パフォーマンス
GPU Coder™ で生成されたコードが予想どおりに実行されない最もよくある理由は、以下のとおりです。
CUDA® カーネルが作成されていない。
ホストからデバイスおよびデバイスからホストへのメモリ転送 (
cudaMemcpy) によってパフォーマンスが抑制されている。並列化不足またはデバイスに問題がある。
このトピックでは、これらの現象の一般的な原因について詳しく説明し、組み込みのスクリーナーを利用してこれらの問題を検出する方法を説明します。また、これらの問題に対処し、より効率的な CUDA コードを生成する方法についての情報も見つけることができます。
アプリ
| GPU Coder | MATLAB コードからの CUDA コードの生成 |
| GPU 環境のチェック | GPU コード生成環境の検証と設定 |
ツール
| GPU パフォーマンス アナライザー | Analyze GPU profiling data and identify optimizations (R2023a 以降) |
関数
オブジェクト
トピック
- コード生成レポート
コード生成レポートを作成して確認する。
- 生成された CUDA コードおよび MATLAB ソース コード間でのトレース
GPU で実行される MATLAB® コードのセクションを強調表示する。
- MATLAB コードから生成されたコードに対する GPU コード メトリクス レポートの作成
GPU 静的コード メトリクス レポートを作成して確認する。
- Analyzing Network Performance Using the Deep Learning Dashboard
Investigate the performance of deep learning networks and layers in generated code using the Deep Learning Dashboard.
- カーネル解析
効率的な CUDA カーネルを生成するための推奨事項。
- メモリ ボトルネック解析
GPU Coder を使用するとメモリ ボトルネックの問題が減る。
- レジスタ カウント nvlink エラー
レジスタ カウント
nvlinkエラーによるコンパイル エラーのトラブルシューティング。 - Improve Performance of GPU Code by Removing Loop Dependencies
Remove loop dependencies to generate GPU kernels for
for- loops. (R2026a 以降) - Identify Function Calls That Prevent Kernel Creation
Identify code that prevents GPU Coder from generating a CUDA kernel for a loop. (R2026a 以降)
- Optimize Kernels That Contain Loops
Rewrite loops in MATLAB to avoid generated code kernels that contain loops.
- Prevent Kernel Launches Inside Loops
Parallelize loops that launch kernels to execute them on the GPU.
- Minimize Memory Copy Events in Generated Code Loops
Rewrite loops to minimize the number of data transfers between the CPU and GPU in generated CUDA code.
注目の例

Pass GPU Inputs to Entry-Point Functions
Generate code that receives data from the GPU to avoid unnecessary memory copies.

Profile Generated CUDA MEX Functions Using Performance Analyzer
Visualize code metrics and identify optimization and tuning opportunities in generated CUDA MEX.
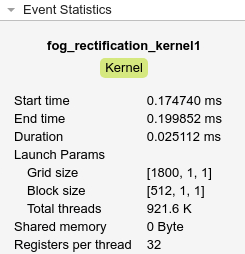
CUDA 生成コードのパフォーマンス解析
この例では、関数 gpuPerformanceAnalyzer を使用して、CUDA® 生成コードのパフォーマンスを解析して最適化する方法を示します。

NVIDIA Jetson プラットフォームでの GPU プロファイリング
Jetson™ プラットフォームで生成された CUDA コードのパフォーマンスを解析して最適化する。

深層学習ネットワーク用の生成コードのパフォーマンス解析
深層学習ネットワーク用に生成された CUDA コードのパフォーマンスを解析して最適化する。