような制限は、計算能力が低く、メモリ リソースが少ない場合にデバイスへの深層学習モデルの展開を妨げる可能性があります。重みと活性化を保存するための精度を下げることによって、ネットワークのメモリ要件を緩和させることができます。
Deep Learning Toolbox™ と Deep Learning Toolbox Model Compression Library サポート パッケージを併用して、畳み込み層の重み、バイアス、および活性化を 8 ビットにスケーリングされた整数データ型に量子化することによって、深層ニューラル ネットワークのメモリ フットプリントを削減できます。その後、GPU Coder™ を使用して、最適化されたネットワークの CUDA コードを生成できます。
事前学習済みのネットワークのダウンロード
学習の完了を待たなくて済むように、事前学習済みのオブジェクト検出器をダウンロードします。
detectorType =  2
2detectorType = 2
switch detectorType case 1 disp('Downloading pretrained detector...'); matFile = matlab.internal.examples.downloadSupportFile("vision","data/ssdResNet50VehicleExample_20a.mat"); case 2 disp('Downloading pretrained detector...'); matFile = matlab.internal.examples.downloadSupportFile("vision","data/yolov2ResNet50VehicleExample_19b.mat"); end
Downloading pretrained detector...
データの読み込み
この例では、295 個のイメージを含んだ小さな車両データ セットを使用します。これらのイメージの多くは、Caltech の Cars 1999 データ セットおよび Cars 2001 データ セットからのものです。Pietro Perona 氏によって作成されたもので、許可を得て使用しています。各イメージには、1 または 2 個のラベル付けされた車両インスタンスが含まれています。小さなデータ セットは学習手順を調べるうえで役立ちますが、実際にロバストな検出器に学習させるにはラベル付けされたイメージがより多く必要になります。車両のイメージを解凍し、車両のグラウンド トゥルース データを読み込みます。
unzip vehicleDatasetImages.zip data = load('vehicleDatasetGroundTruth.mat'); vehicleDataset = data.vehicleDataset;
学習、キャリブレーション、検証のためのデータの準備
学習データは table に保存されています。最初の列には、イメージ ファイルへのパスが含まれています。残りの列には、車両の ROI ラベルが含まれています。データの最初の数行を表示します。
vehicleDataset(1:4,:)
ans=4×2 table
'vehicleImages/image_00001.jpg' [220,136,35,28]
'vehicleImages/image_00002.jpg' [175,126,61,45]
'vehicleImages/image_00003.jpg' [108,120,45,33]
'vehicleImages/image_00004.jpg' [124,112,38,36]
データ セットを学習セット、検証セット、テスト セットに分割します。データの 60% を学習用に、10% をキャリブレーション用に、残りを学習済みの検出器の検証用に選択します。
rng(0); shuffledIndices = randperm(height(vehicleDataset)); idx = floor(0.6 * length(shuffledIndices) ); trainingIdx = 1:idx; trainingDataTbl = vehicleDataset(shuffledIndices(trainingIdx),:); calibrationIdx = idx+1 : idx + 1 + floor(0.1 * length(shuffledIndices) ); calibrationDataTbl = vehicleDataset(shuffledIndices(calibrationIdx),:); validationIdx = calibrationIdx(end)+1 : length(shuffledIndices); validationDataTbl = vehicleDataset(shuffledIndices(validationIdx),:);
imageDatastore および boxLabelDatastore を使用して、学習および評価中にイメージとラベル データを読み込むデータストアを作成します。
imdsTrain = imageDatastore(trainingDataTbl{:,'imageFilename'});
bldsTrain = boxLabelDatastore(trainingDataTbl(:,'vehicle'));
imdsCalibration = imageDatastore(calibrationDataTbl{:,'imageFilename'});
bldsCalibration = boxLabelDatastore(calibrationDataTbl(:,'vehicle'));
imdsValidation = imageDatastore(validationDataTbl{:,'imageFilename'});
bldsValidation = boxLabelDatastore(validationDataTbl(:,'vehicle'));イメージ データストアとボックス ラベル データストアを組み合わせます。
trainingData = combine(imdsTrain,bldsTrain); calibrationData = combine(imdsCalibration,bldsCalibration); validationData = combine(imdsValidation,bldsValidation);
学習イメージとボックス ラベルのうちの 1 つを表示します。
data = read(calibrationData);
I = data{1};
bbox = data{2};
annotatedImage = insertShape(I,'Rectangle',bbox);
annotatedImage = imresize(annotatedImage,2);
figure
imshow(annotatedImage)
ネットワーク パラメーターの定義
例の実行にかかる計算コストを削減するには、ネットワークの実行に必要な最小サイズに対応するネットワーク入力サイズを指定します。
inputSize = []; switch detectorType case 1 inputSize = [300 300 3]; % Minimum size for SSD case 2 inputSize = [224 224 3]; % Minimum size for YOLO v2 end
検出するオブジェクト クラスの数を定義します。
numClasses = width(vehicleDataset)-1;
データ拡張
データ拡張は、学習中に元のデータをランダムに変換してネットワークの精度を高めるために使用されます。データ拡張を使用すると、ラベル付き学習サンプルの数を実際に増やさずに、学習データをさらに多様化させることができます。
変換を使用し、次の方法で学習データを拡張します。
イメージおよび関連するボックス ラベルを水平方向にランダムに反転。
イメージおよび関連するボックス ラベルをランダムにスケーリング。
イメージの色にジッターを付加。
データ拡張はテスト データには適用されないことに注意してください。理想的には、テスト データが元のデータを表し、未変更のままバイアスのない評価となるようにします。
augmentedCalibrationData = transform(calibrationData,@augmentVehicleData);
同じイメージを繰り返し読み取り、拡張された学習データを可視化します。
augmentedData = cell(4,1); for k = 1:4 data = read(augmentedCalibrationData); augmentedData{k} = insertShape(data{1},'Rectangle',data{2}); reset(augmentedCalibrationData); end figure montage(augmentedData,'BorderSize',10)

キャリブレーション データの前処理
拡張済みのキャリブレーション データを前処理して、ネットワークのキャリブレーション用に準備します。
preprocessedCalibrationData = transform(augmentedCalibrationData,@(data)preprocessVehicleData(data,inputSize));
前処理済みのキャリブレーション データを読み取ります。
data = read(preprocessedCalibrationData);
イメージと境界ボックスを表示します。
I = data{1};
bbox = data{2};
annotatedImage = insertShape(I,'Rectangle',bbox);
annotatedImage = imresize(annotatedImage,2);
figure
imshow(annotatedImage)
事前学習済みの検出器の読み込みとテスト
事前学習済みの検出器を読み込みます。
pretrained = load(matFile); detector = pretrained.detector;
迅速なテストとして、1 つのテスト イメージ上で検出器を実行します。
data = read(calibrationData);
I = data{1,1};
I = imresize(I,inputSize(1:2));
[bboxes,scores] = detect(detector,I, 'Threshold', 0.4);結果を表示します。
I = insertObjectAnnotation(I,'rectangle',bboxes,scores);
figure
imshow(I)
浮動小数点ネットワークの検証
大規模なイメージ セットで学習済みのオブジェクト検出器を評価し、パフォーマンスを測定します。関数evaluateObjectDetection (Computer Vision Toolbox)を使用して、平均適合率や対数平均ミス率などのオブジェクト検出器の一般的なメトリクスを測定します。この例では、平均適合率メトリクスを使用してパフォーマンスを評価します。平均適合率は、検出器が正しい分類を実行できること (precision) と検出器がすべての関連オブジェクトを検出できること (recall) を示す単一の数値です。
学習データと同じ前処理変換をテスト データに適用します。データ拡張はテスト データには適用されないことに注意してください。理想的には、テスト データが元のデータを表し、未変更のままバイアスのない評価となるようにします。
preprocessedValidationData = transform(validationData,@(data)preprocessVehicleData(data,inputSize));
すべてのテスト イメージに対して検出器を実行します。
detectionResults = detect(detector, preprocessedValidationData,'Threshold',0.4);平均適合率メトリクスを使用してオブジェクト検出器を評価します。
metrics = evaluateObjectDetection(detectionResults,preprocessedValidationData); ap = averagePrecision(metrics,ClassName="vehicle"); [precision, recall] = precisionRecall(metrics,ClassName="vehicle"); precision = precision{:}; recall = recall{:};
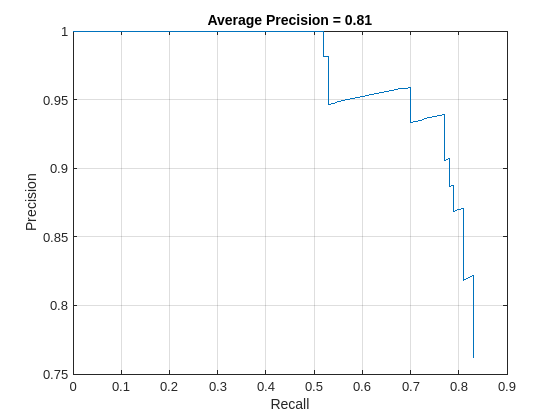
適合率/再現率 (PR) の曲線は、さまざまなレベルの再現率における検出器の適合率を示しています。すべてのレベルの再現率で適合率が 1 になるのが理想的です。より多くのデータを使用すると平均適合率を改善できますが、学習に必要な時間が長くなる場合があります。PR 曲線をプロットします。
figure plot(recall,precision) xlabel('Recall') ylabel('Precision') grid on title(sprintf('Average Precision = %.2f',ap))
ネットワーク用のキャリブレーション結果ファイルの生成
dlquantizer オブジェクトを作成し、量子化する検出器を指定します。既定では、実行環境が GPU に設定されています。検出器を量子化して GPU 環境に展開するために必要な製品の詳細については、量子化ワークフローのシステム要件 (Deep Learning Toolbox)を参照してください。コード生成では関数quantize (Deep Learning Toolbox)によって生成される量子化済みの深層ニューラル ネットワークがサポートされないことに注意してください。
quantObj = dlquantizer(detector)
quantObj =
dlquantizer with properties:
NetworkObject: [1×1 yolov2ObjectDetector]
ExecutionEnvironment: 'GPU'
dlquantizationOptions オブジェクトのメトリクス関数を指定します。
quantOpts = dlquantizationOptions('Target','gpu', ... 'MetricFcn', ... {@(x)hVerifyDetectionResults(x, detector.Network, preprocessedValidationData)});
関数 calibrate を使用して、サンプル入力でネットワークを実行し、範囲情報を収集します。関数 calibrate は、ネットワークを実行し、ネットワークの畳み込み層と全結合層の重みとバイアスのダイナミック レンジに加え、ネットワークのすべての層内の活性化のダイナミック レンジも収集します。この関数はテーブルを返します。テーブルの各行に、最適化されたネットワークの学習可能なパラメーターの範囲情報が含まれています。
calResults = calibrate(quantObj,preprocessedCalibrationData)
calResults=202×5 table
"input_1_Mean" 'input_1' "Mean" 0.4778 0.4899
"conv1_Weights" 'conv1' "Weights" -9.3984 9.5110
"conv1_Bias" 'conv1' "Bias" -2.6468 6.3474
"res2a_branch2a_Weights" 'res2a_branch2a' "Weights" -0.8597 0.3519
"res2a_branch2a_Bias" 'res2a_branch2a' "Bias" -5.0999 5.6429
"res2a_branch2b_Weights" 'res2a_branch2b' "Weights" -0.2490 0.3210
"res2a_branch2b_Bias" 'res2a_branch2b' "Bias" -2.7490 5.1706
"res2a_branch2c_Weights" 'res2a_branch2c' "Weights" -1.6711 1.6394
"res2a_branch2c_Bias" 'res2a_branch2c' "Bias" -6.8159 9.2926
"res2a_branch1_Weights" 'res2a_branch1' "Weights" -2.4565 1.1476
"res2a_branch1_Bias" 'res2a_branch1' "Bias" -5.3913 22.9134
"res2b_branch2a_Weights" 'res2b_branch2a' "Weights" -0.4671 0.3427
"res2b_branch2a_Bias" 'res2b_branch2a' "Bias" -2.9678 3.5533
"res2b_branch2b_Weights" 'res2b_branch2b' "Weights" -0.4287 0.5795
⋮
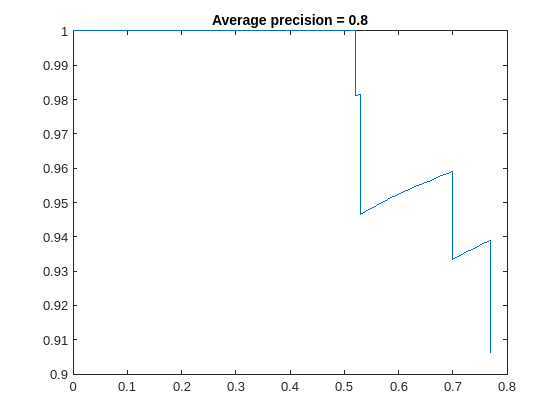
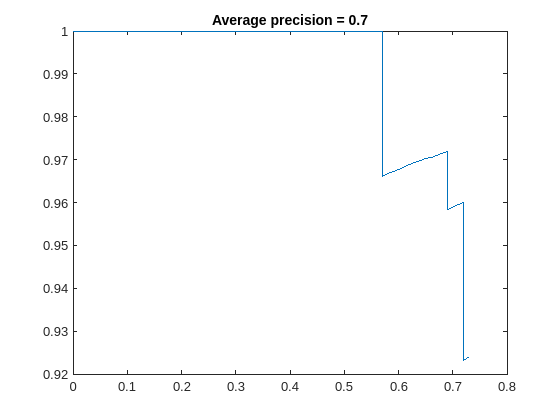
関数 validate を使用して、ネットワークの畳み込み層内の学習可能なパラメーターを量子化し、ネットワークを実行します。この関数は、量子化の前後のネットワークの結果を比較するために dlquantizationOptions オブジェクトで定義されたメトリクス関数を使用します。
valResults = validate(quantObj,preprocessedValidationData,quantOpts)
valResults = struct with fields:
NumSamples: 88
MetricResults: [1×1 struct]
Statistics: [2×2 table]
検証出力の MetricResults.Result フィールドおよび Statistics フィールドを調べ、最適化後のネットワークのパフォーマンスを確認します。各 table の最初の行には、元の浮動小数点実装に関する情報が含まれています。2 行目には、量子化された実装の情報が含まれています。メトリクス関数の出力は、MetricOutput 列に表示されます。
valResults.MetricResults.Result
ans=2×2 table
'Floating-Point' 0.7573
'Quantized' 0.7243
valResults.Statistics
ans=2×2 table
'Floating-Point' 109789888
'Quantized' 27499648
メトリクスは、量子化によって必要なメモリが約 75%、ネットワークの精度が約 3% 低減することを示しています。
キャリブレーション統計を可視化するには、ディープ ネットワーク量子化器アプリを使用します。まず、dlquantizer オブジェクトを保存します。
save('dlquantObj.mat','quantObj')
MATLAB® コマンド ウィンドウで、ディープ ネットワーク量子化器アプリを開きます。
deepNetworkQuantizer
次に、[New]、[Import dlquantizer object] を選択して、ディープ ネットワーク量子化器アプリに dlquantizer オブジェクト dq をインポートします。
CUDA コードの生成
検出器に学習させて評価した後、GPU Coder™ を使用して ssdObjectDetector または yolov2ObjectDetector 用のコードを生成できます。詳細については、シングル ショット マルチボックス検出器を使用したオブジェクト検出のコードの生成 (Computer Vision Toolbox)およびYOLO v2 を使用したオブジェクト検出のコードの生成を参照してください。
MEX 関数を生成するための GPU コード構成オブジェクトを作成します。cuDNN のコード生成パラメーターを指定するには、DeepLearningConfig プロパティを、coder.DeepLearningConfig を使用して作成した coder.CuDNNConfig オブジェクトに設定します。
cfg = coder.gpuConfig('mex'); cfg.TargetLang = 'C++'; cfg.DeepLearningConfig = coder.DeepLearningConfig('cudnn');
GPU の Compute Capability をチェックします。構成オブジェクトで Compute Capability を設定します。
gpuInfo = gpuDevice; cc = gpuInfo.ComputeCapability; cfg.GpuConfig.ComputeCapability = cc;
DataType プロパティを使用することによって、サポートされている層での推論計算の精度を指定します。8 ビット整数精度を使用するには、DataType を 'int8' に設定します。int8 精度を使用するには、CUDA GPU の Compute Capability が 6.1、6.3、またはそれ以上でなければなりません。
cfg.DeepLearningConfig.DataType = 'int8';量子化に使用するキャリブレーション結果ファイルを指定します。
cfg.DeepLearningConfig.CalibrationResultFile = 'dlquantObj.mat';codegen コマンドを実行して CUDA コードを生成します。
codegen -config cfg mynet_detect -args {coder.Constant(matFile), ones(inputSize, 'single')} -report
Code generation successful: View report
コード生成に成功したら、MATLAB コマンド ウィンドウで [レポートの表示] をクリックすることで、結果のコード生成レポートを表示できます。レポートがレポート ビューアー ウィンドウに表示されます。コード生成時にコード ジェネレーターによりエラーまたは警告が検出されると、レポートでは問題が説明され、問題のある MATLAB コードへのリンクが提供されます。コード生成レポートを参照してください。
参考文献
[1] Liu, Wei, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng Yang Fu, and Alexander C. Berg. "SSD: Single Shot Multibox Detector." In Computer Vision - ECCV 2016, edited by Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, 9905:21-37. Cham: Springer International Publishing, 2016. https://doi.org/10.1007/978-3-319-46448-0_2
[2] Redmon, Joseph, and Ali Farhadi. "YOLO9000: Better, Faster, Stronger." In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 6517-25. Honolulu, HI: IEEE, 2017. https://doi.org/10.1109/CVPR.2017.690
参考
アプリ
- ディープ ネットワーク量子化器 (Deep Learning Toolbox)
関数
dlquantizer(Deep Learning Toolbox) |dlquantizationOptions(Deep Learning Toolbox) |calibrate(Deep Learning Toolbox) |validate(Deep Learning Toolbox) |coder.loadDeepLearningNetwork|codegen